 機器學習技術的理論背景及可用神經網絡類型
機器學習技術的理論背景及可用神經網絡類型
在這三部分系列的第一部分中,作者調查了機器學習技術在高度自動化駕駛場景中的驅動因素和潛在應用。第二部分定義了機器學習技術的理論背景,以及汽車開發人員可用的神經網絡類型。第三部分在功能安全要求的背景下評估這些選項。
機器學習可以定義為一組有助于基于過去學習進行預測的算法。
在機器學習算法中,輸入數據被組織為數據點。每個數據點都由描述所表示數據的特征組成。例如,大小和速度是可以區分汽車和街上自行車的特征。汽車的尺寸和速度通常都高于自行車。機器學習方法的目標是將輸入數據轉換為有意義的輸出,例如將輸入數據分類為汽車和非汽車數據點或對象。輸入通常寫成 vector x,由幾個數據點組成。輸出寫為y。
二維或三維輸入數據可以在所謂的特征空間中進行說明和查看,其中每個數據點x都相對于其特征進行繪制。圖 8 (a) 顯示了描述汽車和非汽車對象的二維特征空間的簡化示例。
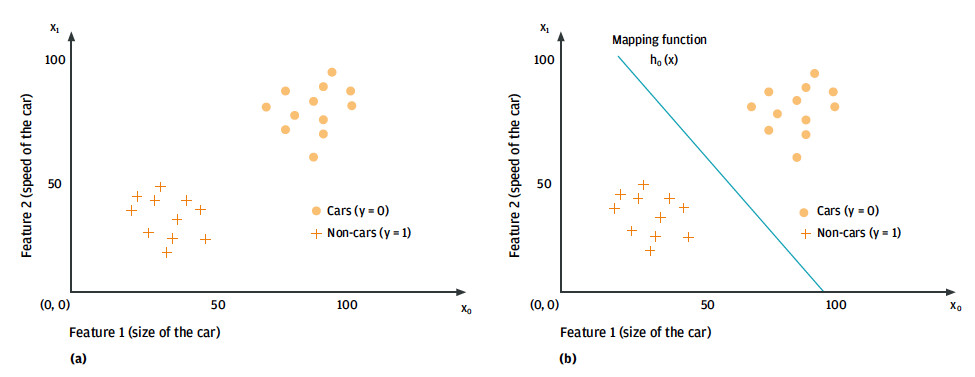
圖 8. 根據大小和速度對汽車和非汽車對象進行分類:特征空間 (a) 和兩個類別之間的相應分離 (b)。
所謂的學習映射函數 或model,h_θ (x)給出了特征向量之間的差異(例如,分類為汽車和非汽車數據點)。模型的結構范圍從簡單的線性函數,例如圖 8 (a) 中劃分汽車和非汽車對象的線,到復雜的非線性神經網絡。學習方法的目標是確定系數的值,這些θ-系數從可用的輸入數據中表示模型的參數。映射函數的輸出是算法對輸入數據描述的預測。
機器學習方法可以根據映射函數的學習方式進行分類(圖 9)。有三種可能:
監督學習—— 映射函數是根據訓練數據對計算的,其中y預先知道的輸出在訓練階段分別提供給學習算法。一旦計算了模型的參數,就可以將模型部署到目標應用程序中。它的輸出——當它接收到一個未知的數據點時——將是 的預測值y。
無監督學習—— 在這種情況下,與監督學習相比,在訓練階段沒有可用的特征標簽對。學習算法的輸入僅包含未標記的數據點。這種機器學習方法的目標是x直接從特征空間中的分布推斷輸入特征的標簽。
強化(半監督)學習—— 在這種情況下,訓練數據也沒有標簽,但模型的構建是為了通過一組動作促進與環境的交互。映射函數將環境狀態映射到由輸入數據給出的動作。獎勵信號表示在特定環境狀態下執行的操作。當信號表示積極影響時,學習算法會加強行動。如果識別出負面影響,該算法將阻止環境的特定動作或狀態。
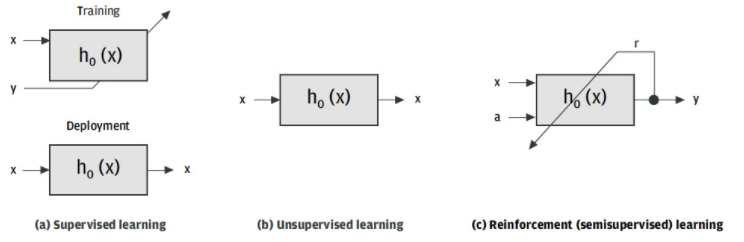
圖 9.基于訓練方法的機器學習算法分類。
深度學習革命
近年來,所謂的深度學習范式徹底改變了機器學習領域。深度學習通過解決以前傳統模式識別方法無法解決的挑戰,對機器學習社區產生了巨大影響(LeCun 等人,2015 年)。深度學習的引入極大地提高了為視覺識別、對象檢測、語音識別、異常檢測或基因組學設計的系統的精度。深度學習的關鍵方面是用于解釋數據的特征是從訓練數據中自動學習的,而不是由工程師手動制作的。
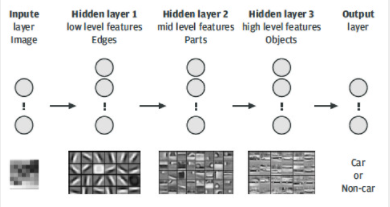
圖 10.訓練識別圖像中汽車的深度卷積神經網絡。
到目前為止,構建一個好的模式識別算法的主要挑戰是手工設計的用于分類的特征向量,例如在第 1 部分中描述的早期版本的交通標志識別系統中使用的局部二進制模式。 深度學習的出現已經用可以自動發現原始輸入數據中重要特征的學習算法取代了特征向量的手動工程。
在架構上,深度學習系統由多層非線性單元組成,可以將原始輸入數據轉換為更高層次的抽象。每一層都將前一層的輸出映射成更復雜的表示,適合回歸或分類任務。這種學習通常在使用反向傳播算法訓練的深度神經網絡上進行。該算法迭代地調整網絡的參數或權重,以模擬輸入的訓練數據。因此,網絡在訓練結束時已經學習了輸入數據點的復雜非線性映射函數。
圖 10 顯示了一個深度神經網絡的符號表示,該網絡經過訓練可以識別圖像中的汽車。輸入層表示原始輸入像素。隱藏層 1 通常模擬圖像的某些位置和方向是否存在邊緣。第二個隱藏層使用在前一層中計算的邊緣對對象部件進行建模。第三個隱藏層構建了建模對象的抽象表示,在我們的例子中,這就是汽車的成像方式。輸出層根據第三個隱藏層的高級特征計算給定圖像包含汽車的概率。
不同的網絡架構源于神經網絡的單元和層的分布方式。所謂感知器是最簡單的,由單個輸出神經元組成。通過建立在感知器上可以獲得大量的神經網絡風味。這些網絡中的每一個都比其他網絡更適合特定的應用程序。圖 11 顯示了近年來創建的眾多神經網絡架構中最常見的三種。
深度前饋神經網絡(圖 11a)是一種結構,其中兩個相鄰層之間的神經元完全互連,信息流僅在一個方向上,從系統的輸入到輸出。這些網絡可用作通用分類器,并用作所有其他類型的深度神經系統的基礎。
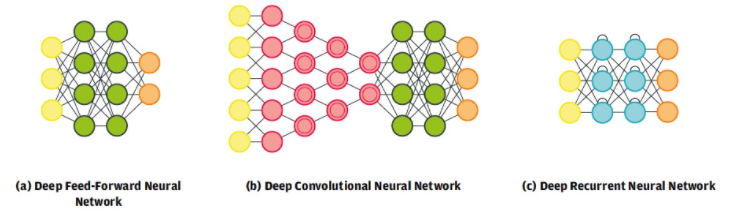
圖 11.深度神經網絡架構
深度卷積神經網絡(圖 11b)改變了視覺感知方法的開發方式。這種網絡由交替的卷積層和池化層組成,它們通過從輸入數據中進行泛化來自動學習對象特征。這些學習到的特征被傳遞到一個完全互連的前饋網絡進行分類。這種類型的卷積網絡是圖 10 所示的汽車檢測架構和第1 部分中描述的用例的基礎。
雖然深度卷積網絡對視覺識別至關重要,但深度遞歸神經網絡(圖 11c)對于自然語言處理至關重要。由于隱藏層中神經元之間的自遞歸連接,此類架構中的信息是時間相關的。網絡的輸出可能會根據數據輸入網絡的順序而有所不同。例如,如果在單詞“mouse”之前輸入單詞“cat”,則會獲得某個輸出。現在,如果輸入順序改變,輸出順序也可能改變。
機器學習算法的類型
盡管深度神經網絡是復雜機器學習挑戰中最常用的解決方案之一,但還有各種其他類型的機器學習算法可用。表 1 根據它們的性質(連續或離散)和訓練類型(監督或無監督)對它們進行分類。
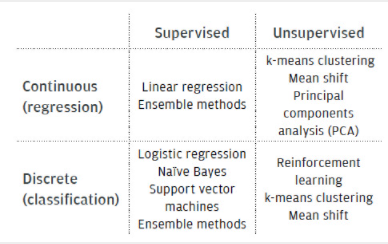
表 1. 機器學習算法的類型
機器學習估計器可以根據其輸出值或訓練方法進行粗略分類。如果后者估計連續值函數(即連續輸出),則該算法被歸類為回歸估計器。機器學習算法在其輸出為離散變量時稱為分類器。第1 部分中描述的交通標志檢測和識別系統是此類算法的一種實現。y
? Ry ? {0,1,…,q}
異常檢測是無監督學習的一種特殊應用。這里的目標是識別數據集中的異常值或異常。異常值被定義為與應用程序中常見的特征向量相比具有不同屬性的特征向量。換句話說,它們在特征空間中占據不同的位置。
表 1 還列出了一些流行的機器學習算法。這些將在下面簡要說明。
線性回歸是一種用于將線、平面或超平面擬合到數據集的回歸方法。擬合模型是一個線性函數,可用于對實值函數進行預測y。
邏輯回歸是線性回歸方法的離散對應物,其中將映射函數給出的預測實數值轉換為概率輸出,表示輸入數據點屬于某個類別。
樸素貝葉斯分類器是一套建立在貝葉斯定理基礎上的機器學習方法,它假設每個特征都獨立于其他特征。
支持 向量機 (SVM)旨在使用所謂的邊距計算類之間的分離。邊距被計算為盡可能寬,以便盡可能清楚地分開類。
集成方法,如決策樹、隨機森林或AdaBoost組合了 一組基分類器,有時稱為“弱”學習器,目的是獲得“強”分類器。
神經網絡是機器學習算法,其中回歸或分類問題由一組稱為神經元的互連單元解決。本質上,神經網絡試圖模仿人腦的功能。
k-means 聚類是一種用于將具有共同屬性的特征組合在一起的方法,即它們在特征空間中彼此接近。k-means 根據給定的集群數量迭代地將共同特征分組到球形集群中。
Mean-shift也是一種數據聚類技術,它對于異常值更通用和穩健。與 k-means 不同,mean-shift 只需要一個調整參數(搜索窗口大小),并且不假定數據簇的先驗形狀為球形。
主成分分析 (PCA)是一種數據降維技術,它將一組可能相關的特征轉換為一組稱為主成分的線性不相關變量。主成分按方差順序排列。第一個組件具有最高的變化;第二個在此之下有下一個變化,依此類推。
第三部分在功能安全要求的背景下評估這些機器學習算法。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101171 -
機器學習
+關注
關注
66文章
8438瀏覽量
133086
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用

神經網絡教程(李亞非)
labview BP神經網絡的實現
基于賽靈思FPGA的卷積神經網絡實現設計
神經網絡結構搜索有什么優勢?
【AI學習】第3篇--人工神經網絡
卷積神經網絡模型發展及應用
卷積神經網絡簡介:什么是機器學習?
為什么使用機器學習和神經網絡以及需要了解的八種神經網絡結構





 工商網監
工商網監
評論