 什么是字節序?字節序重要嗎?
什么是字節序?字節序重要嗎?
那是 1981 年(是的——將近 40 年前!),我們正在構建一個系統,其中包含一個 DEC PDP-11 小型計算機,該小型計算機通過共享內存與德克薩斯 TMS990 微處理器接口。這些都是 16 位處理器,所以我們將數據作為字傳遞。但是發生了一些奇怪的事情:一個 CPU 會將一個值寫入共享內存的一個字中,但是當另一個 CPU 讀出它時,字節被交換了。解決這個問題很簡單:只需在一側編寫一個簡單的訪問例程來交換字節并確保它始終用于訪問共享內存。直到后來才知道為什么會出現這個問題。
在幾乎所有現代嵌入式系統中,內存都是按字節組織的。但是,CPU 也可以將數據處理為 16 位或 32 位字。在這種情況下,需要決定如何將字中的字節存儲在內存中。有兩個明顯的選項和許多其他變體。描述此字節順序的屬性稱為“字節順序”(或有時稱為“字節順序”)。
兩種常見的字節序形式是:最低有效字節存儲在最低地址(“little-endian”)和最高有效字節存儲在最低地址(“big-endian”)。字節順序還有其他變化,甚至還有存儲位的可能性。
廣義上講,使用的字節序是由 CPU 決定的。由于有多種選擇,因此不同的半導體供應商為其 CPU 選擇不同的字節序也就不足為奇了。英特爾 CPU 傳統上是小端的。飛思卡爾傾向于支持大端。大多數現代 CPU 的字節序可以在軟件中交換。
從嵌入式軟件工程師的角度來看,問題是“字節序重要嗎?” 并且,“如果有,多少錢?”
當軟件開發人員需要考慮字節順序時,大致有兩種情況:
在軟件中以多種表示形式處理的數據
前一種情況非常簡單——只需遵循或定義協議即可。后者更棘手,需要一些思考。
考慮這段代碼:
unsigned int n = 0x0a0b0c0d;
unsigned char c, d, *p;
c = (unsigned char) n;
p = (unsigned char *) &n;
d = *p;
c和d最后會包含什么值?無論字節順序如何,c 都應該包含值 0x0 d。但是,d的值將取決于字節序。在小端系統上d 將包含 0x0 d;在 big-endian 上,它將具有值0x0a。如果要在n 和unsigned char a之間進行聯合,則會觀察到同樣的效果。
那么,這有關系嗎?這么多年前,這對我很重要!但是,請注意,大多數代碼可能會獨立于字節順序而編寫,我認為幾乎所有編寫良好的代碼都是這樣的。但是,如果您確實像我需要的那樣構建了字節順序依賴項,那么良好的文檔和注釋是必不可少的。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19409瀏覽量
231191 -
cpu
+關注
關注
68文章
10905瀏覽量
213030
發布評論請先 登錄
相關推薦
快訊:字節跳動否認120億美元投資AI
字節跳動豆包大模型1.5 Pro發布
字節跳動否認與中興通訊合作傳聞
四種方法教你判斷設備的字節序
探索字節隊列的魔法:多類型支持、函數重載與線程安全

字節跳動自研視頻生成模型Seaweed開放
字節跳動計劃在歐洲設立AI研發中心
字節跳動否認與臺積電合作AI芯片
字節跳動回應要進軍手機市場
字節跳動否認AI手機研發項目
字節跳動:未出售TikTok,將持續創新投資
OpenHarmony語言基礎類庫【@ohos.buffer (Buffer)】
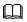
Linux網絡編程





 工商網監
工商網監
評論