") 什么是張量處理單元(TPU)
什么是張量處理單元(TPU)
介紹
張量處理單元( Tensor Processing Unit, TPU ) 是谷歌專門為神經(jīng)網(wǎng)絡(luò)機(jī)器學(xué)習(xí)開發(fā)的人工智能加速器 專用集成電路(ASIC) ,特別是使用谷歌自己的TensorFlow軟件。谷歌于 2015 年開始在內(nèi)部使用 TPU,并于 2018 年將它們作為其云基礎(chǔ)設(shè)施的一部分并通過提供較小版本的芯片出售給第三方使用。
張量處理單元于 2016 年 5 月在Google I/O上宣布:當(dāng)時該公司表示 TPU 已經(jīng)在其數(shù)據(jù)中心內(nèi)使用了一年多。該芯片專為 Google 的TensorFlow框架設(shè)計,用于神經(jīng)網(wǎng)絡(luò)等機(jī)器學(xué)習(xí)應(yīng)用。
與圖形處理單元相比,它設(shè)計用于大量低精度計算(例如低至8 位精度) ,每焦耳有更多的輸入/輸出操作,無需用于光柵化/紋理映射的硬件。根據(jù)Norman Jouppi的說法, TPU ASIC安裝在散熱器組件中,該組件可以安裝在數(shù)據(jù)中心機(jī)架內(nèi)的硬盤驅(qū)動器插槽中。不同類型的處理器適合不同類型的機(jī)器學(xué)習(xí)模型,TPU 非常適合CNN而 GPU 對一些全連接的神經(jīng)網(wǎng)絡(luò)有長處,而 CPU 對RNN有長處。
經(jīng)過幾年的發(fā)展,TPU已經(jīng)發(fā)布了四個版本,下面是其發(fā)展歷程:
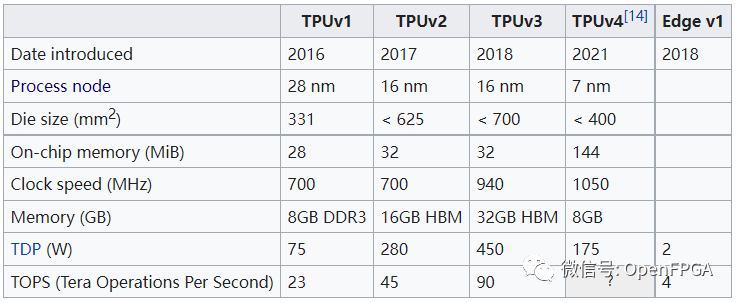
詳細(xì)介紹:<【科普】什么是TPU?>
接下來介紹一些TPU項目。
tinyTPU
?
https://github.com/jofrfu/tinyTPU
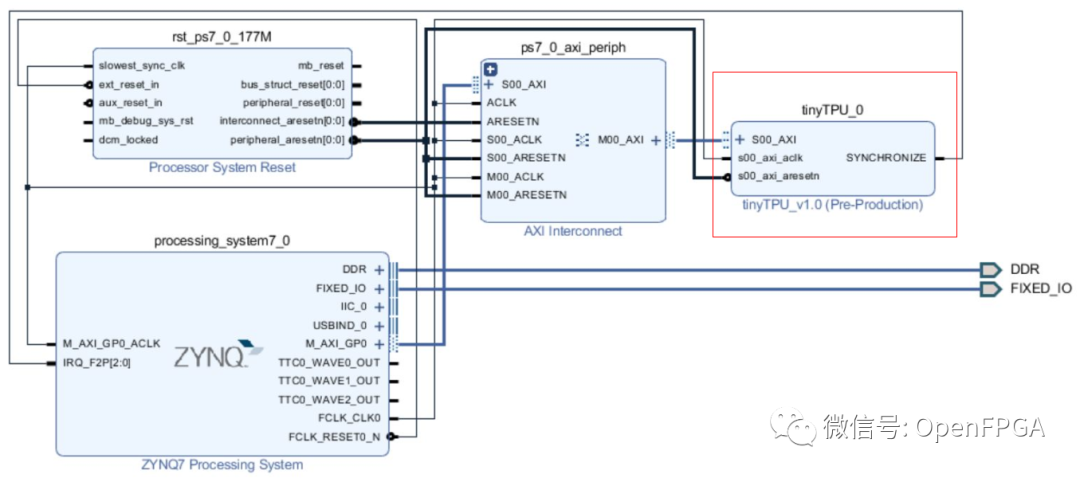
該項目的目的是創(chuàng)建一個與谷歌的張量處理單元具有相似架構(gòu)的機(jī)器學(xué)習(xí)協(xié)處理器。該實現(xiàn)的資源可定制,可以以不同的尺寸使用以適應(yīng)每種類型的 FPGA。這允許在嵌入式系統(tǒng)和物聯(lián)網(wǎng)設(shè)備中部署該協(xié)處理器,但也可以擴(kuò)大規(guī)模以用于數(shù)據(jù)中心和高性能機(jī)器。AXI 接口允許以多種組合方式使用。對 Xilinx Zynq 7020 SoC 進(jìn)行了評估。下面的鏈接中是使用vivado進(jìn)行使用的一個DEMO:
?
https://github.com/jofrfu/tinyTPU/blob/master/getting_started.pdf
同時,該項目也是一片論文的驗證項目,論文地址:
?
https://reposit.haw-hamburg.de/bitstream/20.500.12738/8527/1/thesis.pdf
性能
使用 MNIST 數(shù)據(jù)集訓(xùn)練的樣本模型在不同大小的 MXU 上進(jìn)行了評估,頻率為 177.77 MHz,理論性能高達(dá) 72.18 GOPS。然后將實際時序測量與傳統(tǒng)處理器進(jìn)行比較:
177.77 MHz 的張量處理單元:
| Matrix Width N | 6 | 8 | 10 | 12 | 14 |
|---|---|---|---|---|---|
| Instruction Count | 431 | 326 | 261 | 216 | 186 |
| Duration in us (N input vectors) | 383 | 289 | 234 | 194 | 165 |
| Duration per input vector in us | 63 | 36 | 23 | 16 | 11 |
下面是其他處理器的對比結(jié)果:
| Processor | Intel Core i5-5287U at 2.9 GHz | BCM2837 4x ARM Cortex-A53 at 1.2 GHz |
|---|---|---|
| Duration per input vector in us | 62 | 763 |
Free-TPU
?
https://github.com/embedeep/Free-TPU

編譯好的BOOTbin,因為TPU和引腳沒關(guān)聯(lián),所以可以直接進(jìn)行使用驗證。
?
https://github.com/embedeep/Free-TPU-OS
描述
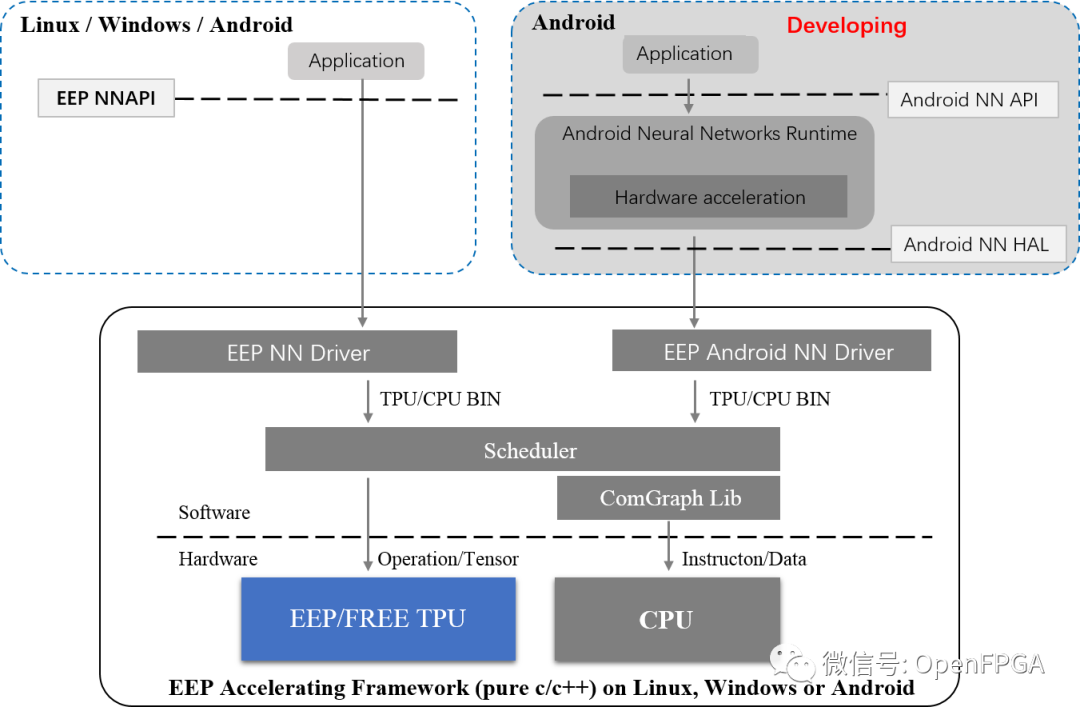
Free TPU是用于深度學(xué)習(xí) EDGE 推理的商業(yè) TPU 設(shè)計的免費版本,可以部署在任何 FPGA 設(shè)備上,包括 Xilinx Zynq-7020 或 Kintex7-160T(這兩個都是生產(chǎn)的好選擇)。實際上,不僅是 TPU 邏輯設(shè)計, Free TPU還包括支持所有 caffe 層的 EEP 加速框架,可以在任何 CPU 上運行(如 Zynq-7020 的 ARM A9 或 INTEL/AMD)。TPU 和 CPU 在深度學(xué)習(xí)推理框架的計劃下相互協(xié)作(任何交替順序)。
系統(tǒng)結(jié)構(gòu)
對比
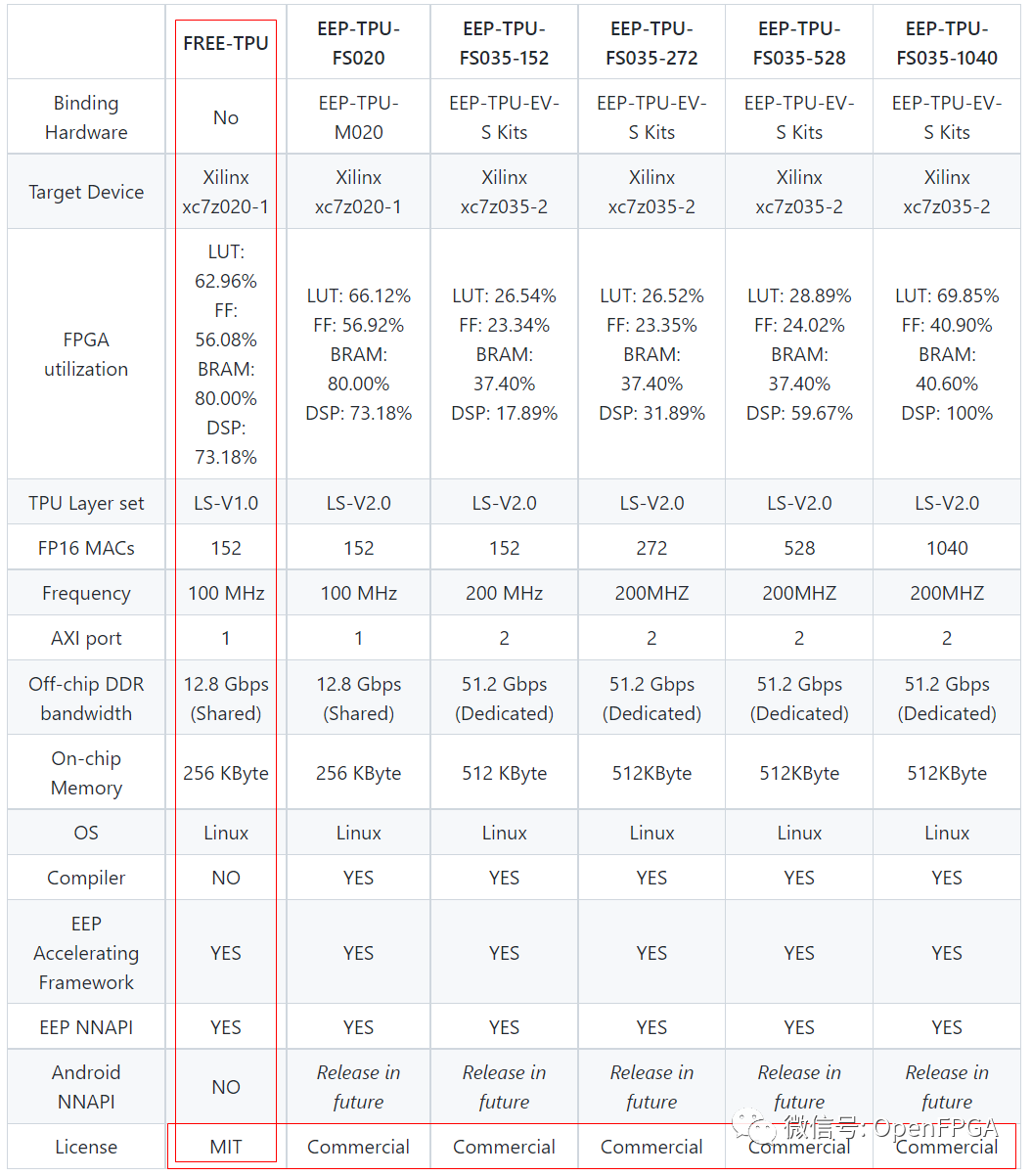
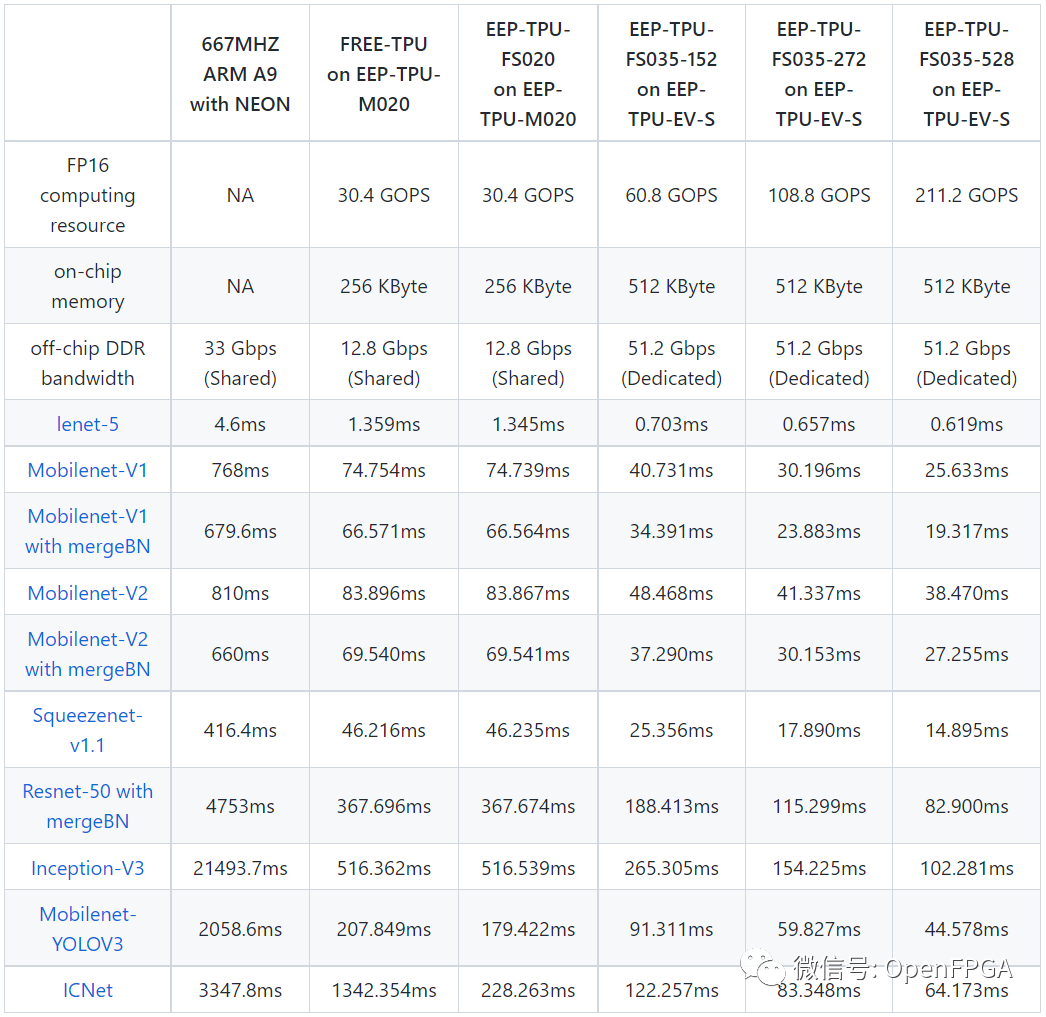
在用戶看來,F(xiàn)ree-TPU和EEP-TPU功能相同,但推理時間不同。
這是一個極其完整的項目,關(guān)于怎么運行,怎么調(diào)用都有很詳細(xì)的步驟,這里就不再贅述了,更多詳情,請訪問:
?
https://www.embedeep.com
SimpleTPU
?
https://github.com/cea-wind/SimpleTPU
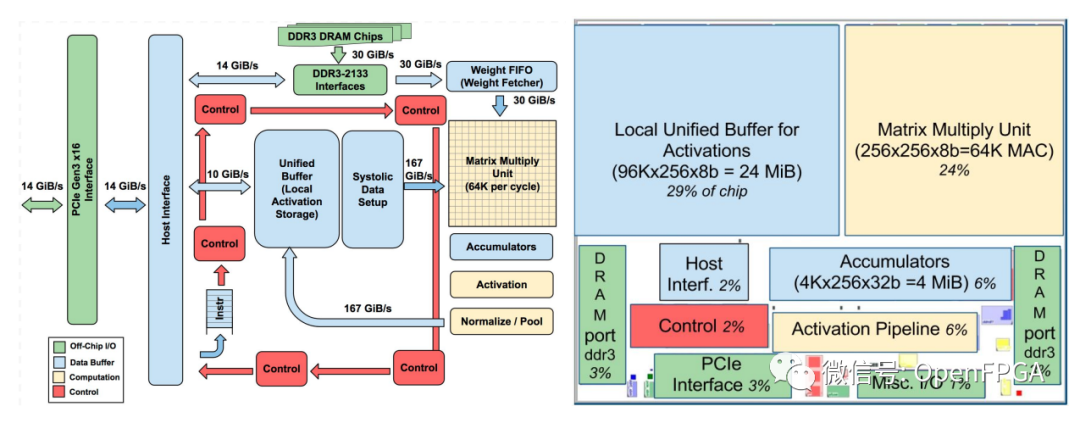
張量處理單元旨在加速矩陣乘法,特別是對于多層感知器和卷積神經(jīng)網(wǎng)絡(luò)。
此實現(xiàn)主要遵循 Google TPU Version 1,該架構(gòu)在
?
https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
中有介紹。
主要特點
Simple TPU 的主要特性包括
Int8 乘法和 Int32 累加器
基于 VLIW 的并行指令
基于向量架構(gòu)的數(shù)據(jù)并行
以下是 Simple TPU 可以支持的一些操作。
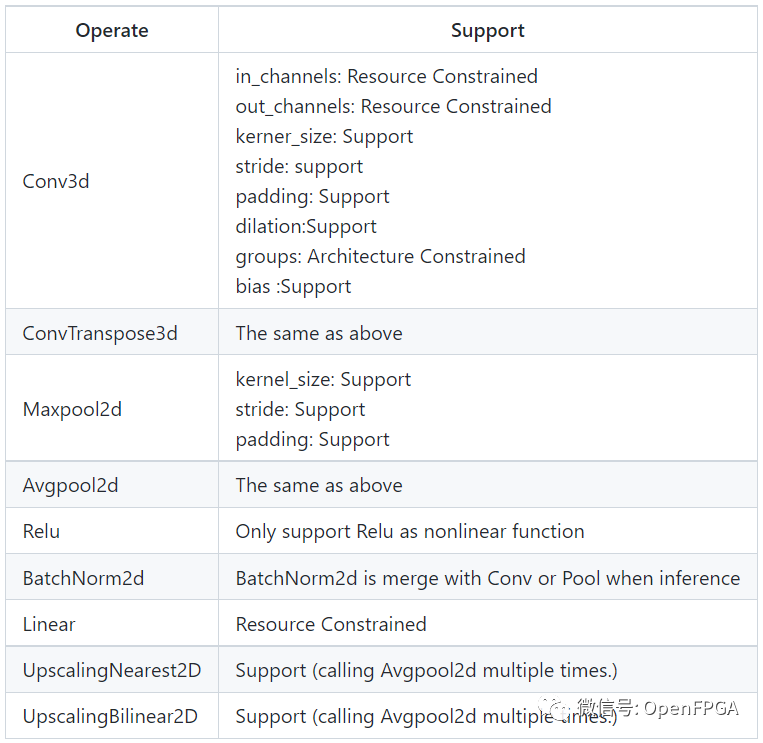
資源占用情況
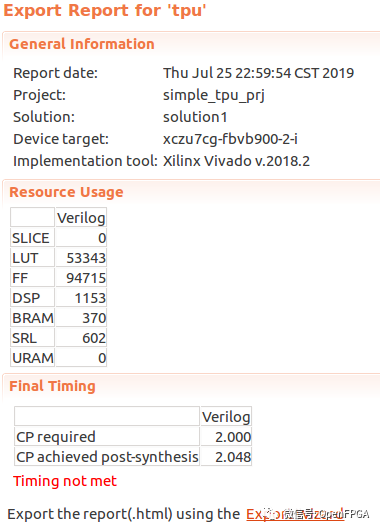
雖然該工程比較完整,后續(xù)也有DEMO演示,但是該工程使用HLS制作的,詳細(xì)信息可以查看下面的網(wǎng)址
?
https://www.cnblogs.com/sea-wind/p/10993958.html
tiny-tpu
?
https://github.com/cameronshinn/tiny-tpu
谷歌的TPU架構(gòu):
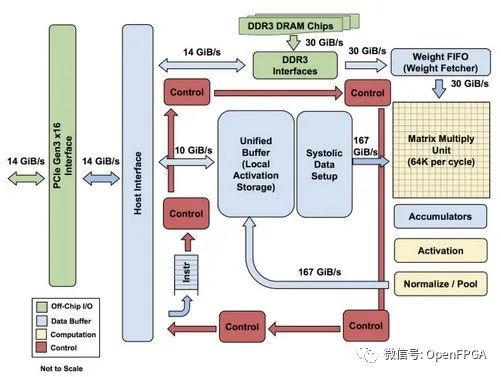

Tiny TPU是基于 FPGA 的 Google張量處理單元的小規(guī)模實現(xiàn)。該項目的目標(biāo)是了解加速器設(shè)計從硬件到軟件的端到端技術(shù),同時破譯谷歌專有技術(shù)的低層次復(fù)雜性。在此過程中,我們探索了小規(guī)模、低功耗 TPU 的可能性。
該項目在 Quartus 15.0 上綜合并編程到 Altera DE1-SoC FPGA 上。
更多詳細(xì)信息:
?
https://github.com/cameronshinn/tiny-tpu/blob/master/docs/report/report.pdf
TPU-Tensor-Processing-Unit
?
https://github.com/leo47007/TPU-Tensor-Processing-Unit
介紹
在有兩個矩陣需要做矩陣乘法的場景下,矩陣A(選擇權(quán)重矩陣)與矩陣B(選擇矩陣)相,每一個一個都是 32x32。最后他們開始做每個矩陣的乘法,每個矩陣的因素將首先轉(zhuǎn)換成一個順序輸入 TPU 中,輸入其特定的矩陣,然后再將這些單元最多向連接的方向輸入。在下一個周期中,每個單元將其權(quán)重和數(shù)據(jù)方向賦予下一個格。從左到右。
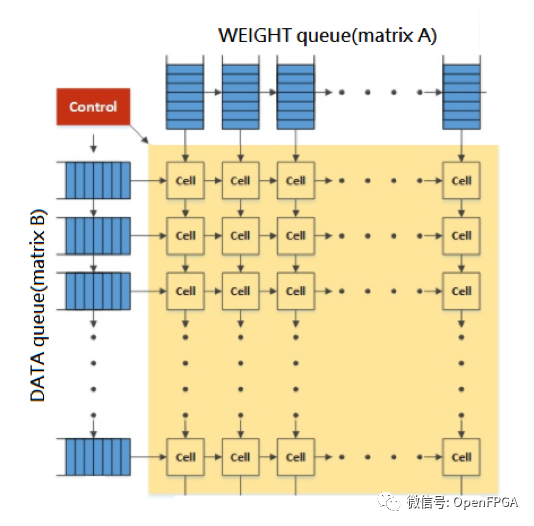
因為這個項目有中文的詳細(xì)介紹,所以就不過多贅述了。
?
https://zhuanlan.zhihu.com/p/26522315
Systolic-array-implementation-in-RTL-for-TPU
?
https://github.com/abdelazeem201/Systolic-array-implementation-in-RTL-for-TPU
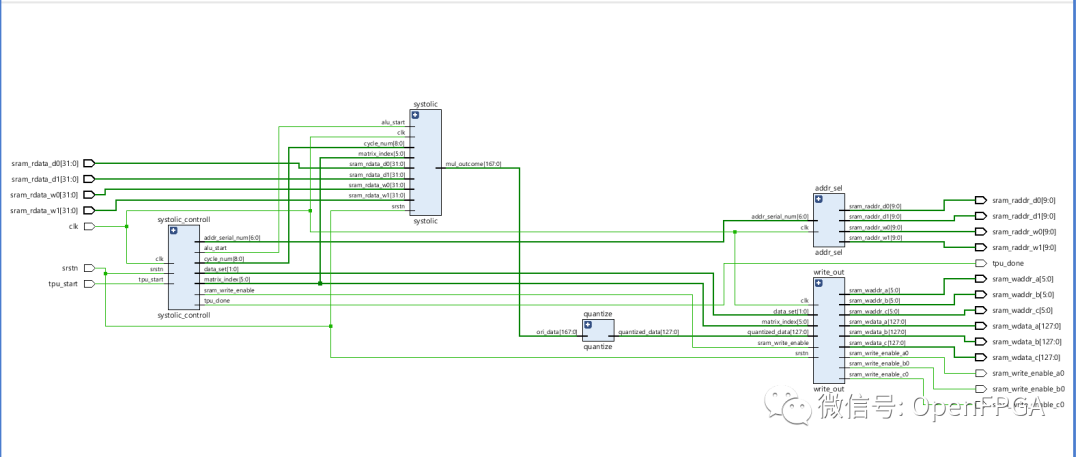
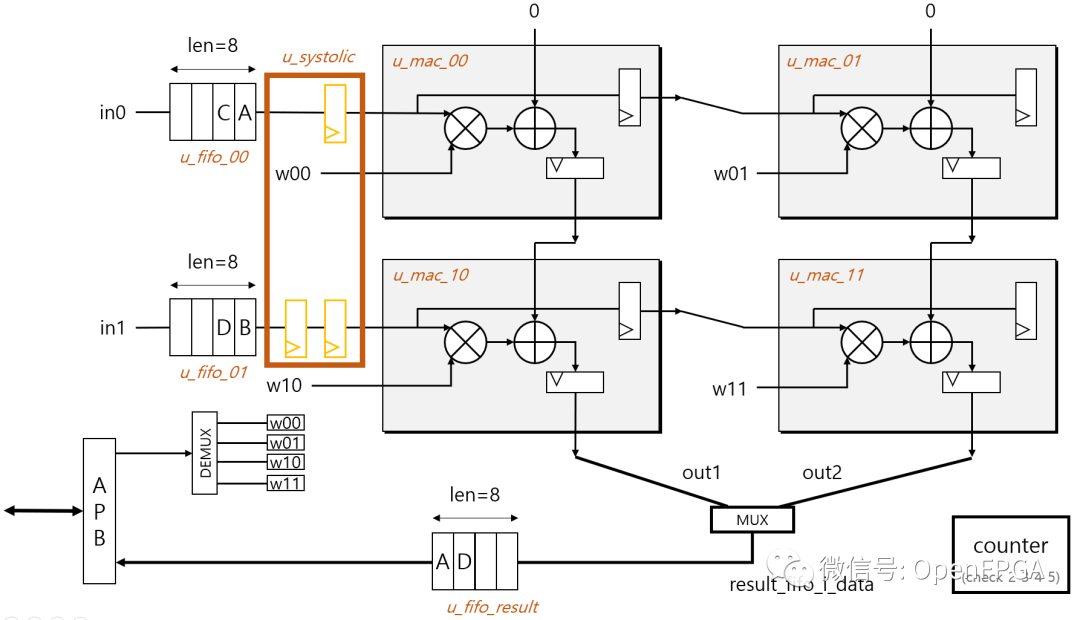
如下圖所示,在有兩個矩陣需要做矩陣乘法的場景下,矩陣A(命名權(quán)重矩陣)與矩陣B(命名數(shù)據(jù)矩陣)相乘,每個矩陣為8x8。一旦他們開始做矩陣乘法,兩個矩陣的這些系數(shù)將首先轉(zhuǎn)換成一個順序輸入到 TPU 中,然后輸入到每個特定的隊列中。然后這些隊列將最多向其連接的單元輸出 8 個數(shù)據(jù),這些單元將根據(jù)它接收到的權(quán)重和數(shù)據(jù)進(jìn)行乘法和加法。并且在下一個周期中,每個單元格將其權(quán)重和數(shù)據(jù)轉(zhuǎn)發(fā)給下一個單元格。權(quán)重從上到下,數(shù)據(jù)從左到右。
該項目雖然完成了相關(guān)的目的,但是只是完成了相關(guān)工作,實際使用時需要進(jìn)行一些優(yōu)化。
super_small_toy_tpu
?
https://github.com/dldldlfma/super_small_toy_tpu
如果說上面幾個TPU比較復(fù)雜,那么這個就可以用“精簡”來形容了。
整個代碼非常精簡,適合入門想研究TPU的人。
AIC2021-TPU
?
https://github.com/charley871103/TPU
?
https://github.com/Oscarkai9139/AIC2021-TPU
?
https://github.com/hsiehong/tpu
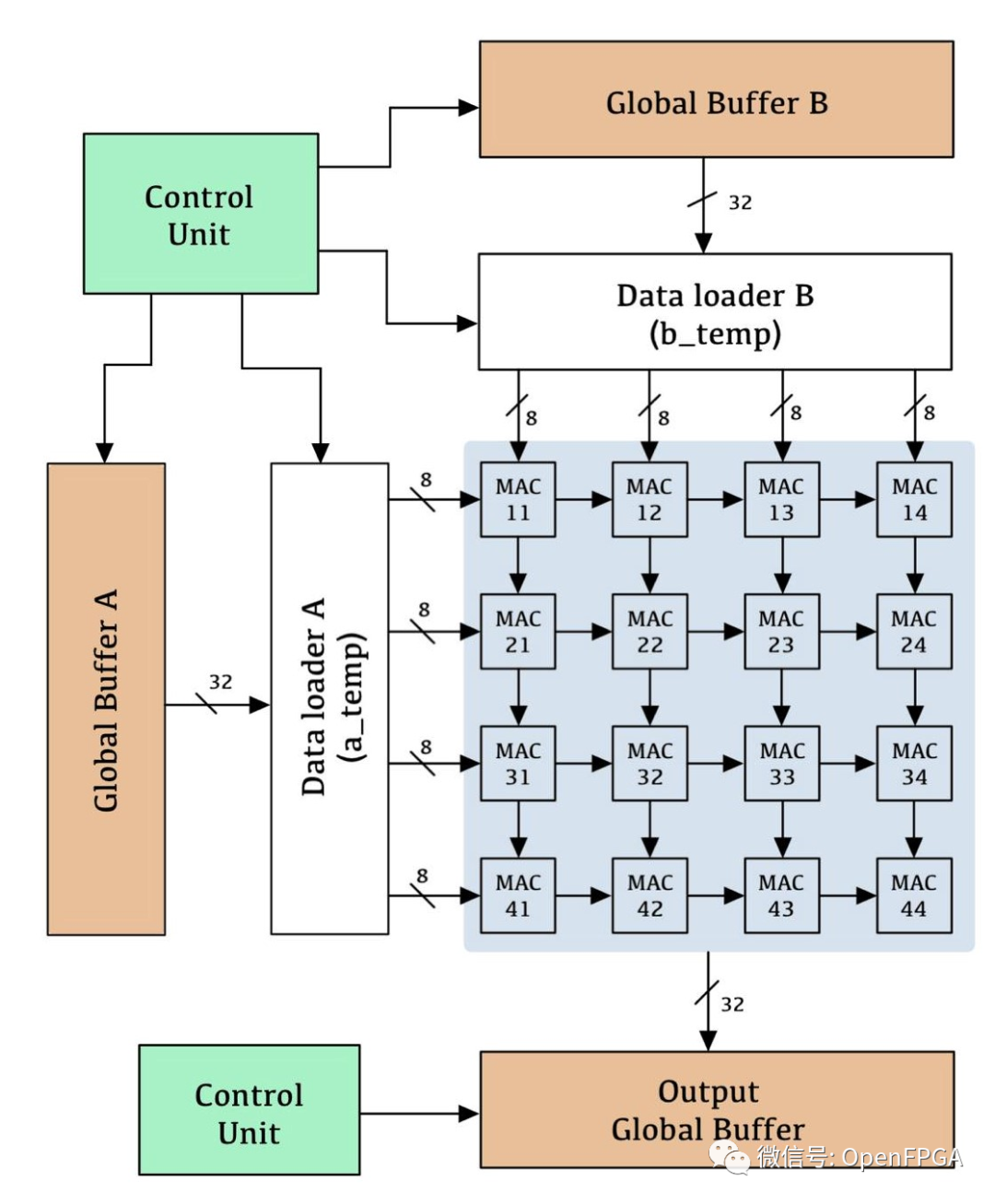
這個項目是AIC2021-TPU,類似的項目有很多,都是理論研究的項目,和上面的項目一樣都是非常非常適合入門研究的人員,里面的理論都是極其詳細(xì)的。
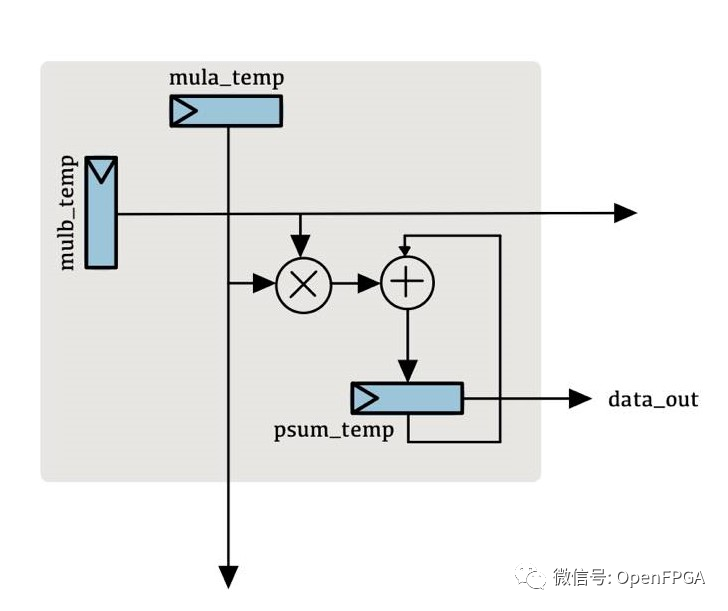
systolic-array
?
https://github.com/Dazhuzhu-github/systolic-array
verilog實現(xiàn)TPU中的脈動陣列計算卷積的module
data為實驗數(shù)據(jù)
source為源碼
testbench 測試各個模塊用的testbench
data-preprocessing 原本是要寫將卷積操作用python預(yù)先imtocol操作的,但后來直接使用matlab生成數(shù)據(jù)進(jìn)行測試了
tpu_v2
?
https://github.com/UT-LCA/tpu_v2
項目沒有多余的介紹,整個項目是基于Altera-DE3設(shè)計,EDA工具是Quartus II。

google-coral-baseboard
?
https://github.com/antmicro/google-coral-baseboard

NXP i.MX8X 和 Google 的 Edge TPU ML 推理 ASIC(也可作為Coral Edge TPU 開發(fā)板的一部分)的基板的開放硬件設(shè)計文件。該板提供標(biāo)準(zhǔn) I/O 接口,并允許用戶通過統(tǒng)一的柔性扁平電纜 (FFC) 連接器與兩個兼容 MIPI CSI-2 的視頻設(shè)備連接。

PCB 項目文件是在 Altium Designer 14.1 中準(zhǔn)備的。
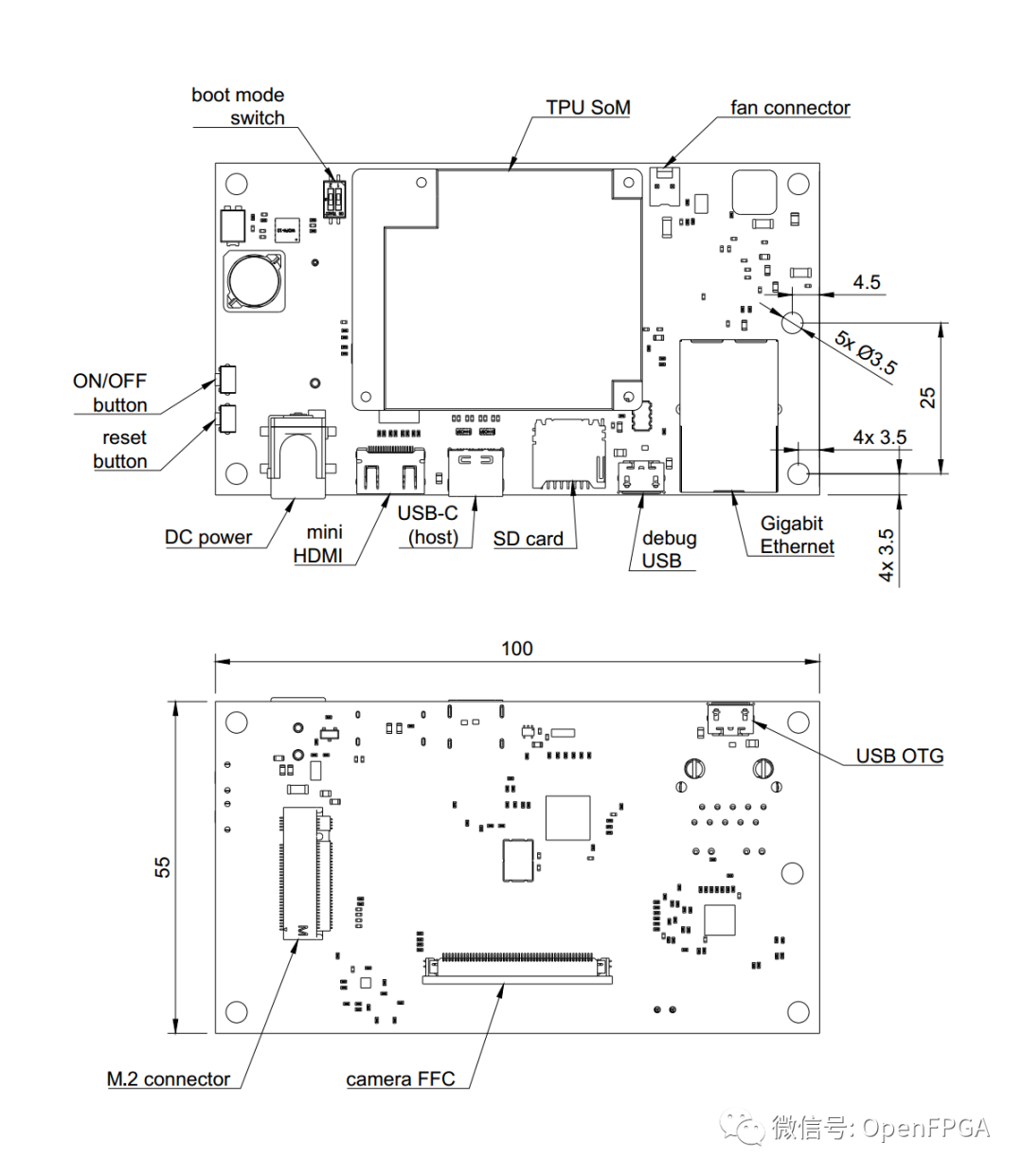
該項目是一個硬件方案,谷歌Coral Edge TPU的硬件驗證方案。
neural-engine
?
https://github.com/hollance/neural-engine
大多數(shù)新的 iPhone 和 iPad 都有神經(jīng)引擎,這是一種特殊的處理器,可以讓機(jī)器學(xué)習(xí)模型變得非常快,但對于這種處理器的實際工作原理,公眾知之甚少。
Apple 神經(jīng)引擎(或 ANE)是NPU的一種,代表神經(jīng)處理單元。它就像 GPU,但 NPU 不是加速圖形,而是加速卷積和矩陣乘法等神經(jīng)網(wǎng)絡(luò)操作。
ANE 并不是唯一的 NPU——除了 Apple 之外,許多公司都在開發(fā)自己的 AI 加速器芯片。除了神經(jīng)引擎,最著名的 NPU 是谷歌的 TPU(或 Tensor Processing Unit)。
這個項目并不是一個實現(xiàn)TPU的項目,但是是一個關(guān)于Apple 神經(jīng)引擎(或 ANE)介紹及相關(guān)文檔的集合的項目。
總結(jié)
今天介紹了幾個TPU的項目,因為在國內(nèi)TPU可能很多人都沒有聽說過,所以接下來我會出幾篇文章介紹一下。同時這些項目前面幾個非常完整,完全可以優(yōu)化后進(jìn)行商業(yè)推廣(注意開源協(xié)議),最后幾個項目是一些補(bǔ)充的知識,想要了解相關(guān)的知識的朋友可以查看一下。
最后,還是感謝各個大佬開源的項目,讓我們受益匪淺。后面有什么感興趣方面的項目,大家可以在后臺留言或者加微信留言,今天就到這,我是爆肝的碎碎思,期待下期文章與你相見。
審核編輯 :李倩
-
FPGA
+關(guān)注
關(guān)注
1630文章
21798瀏覽量
606065 -
Verilog
+關(guān)注
關(guān)注
28文章
1351瀏覽量
110400 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8441瀏覽量
133094
原文標(biāo)題:優(yōu)秀的 Verilog/FPGA開源項目介紹(二十)- 張量處理單元(TPU)
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
OpenAI與博通洽談合作!定制化ASIC芯片走向臺前,英偉達(dá)GPU迎來“勁敵”?

TPU編程競賽系列|第九屆集創(chuàng)賽“算能杯”火熱報名中!

光纜用tpu外護(hù)套用在哪些型號光纜上
半導(dǎo)體所在光學(xué)張量處理領(lǐng)域取得新進(jìn)展
RK3568國產(chǎn)處理器 + TensorFlow框架的張量創(chuàng)建實驗案例分享
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
pcie在深度學(xué)習(xí)中的應(yīng)用
微處理器的執(zhí)行單元是什么
使用邏輯和轉(zhuǎn)換優(yōu)化數(shù)字駕駛艙處理單元






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論