") 利用NVIDIA HGX H100加速計算數(shù)據(jù)中心平臺應(yīng)用
利用NVIDIA HGX H100加速計算數(shù)據(jù)中心平臺應(yīng)用
NVIDIA 的使命是加快我們的時代達(dá)芬奇和愛因斯坦的工作,并賦予他們解決社會的巨大挑戰(zhàn)。隨著 人工智能 ( AI )、 高性能計算 ( HPC )和數(shù)據(jù)分析的復(fù)雜性呈指數(shù)級增長,科學(xué)家需要一個先進(jìn)的計算平臺,能夠在一個十年內(nèi)實(shí)現(xiàn)百萬次的加速,以解決這些非同尋常的挑戰(zhàn)。
為了回答這個需求,我們介紹了NVIDIA HGX H100 ,一個由 NVIDIA Hopper 架構(gòu) 供電的密鑰 GPU 服務(wù)器構(gòu)建塊。這一最先進(jìn)的平臺安全地提供了低延遲的高性能,并集成了從網(wǎng)絡(luò)到數(shù)據(jù)中心級計算(新的計算單元)的全套功能。
在這篇文章中,我將討論NVIDIA HGX H100 是如何幫助我們加速計算數(shù)據(jù)中心平臺的下一個巨大飛躍。
HGX H100 8-GPU
HGX H100 8- GPU 是新一代 Hopper GPU 服務(wù)器的關(guān)鍵組成部分。它擁有八個 H100 張量核 GPU 和四個第三代 NV 交換機(jī)。每個 H100 GPU 都有多個第四代 NVLink 端口,并連接到所有四個 NVLink 交換機(jī)。每個 NVSwitch 都是一個完全無阻塞的交換機(jī),完全連接所有八個 H100 Tensor Core GPU 。
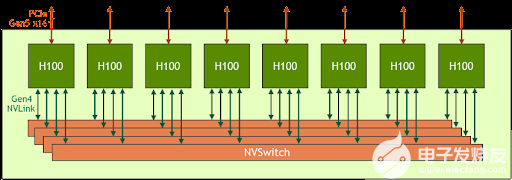
圖 1 。 HGX H100 8-GPU 的高級框圖
NVSwitch 的這種完全連接的拓?fù)浣Y(jié)構(gòu)使任何 H100 都可以同時與任何其他 H100 通話。值得注意的是,這種通信以每秒 900 千兆字節(jié)( GB / s )的 NVLink 雙向速度運(yùn)行,這是當(dāng)前 PCIe Gen4 x16 總線帶寬的 14 倍多。
第三代 NVSwitch 還為集體運(yùn)營提供了新的硬件加速,多播和 NVIDIA 的網(wǎng)絡(luò)規(guī)模大幅縮減。結(jié)合更快的 NVLink 速度,像all-reduce這樣的普通人工智能集體操作的有效帶寬比 HGX A100 增加了 3 倍。集體的 NVSwitch 加速也顯著降低了 GPU 上的負(fù)載。
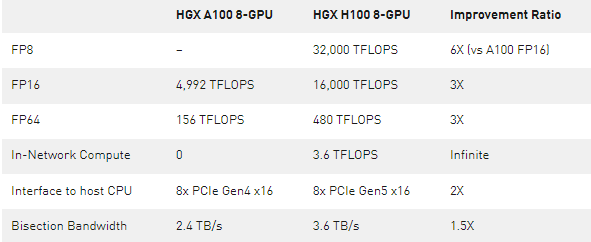
表 1 。將 HGX A100 8- GPU 與新的 HGX H100 8-GPU 進(jìn)行比較
*注: FP 性能包括稀疏性
HGX H100 8- GPU 支持 NVLink 網(wǎng)絡(luò)
新興的 exascale HPC 和萬億參數(shù)人工智能模型(用于精確對話人工智能等任務(wù))需要數(shù)月的訓(xùn)練,即使是在超級計算機(jī)上。將其壓縮到業(yè)務(wù)速度并在數(shù)小時內(nèi)完成培訓(xùn)需要服務(wù)器集群中每個 GPU 之間的高速、無縫通信。
為了解決這些大的使用案例,新的 NVLink 和 NVSwitch 旨在使 HGX H100 8- GPU 能夠通過新的 NVLink 網(wǎng)絡(luò)擴(kuò)展并支持更大的 NVLink 域。 HGX H100 8- GPU 的另一個版本具有這種新的 NVLink 網(wǎng)絡(luò)支持。
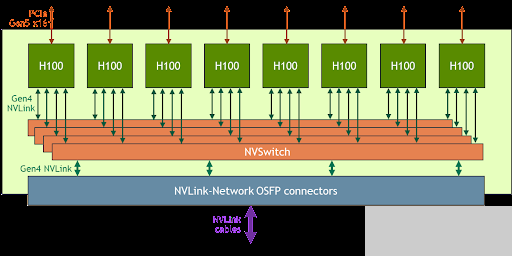
圖 2 。支持 NVLink 網(wǎng)絡(luò)的 HGX H100 8- GPU 的高級框圖
使用 HGX H100 8- GPU 和 NVLink 網(wǎng)絡(luò)支持構(gòu)建的系統(tǒng)節(jié)點(diǎn)可以通過八進(jìn)制小尺寸可插拔( OSFP ) LinkX 電纜和新的外部 NVLink 交換機(jī)完全連接到其他系統(tǒng)。此連接最多支持 256 個 GPU NVLink 域。圖 3 顯示了集群拓?fù)洹?/p>
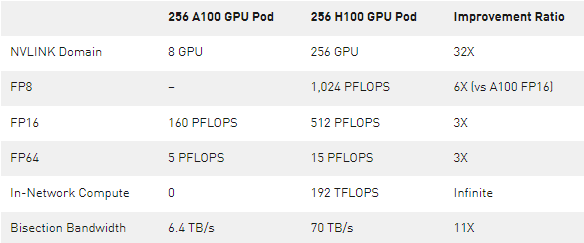
表 2 。比較 256 個 A100 GPU 吊艙和 256 個 H100 GPU 吊艙
*注: FP 性能包括稀疏性
目標(biāo)用例和性能優(yōu)勢
隨著 HGX H100 計算和網(wǎng)絡(luò)能力的大幅增加, AI 和 HPC 應(yīng)用程序的性能得到了極大的提高。
今天的主流 AI 和 HPC 模型可以完全駐留在單個節(jié)點(diǎn)的聚合 GPU 內(nèi)存中。例如, BERT -Large 、 Mask R-CNN 和 HGX H100 是最高效的培訓(xùn)解決方案。
對于更先進(jìn)、更大的 AI 和 HPC 模型,該模型需要多個聚合 GPU 內(nèi)存節(jié)點(diǎn)才能適應(yīng)。例如,具有 TB 級嵌入式表的深度學(xué)習(xí)推薦模型( DLRM )、大量混合專家( MoE )自然語言處理模型,以及具有 NVLink 網(wǎng)絡(luò)的 HGX H100 加速了關(guān)鍵通信瓶頸,是此類工作負(fù)載的最佳解決方案。
圖 4 來自 NVIDIA H100 GPU 體系結(jié)構(gòu) 白皮書顯示了 NVLink 網(wǎng)絡(luò)帶來的額外性能提升。
所有性能數(shù)據(jù)都是基于當(dāng)前預(yù)期的初步數(shù)據(jù),可能會隨著運(yùn)輸產(chǎn)品的變化而變化。 A100 集群: HDR IB 網(wǎng)絡(luò)。 H100 集群: NDR IB 網(wǎng)絡(luò)和 NVLink 網(wǎng)絡(luò),如圖所示。
# GPU :氣候建模 1K , LQCD 1K ,基因組學(xué) 8 , 3D-FFT 256 , MT-NLG 32 (批次大小: A100 為 4 , 1 秒 H100 為 60 , A100 為 8 , 1.5 和 2 秒 H100 為 64 ), MRCNN 8 (批次 32 ), GPT-3 16B 512 (批次 256 ), DLRM 128 (批次 64K ), GPT-3 16K (批次 512 ), MoE 8K (批次 512 ,每個 GPU 一名專家)?
HGX H100 4-GPU
除了 8- GPU 版本外, HGX 系列還具有一個 4-GPU 版本,該版本直接與第四代 NVLink 連接。
H100 對 H100 點(diǎn)對點(diǎn)對等 NVLink 帶寬為 300 GB / s 雙向,比今天的 PCIe Gen4 x16 總線快約 5 倍。
HGX H100 4- GPU 外形經(jīng)過優(yōu)化,可用于密集 HPC 部署:
多個 HGX H100 4- GPU 可以裝在 1U 高液體冷卻系統(tǒng)中,以最大化每個機(jī)架的 GPU 密度。
帶有 HGX H100 4- GPU 的完全無 PCIe 交換機(jī)架構(gòu)直接連接到 CPU ,降低了系統(tǒng)材料清單并節(jié)省了電源。
對于 CPU 更密集的工作負(fù)載, HGX H100 4- GPU 可以與兩個 CPU 插槽配對,以提高 CPU 與 GPU 的比率,從而實(shí)現(xiàn)更平衡的系統(tǒng)配置。
人工智能和高性能計算的加速服務(wù)器平臺
NVIDIA 正與我們的生態(tài)系統(tǒng)密切合作,在今年晚些時候?qū)⒒?HGX H100 的服務(wù)器平臺推向市場。我們期待著把這個強(qiáng)大的計算工具交給你們,使你們能夠以人類歷史上最快的速度創(chuàng)新和完成你們一生的工作。
關(guān)于作者
William Tsu NVIDIA HGX 數(shù)據(jù)中心產(chǎn)品線的產(chǎn)品管理。他與客戶和合作伙伴合作,將世界上性能最高的人工智能、深度學(xué)習(xí)和 HPC 服務(wù)器平臺推向市場。威廉最初加入NVIDIA 是作為一名圖形處理器芯片設(shè)計師。他是最初的 PCI Express 行業(yè)標(biāo)準(zhǔn)規(guī)范的共同作者,也是 12 項(xiàng)專利的共同發(fā)明人。威廉獲得了他的學(xué)士學(xué)位,碩士學(xué)位在計算機(jī)科學(xué)和 MBA 從加利福尼亞大學(xué),伯克利。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103723 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4859瀏覽量
72381 -
人工智能
+關(guān)注
關(guān)注
1796文章
47674瀏覽量
240293 -
H100
+關(guān)注
關(guān)注
0文章
31瀏覽量
309
發(fā)布評論請先 登錄
相關(guān)推薦
利用NVIDIA DPF引領(lǐng)DPU加速云計算的未來
NIDA發(fā)布《智算數(shù)據(jù)中心網(wǎng)絡(luò)建設(shè)技術(shù)要求》
Supermicro推出直接液冷優(yōu)化的NVIDIA Blackwell解決方案

華為致力于打造安全可靠的智算數(shù)據(jù)中心
NVIDIA向開放計算項(xiàng)目捐贈Blackwell平臺設(shè)計
華迅光通AI計算加速800G光模塊部署
英偉達(dá)H100芯片市場降溫
云計算與數(shù)據(jù)中心的關(guān)系
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
SK電訊將與Lambda合作打造AI數(shù)據(jù)中心
Supermicro推出適配NVIDIA Blackwell和NVIDIA HGX H100/H200的機(jī)柜級即插即用液冷AI SuperCluster

首批1024塊H100 GPU,正崴集團(tuán)將建中國臺灣最大AI計算中心
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級芯片
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論