") NVIDIA Jetson AGX Xavier應(yīng)用在AI和
NVIDIA Jetson AGX Xavier應(yīng)用在AI和
面向 AI 開發(fā)人員的全球終極嵌入式解決方案JetsonAGXXavier現(xiàn)已作為 NVIDIA 的獨(dú)立生產(chǎn)模塊發(fā)貨。英偉達(dá) AGX 系統(tǒng)的成員對(duì)于自主機(jī)器,Jetson AGX Xavier 非常適合將先進(jìn)的 AI 和計(jì)算機(jī)視覺部署到邊緣,使現(xiàn)場(chǎng)機(jī)器人平臺(tái)具有工作站級(jí)性能,并能夠在不依賴人工干預(yù)和云連接的情況下完全自主運(yùn)行。由 Jetson AGX Xavier 提供支持的智能機(jī)器可以自由地在其環(huán)境中進(jìn)行交互和安全導(dǎo)航,不受復(fù)雜地形和動(dòng)態(tài)障礙物的阻礙,完全自主地完成現(xiàn)實(shí)世界的任務(wù)。這包括需要高級(jí)實(shí)時(shí)感知和推理才能執(zhí)行的包裹遞送和工業(yè)檢查。作為世界上第一臺(tái)專為機(jī)器人和邊緣計(jì)算設(shè)計(jì)的計(jì)算機(jī),Jetson AGX Xavier 的高性能可以處理視覺里程計(jì)、傳感器融合、定位和映射,障礙物檢測(cè)和對(duì)下一代機(jī)器人至關(guān)重要的路徑規(guī)劃算法。圖 1 顯示了現(xiàn)在全球可用的生產(chǎn)計(jì)算模塊。開發(fā)人員現(xiàn)在可以開始批量部署新的自主機(jī)器。
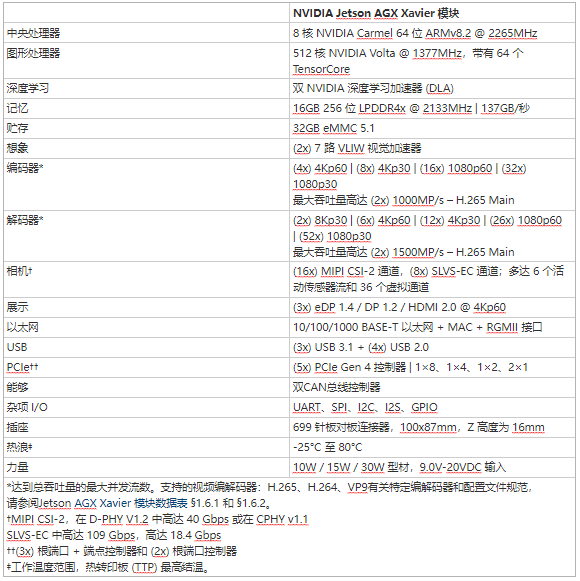
最新一代 NVIDIA 業(yè)界領(lǐng)先的Jetson AGX系列嵌入式 Linux 高性能計(jì)算機(jī),Jetson AGX Xavier 提供 GPU 工作站級(jí)性能,具有無與倫比的 32 TeraOPS (TOPS) 峰值計(jì)算和 750Gbps 的高速 I/O,體積小巧100x87mm 外形尺寸。用戶可以根據(jù)應(yīng)用需要配置 10W、15W 和 30W 的工作模式。Jetson AGX Xavier 為可部署到邊緣的計(jì)算密度、能源效率和 AI 推理功能樹立了新的標(biāo)桿,使具有端到端自主能力的下一級(jí)智能機(jī)器成為可能。
Jetson 使用深度學(xué)習(xí)和計(jì)算機(jī)視覺為世界上許多最先進(jìn)的機(jī)器人和自主機(jī)器背后的 AI 提供動(dòng)力,同時(shí)專注于性能、效率和可編程性。Jetson AGX Xavier,如圖 2 所示,由超過 90 億個(gè)晶體管組成,基于有史以來最復(fù)雜的片上系統(tǒng) (SoC)。該平臺(tái)包含一個(gè)集成的 512 核 NVIDIA Volta GPU,包括 64 個(gè)張量核心、8 核 NVIDIA Carmel ARMv8.2 64 位 CPU、16GB 256 位 LPDDR4x、雙 NVIDIA深度學(xué)習(xí)加速器(DLA) 引擎、NVIDIA Vision Accelerator 引擎、高清視頻編解碼器、128Gbps 的專用攝像頭攝取和 16 通道 PCIe Gen 4 擴(kuò)展。256 位接口上的內(nèi)存帶寬為 137GB/s,而 DLA 引擎卸載了深度神經(jīng)網(wǎng)絡(luò) (DNN) 的推理。NVIDIA 用于 Jetson AGX Xavier 的 JetPack SDK 4.1.1 包括 CUDA 10.0、cuDNN 7.3 和 TensorRT 5.0,提供完整的 AI 軟件堆棧。
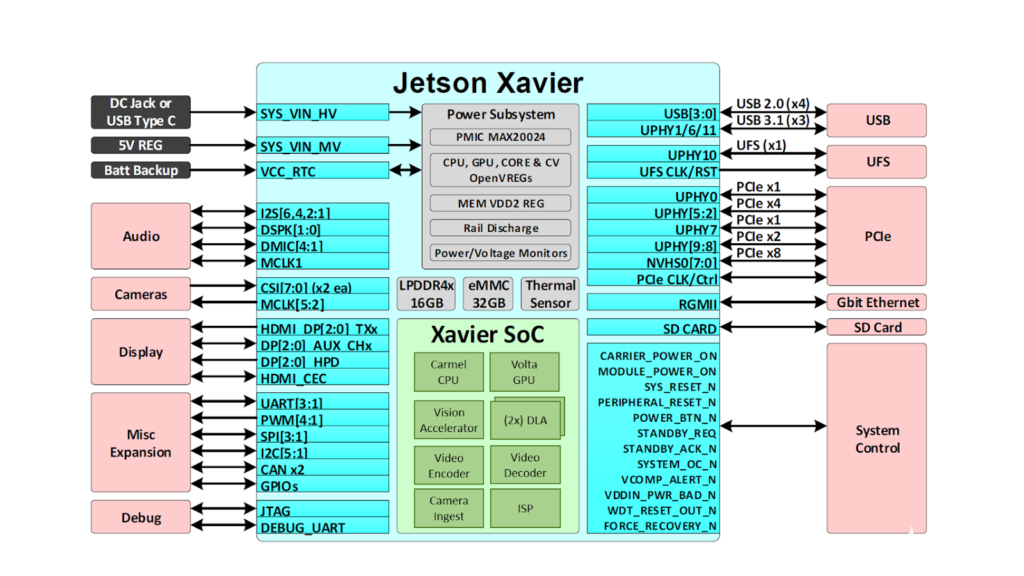
圖 2. Jetson AGX Xavier 提供一組豐富的高速 I/O
這使開發(fā)人員能夠在機(jī)器人、智能視頻分析、醫(yī)療儀器、嵌入式物聯(lián)網(wǎng)邊緣設(shè)備等應(yīng)用中部署加速 AI。與其前身 Jetson TX1 和 TX2 一樣,Jetson AGX Xavier 使用系統(tǒng)級(jí)模塊 (SoM) 范例。所有處理都包含在計(jì)算模塊上,高速 I/O 位于通過高密度板對(duì)板連接器提供的分線載體或外殼上。以這種方式在模塊上封裝功能使開發(fā)人員可以輕松地將 Jetson Xavier 集成到他們自己的設(shè)計(jì)中。NVIDIA 發(fā)布了全面的文檔和參考設(shè)計(jì)文件,可供嵌入式設(shè)計(jì)人員下載,以使用 Jetson AGX Xavier 創(chuàng)建自己的設(shè)備和平臺(tái)。請(qǐng)務(wù)必咨詢JetsonAGXXavier 模塊數(shù)據(jù)表和JetsonAGXXavier OEM 產(chǎn)品設(shè)計(jì)指南,了解表 1 中列出的全部產(chǎn)品功能,以及機(jī)電規(guī)格、模塊引腳排列、電源排序和信號(hào)路由指南。
Jetson AGX Xavier 包括超過 750Gbps 的高速 I/O,為流式傳感器和高速外圍設(shè)備提供了非凡的帶寬。它是首批支持 PCIe Gen 4 的嵌入式設(shè)備之一,在五個(gè) PCIe Gen 4 控制器上提供 16 個(gè)通道,其中三個(gè)可以在根端口或端點(diǎn)模式下運(yùn)行。16 個(gè) MIPI CSI-2 通道可連接到四個(gè) 4 通道攝像頭、六個(gè) 2 通道攝像頭、六個(gè) 1 通道攝像頭或這些配置的組合,最多六個(gè)攝像頭,36 個(gè)虛擬通道允許同時(shí)連接更多攝像頭使用流聚合。其他高速 I/O 包括三個(gè) USB 3.1 端口、SLVS-EC、UFS 和用于千兆以太網(wǎng)的 RGMII。開發(fā)者現(xiàn)在可以訪問 NVIDIA 的JetPack 4.1.1 開發(fā)者預(yù)覽版Jetson AGX Xavier 的軟件,列于表 2。開發(fā)者預(yù)覽版包括 Linux For Tegra (L4T) R31.1 板級(jí)支持包 (BSP),支持 Linux 內(nèi)核 4.9 和目標(biāo)上的 Ubuntu 18.04。在主機(jī) PC 端,JetPack 4.1.1 支持 Ubuntu 16.04 和 Ubuntu 18.04。
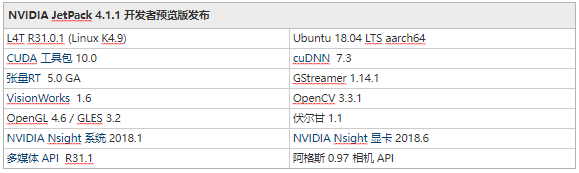
JetPack 4.1.1 開發(fā)人員預(yù)覽版允許開發(fā)人員立即開始使用 Jetson AGX Xavier 對(duì)產(chǎn)品和應(yīng)用程序進(jìn)行原型設(shè)計(jì),為生產(chǎn)部署做準(zhǔn)備。NVIDIA 將繼續(xù)通過額外的功能增強(qiáng)和性能優(yōu)化來改進(jìn) JetPack。請(qǐng)閱讀發(fā)行說明以了解此版本的亮點(diǎn)和軟件狀態(tài)。
伏特顯卡
Jetson AGX Xavier 集成 Volta GPU,如圖 3 所示,提供 512 個(gè) CUDA 內(nèi)核和 64 個(gè) Tensor 內(nèi)核,可實(shí)現(xiàn)高達(dá) 11 TFLOPS FP16 或 22 TOPS 的 INT8 計(jì)算,最大時(shí)鐘頻率為 1.37GHz。它支持計(jì)算能力為 sm_72 的 CUDA 10。GPU 包括 8 個(gè) Volta 流式多處理器 (SM),每個(gè) Volta SM 有 64 個(gè) CUDA 核心和 8 個(gè)張量核心。每個(gè) Volta SM 都包含一個(gè) 128KB L1 緩存,比前幾代產(chǎn)品大 8 倍。SM 共享一個(gè) 512KB L2 緩存,提供比前幾代快 4 倍的訪問速度。
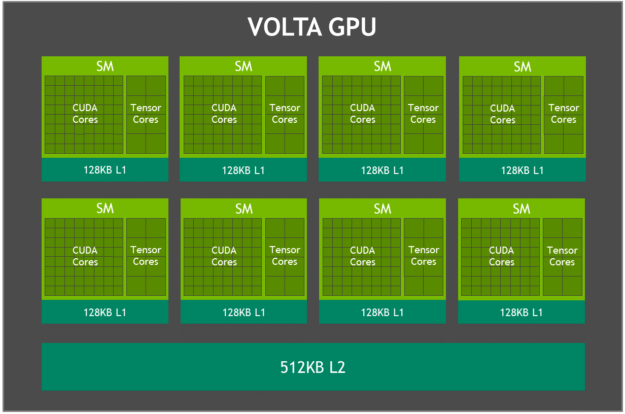
圖 3. Jetson AGX Xavier Volta GPU 框圖
每個(gè) SM 由 4 個(gè)獨(dú)立的處理塊組成,稱為 SMP(流式多處理器分區(qū)),每個(gè)處理塊都包括自己的 L0 指令緩存、warp 調(diào)度程序、調(diào)度單元和寄存器文件,以及 CUDA 核心和張量核心。每個(gè) SM 的 SMP 數(shù)量是 Pascal 的兩倍,Volta SM 具有改進(jìn)的并發(fā)性,并支持更多的線程、warp 和運(yùn)行中的線程塊。
張量核心
NVIDIA 張量核心是可編程的融合矩陣乘法和累加單元,可與 CUDA 核心同時(shí)執(zhí)行。張量核心實(shí)現(xiàn)了新的浮點(diǎn) HMMA(半精度矩陣乘法和累加)和 IMMA(整數(shù)矩陣乘法和累加)指令,用于加速密集線性代數(shù)計(jì)算、信號(hào)處理和深度學(xué)習(xí)推理。
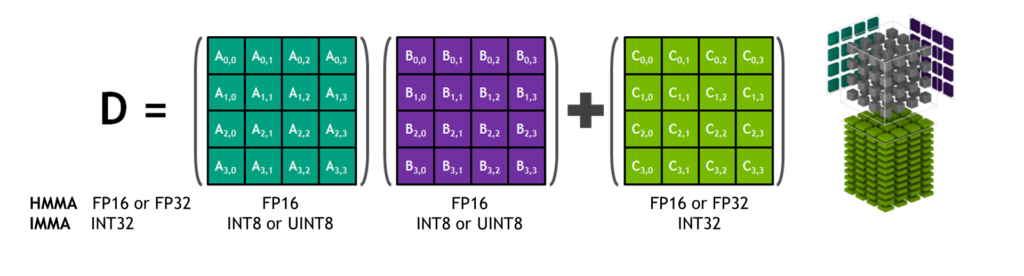
圖 4. Tensor Core HMMA/IMMA 4x4x4 矩陣乘法和累加
矩陣乘法輸入A和B是 HMMA 指令的 FP16 矩陣,而累加矩陣C和D可以是 FP16 或 FP32 矩陣。對(duì)于 IMMA,矩陣乘法輸入A是有符號(hào)或無符號(hào) INT8 或 INT16 矩陣,B是有符號(hào)或無符號(hào) INT8 矩陣,C和D累加器矩陣都是有符號(hào) INT32。因此,精度和計(jì)算范圍足以避免內(nèi)部累加期間的上溢和下溢情況。
包括 cuBLAS、cuDNN 和 TensorRT 在內(nèi)的 NVIDIA 庫(kù)已更新為在內(nèi)部使用 HMMA 和 IMMA,使程序員能夠輕松利用 Tensor Core 固有的性能提升。用戶還可以通過 CUDA 10 中包含的 wmma 命名空間和 mma.h 標(biāo)頭中公開的新 API 直接在 warp 級(jí)別訪問 Tensor Core 操作。warp 級(jí)接口映射 16×16、32×8 和 8×32 大小每個(gè)扭曲的所有 32 個(gè)線程的矩陣。
深度學(xué)習(xí)加速器
Jetson AGX Xavier 具有兩個(gè) NVIDIA深度學(xué)習(xí)加速器(DLA) 引擎,如圖 5 所示,可卸載固定功能卷積神經(jīng)網(wǎng)絡(luò) (CNN) 的推理。這些引擎提高了能源效率并釋放了 GPU 來運(yùn)行用戶實(shí)現(xiàn)的更復(fù)雜的網(wǎng)絡(luò)和動(dòng)態(tài)任務(wù)。NVIDIA DLA 硬件架構(gòu)是開源的,可從NVDLA.org 獲得。每個(gè) DLA 具有高達(dá) 5 TOPS INT8 或 2.5 TFLOPS FP16 的性能,功耗僅為 0.5-1.5W。DLA 支持加速 CNN 層,例如卷積、反卷積、激活函數(shù)、最小/最大/均值池、局部響應(yīng)歸一化和全連接層。
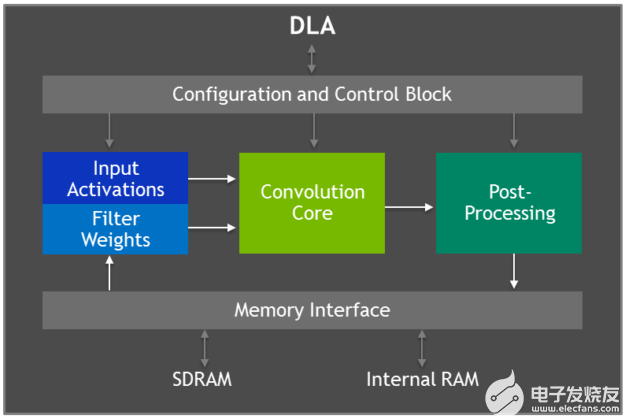
圖 5. 深度學(xué)習(xí)加速器 (DLA) 架構(gòu)框圖
DLA 硬件由以下組件組成:
Convolution Core – 優(yōu)化的高性能卷積引擎。
單數(shù)據(jù)處理器——用于激活功能的單點(diǎn)查找引擎。
平面數(shù)據(jù)處理器——用于池化的平面平均引擎。
通道數(shù)據(jù)處理器——用于高級(jí)標(biāo)準(zhǔn)化功能的多通道平均引擎。
專用內(nèi)存和數(shù)據(jù)重塑引擎——用于張量重塑和復(fù)制操作的內(nèi)存到內(nèi)存轉(zhuǎn)換加速。
開發(fā)人員使用 TensorRT 5.0 對(duì) DLA 引擎進(jìn)行編程,以在網(wǎng)絡(luò)上執(zhí)行推理,包括對(duì) AlexNet、GoogleNet 和 ResNet-50 的支持。對(duì)于使用 DLA 不支持的層配置的網(wǎng)絡(luò),TensorRT 為無法在 DLA 上運(yùn)行的層提供 GPU 回退。JetPack 4.0 開發(fā)者預(yù)覽版最初將 DLA 精度限制為 FP16 模式,未來 JetPack 版本中將提供 INT8 精度和更高的 DLA 性能。
TensorRT 5.0 將以下 API 添加到其 IBuilder 接口以啟用 DLA:
setDeviceType()以及setDefaultDeviceType()默認(rèn)選擇 GPU、DLA_0 或 DLA_1 來執(zhí)行特定層或網(wǎng)絡(luò)中的所有層。
canRunOnDLA()檢查層是否可以按照配置在 DLA 上運(yùn)行。
getMaxDLABatchSize()用于檢索 DLA 可以支持的最大批量大小。
allowGPUFallback()使 GPU 能夠執(zhí)行 DLA 不支持的層。
請(qǐng)參閱TensorRT 5.0 開發(fā)人員指南的第 6 章,了解支持的層配置的完整列表以及在 TensorRT 中使用 DLA 的代碼示例。
深度學(xué)習(xí)推理基準(zhǔn)
我們已經(jīng)發(fā)布了 Jetson AGX Xavier 在常見 DNN(例如 ResNet、GoogleNet 和 VGG 的變體)上的深度學(xué)習(xí)推理基準(zhǔn)測(cè)試結(jié)果。我們?cè)?Jetson AGX Xavier 的 GPU 和 DLA 引擎上使用帶有 TensorRT 5.0 的 JetPack 4.1.1 開發(fā)者預(yù)覽版為 Jetson AGX Xavier 運(yùn)行這些基準(zhǔn)測(cè)試。GPU 和兩個(gè) DLA 分別以 INT8 和 FP16 精度同時(shí)運(yùn)行相同的網(wǎng)絡(luò)架構(gòu),并報(bào)告每種配置的總體性能。GPU 和 DLA 可以在實(shí)際用例中同時(shí)運(yùn)行不同的網(wǎng)絡(luò)或網(wǎng)絡(luò)模型,并行或在處理管道中提供獨(dú)特的功能。在 TensorRT 中使用 INT8 與完整的 FP32 精度會(huì)導(dǎo)致精度損失 1% 或更少。
首先,讓我們考慮 ResNet-18 FCN (Fully Convolutional Network) 的結(jié)果,這是一個(gè)用于語義分割的 2048×1024 分辨率的全高清模型。分割為自由空間檢測(cè)和占用映射等任務(wù)提供每像素分類,并代表由自主機(jī)器計(jì)算的用于感知、路徑規(guī)劃和導(dǎo)航的深度學(xué)習(xí)工作負(fù)載。圖 6 顯示了在 Jetson AGX Xavier 與 Jetson TX2 上運(yùn)行 ResNet-18 FCN 的測(cè)量吞吐量。
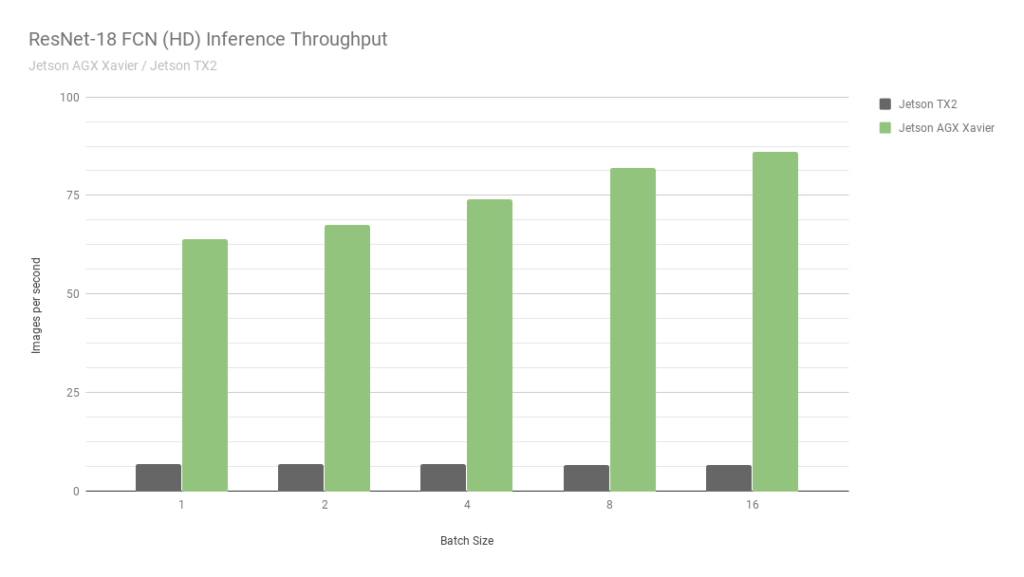
圖 6. Jetson AGX Xavier 和 Jetson TX2 的 ResNet-18 FCN 推理吞吐量
與 Jetson TX2 相比,Jetson AGX Xavier 目前在 ResNet-18 FCN 推理中的性能高達(dá) 13 倍。NVIDIA 將繼續(xù)在 JetPack 中發(fā)布軟件優(yōu)化和功能增強(qiáng),隨著時(shí)間的推移將進(jìn)一步提高性能和功率特性。請(qǐng)注意,基準(zhǔn)結(jié)果的完整列表報(bào)告了 Jetson AGX Xavier 的 ResNet-18 FCN 的性能,批次大小為 32,但是在圖 7 中,我們僅繪制了 16 的批次大小,因?yàn)?Jetson TX2 能夠運(yùn)行 ResNet -18 FCN,最大批量為 16。
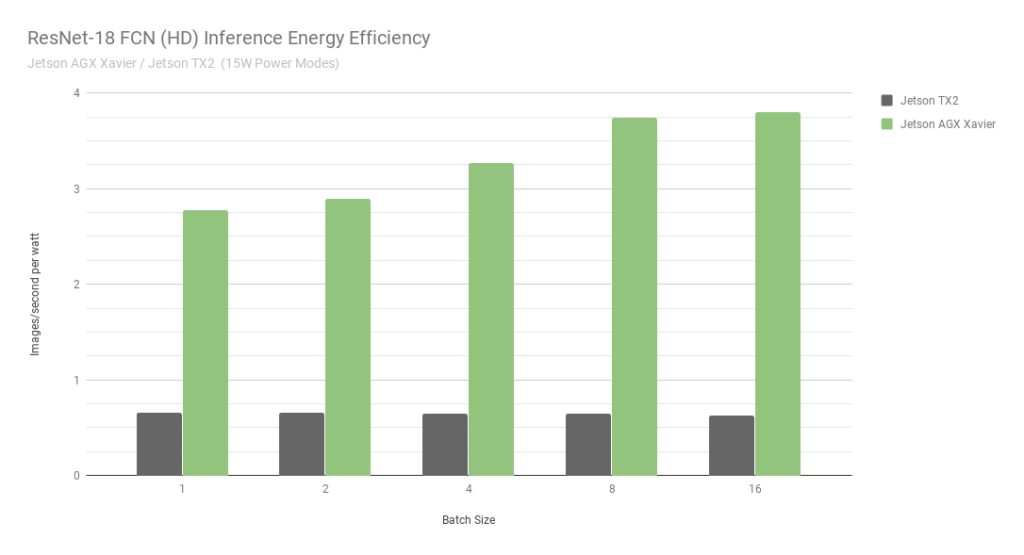
圖 7. ResNet-18 FCN 推理 Jetson AGX Xavier 和 Jetson TX2 的能效
在考慮使用每秒每瓦特處理圖像的能效時(shí),Jetson AGX Xavier 目前在 ResNet-18 FCN 上的能效比 Jetson TX2 高 6 倍。我們通過使用板載 INA 電壓和電流監(jiān)視器測(cè)量總模塊功耗來計(jì)算效率,包括 CPU、GPU、DLA、內(nèi)存、其他 SoC 電源、I/O 和所有軌上的穩(wěn)壓器效率損失。兩臺(tái) Jetson 均在 15W 功率模式下運(yùn)行。Jetson AGX Xavier 和 JetPack 附帶 10W、15W 和 30W 的可配置預(yù)設(shè)功率配置文件,可在運(yùn)行時(shí)使用 nvpmodel 電源管理工具進(jìn)行切換。用戶還可以使用不同的時(shí)鐘和 DVFS(動(dòng)態(tài)電壓和頻率縮放)調(diào)節(jié)器設(shè)置來定義自己的自定義配置文件,這些配置文件已經(jīng)過定制,以實(shí)現(xiàn)單個(gè)應(yīng)用程序的最佳性能。
接下來,讓我們比較 Jetson AGX Xavier 基準(zhǔn)在圖像識(shí)別網(wǎng)絡(luò) ResNet-50 和 VGG19 上的批量大小 1 到 128 與 Jetson TX2。這些模型對(duì)分辨率為 224×224 的圖像塊進(jìn)行分類,并經(jīng)常用作各種對(duì)象檢測(cè)網(wǎng)絡(luò)中的編碼器主干。在較低分辨率下使用 8 或更高的批大小可用于近似在更高分辨率下批大小為 1 的性能和延遲。機(jī)器人平臺(tái)和自主機(jī)器通常包含多個(gè)相機(jī)和傳感器,這些相機(jī)和傳感器可以進(jìn)行批處理以提高性能,此外還可以執(zhí)行感興趣區(qū)域 (ROI) 的檢測(cè),然后分批對(duì) ROI 進(jìn)行進(jìn)一步分類。圖 8 還包括對(duì) Jetson AGX Xavier 未來性能的估計(jì),
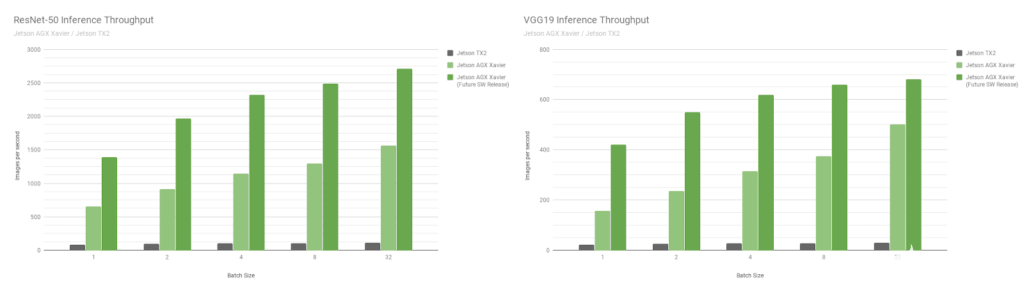
圖 8. INT8 支持 DLA 和其他 GPU 優(yōu)化后的估計(jì)性能
Jetson AGX Xavier 目前在 VGG19 上的吞吐量是 Jetson TX2 的 18 倍,在 ResNet-50 上的吞吐量是在 JetPack 4.1.1 上測(cè)量的 14 倍,如圖 9 所示。ResNet-50 的延遲低至 1.5 毫秒或更高650FPS,批量大小為 1。隨著未來的軟件改進(jìn),Jetson AGX Xavier 估計(jì)比 Jetson TX2 快 24 倍。請(qǐng)注意,對(duì)于舊版比較,我們還在完整的性能列表中提供了 GoogleNet 和 AlexNet 的數(shù)據(jù)。
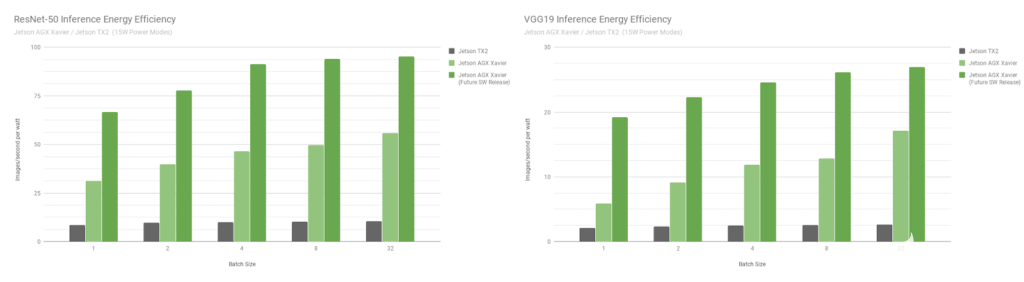
圖 9. Jetson Xavier 和 Jetson TX2 的 ResNet-50 和 VGG19 能效
Jetson AGX Xavier 目前在 VGG19 推理方面的效率是 Jetson TX2 的 7 倍以上,在 ResNet-50 方面的效率提高了 5 倍,在考慮未來的軟件優(yōu)化和增強(qiáng)時(shí)效率提高了 10 倍。有關(guān)推理基準(zhǔn)的更多數(shù)據(jù)和詳細(xì)信息,請(qǐng)參閱完整的性能結(jié)果。我們還將在下一節(jié)中對(duì) CPU 性能進(jìn)行基準(zhǔn)測(cè)試。
卡梅爾 CPU 復(fù)合體
Jetson AGX Xavier 的 CPU 復(fù)合體如圖 10 所示,由四個(gè)基于 ARMv8.2 的異構(gòu)雙核 NVIDIA Carmel CPU 集群組成,最大時(shí)鐘頻率為 2.26GHz。每個(gè)內(nèi)核包括 128KB 指令和 64KB 數(shù)據(jù) L1 緩存以及兩個(gè)內(nèi)核之間共享的 2MB L2 緩存。CPU 集群共享一個(gè) 4MB L3 緩存。

圖 10. 帶有 NVIDIA Carmel 集群的 Jetson Xavier CPU 復(fù)合體的框圖
Carmel CPU 內(nèi)核具有 NVIDIA 的動(dòng)態(tài)代碼優(yōu)化、10 路超標(biāo)量架構(gòu)以及 ARMv8.2 的完整實(shí)現(xiàn),包括完整的高級(jí) SIMD、VFP(矢量浮點(diǎn))和 ARMv8.2-FP16。
SPECint_rate 基準(zhǔn)測(cè)量多核系統(tǒng)的 CPU 吞吐量。總體性能得分平均了幾個(gè)密集的子測(cè)試,包括壓縮、向量和圖形操作、代碼編譯以及為國(guó)際象棋和圍棋等游戲執(zhí)行 AI。圖 11 顯示了幾代 CPU 性能提升超過 2.5 倍的基準(zhǔn)測(cè)試結(jié)果。
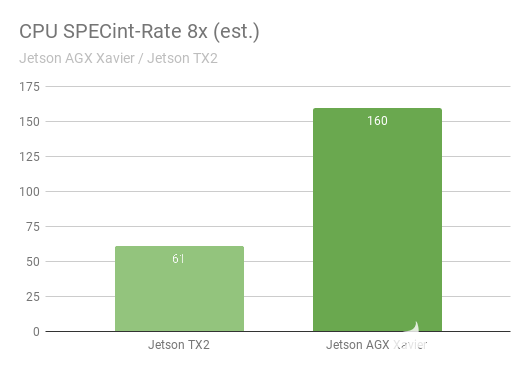
圖 11. SPECInt2K_rate 8x* 基準(zhǔn)測(cè)試中 Jetson AGX Xavier 與 Jetson TX2 的 CPU 性能 *Jetson AGX Xavier / Jetson TX2 SPECint 基準(zhǔn)測(cè)試尚未正式提交給 SPEC,在發(fā)布時(shí)被視為估計(jì)值。
同時(shí)運(yùn)行了 8 個(gè) SPECint_rate 測(cè)試副本,保持 CPU 滿載。Jetson AGX Xavier 自然擁有八個(gè) CPU 核心;Jetson TX2 的架構(gòu)使用四個(gè) Arm Cortex-A57 內(nèi)核和兩個(gè) NVIDIA Denver D15 內(nèi)核。每個(gè) Denver 核心運(yùn)行兩個(gè)副本會(huì)產(chǎn)生更高的性能。
視覺加速器
Jetson AGX Xavier 具有兩個(gè)視覺加速器引擎,如圖 12 所示。每個(gè)引擎都包括一個(gè)雙 7 路 VLIW(超長(zhǎng)指令字)矢量處理器,用于卸載計(jì)算機(jī)視覺算法,例如特征檢測(cè)和匹配、光流、立體視差塊匹配、以及低延遲和低功耗的點(diǎn)云處理。卷積、形態(tài)算子、直方圖、色彩空間轉(zhuǎn)換和扭曲等成像過濾器也是加速的理想選擇。
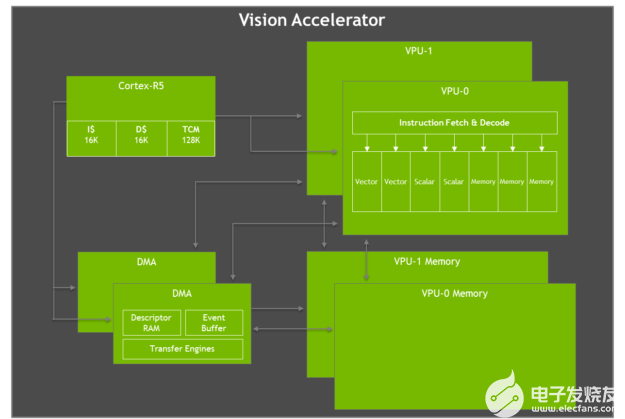
圖 12. Jetson AGX Xavier VLIW 視覺加速器架構(gòu)框圖
每個(gè)視覺加速器包括一個(gè)用于命令和控制的 Cortex-R5 內(nèi)核、兩個(gè)矢量處理單元(每個(gè)都有 192KB 的片上矢量存儲(chǔ)器)和兩個(gè)用于數(shù)據(jù)移動(dòng)的 DMA 單元。7 路向量處理單元包含用于每條指令的兩個(gè)向量、兩個(gè)標(biāo)量和三個(gè)內(nèi)存操作的插槽。Early Access 軟件版本不支持 Vision Accelerator,但將在 JetPack 的未來版本中啟用。
NVIDIA Jetson AGX Xavier 開發(fā)者套件
JetsonAGXXavier 開發(fā)套件包含開發(fā)人員快速啟動(dòng)和運(yùn)行所需的一切該套件包括JetsonAGX Xavier 計(jì)算模塊、參考開源載板、電源和 JetPack SDK,使用戶能夠快速開始開發(fā)應(yīng)用程序。Jetson AGX Xavier 開發(fā)者套件只需 1,299 美元即可購(gòu)買。
Jetson AGX Xavier 開發(fā)工具包的尺寸為 105mm2,明顯小于 Jetson TX1 和 TX2 開發(fā)工具包,同時(shí)改進(jìn)了可用的 I/O。I/O 功能包括兩個(gè) USB3.1 端口(支持 DisplayPort 和 Power Delivery)、一個(gè)混合 eSATAp + USB3.0 端口、一個(gè) PCIe x16 插槽(x8 電氣)、M.2 Key-M NVMe 和 M.2 Key 站點(diǎn)-E WLAN 夾層、千兆以太網(wǎng)、HDMI 2.0 和 8 攝像頭 MIPI CSI 連接器。有關(guān)通過開發(fā)工具包參考載板提供的 I/O 的完整列表,請(qǐng)參見下面的表 3。
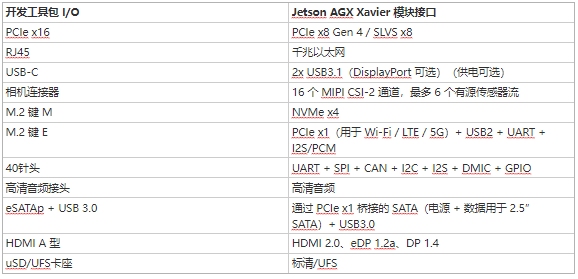
我們?yōu)?Jetson AGX Xavier 整理了一個(gè)開源的為期兩天的深度學(xué)習(xí)演示教程,該教程指導(dǎo)開發(fā)人員通過訓(xùn)練和部署 DNN 推理來執(zhí)行圖像識(shí)別、對(duì)象檢測(cè)和分割,使您能夠快速開始創(chuàng)建自己的 AI應(yīng)用程序。兩天演示使用云端的 NVIDIA DIGITS 交互式訓(xùn)練系統(tǒng)或 GPU 加速的 PC,并使用 TensorRT 對(duì) Jetson 上的圖像或?qū)崟r(shí)攝像頭饋送執(zhí)行加速推理。GitHub 上的為期兩天的演示代碼存儲(chǔ)庫(kù)已更新,包括對(duì) Xavier DLA 和 GPU INT8 精度的支持。
智能視頻分析 (IVA)
人工智能和深度學(xué)習(xí)能夠有效利用大量數(shù)據(jù),讓城市更安全、更方便,包括交通管理、智能停車和零售店的簡(jiǎn)化結(jié)賬體驗(yàn)等應(yīng)用。NVIDIA Jetson 和 NVIDIADeepStream SDK使分布式智能攝像頭能夠在邊緣實(shí)時(shí)執(zhí)行智能視頻分析,從而減少傳輸基礎(chǔ)設(shè)施上的大量帶寬負(fù)載,并提高安全性和匿名性。
在 Jetson AGX Xavier 上運(yùn)行的 IVA 演示視頻捕獲,具有 30 個(gè)并發(fā)高清流
Jetson TX2 可以同時(shí)處理兩個(gè)高清流以及對(duì)象檢測(cè)和跟蹤。如上面的視頻所示,Jetson AGX Xavier 能夠以 1080p30 同時(shí)處理 30 個(gè)獨(dú)立的高清視頻流——提高了 15 倍。Jetson AGX Xavier 提供超過 1850MP/s 的總吞吐量,使其能夠解碼、預(yù)處理、使用基于 ResNet 的檢測(cè)執(zhí)行推理,并在超過 1 毫秒的時(shí)間內(nèi)可視化每一幀。Jetson AGX Xavier 的功能大大提高了邊緣視頻分析的性能和可擴(kuò)展性。
自治的新時(shí)代
Jetson AGX Xavier 提供前所未有的機(jī)載機(jī)器人和智能機(jī)器性能水平。這些系統(tǒng)需要對(duì)人工智能驅(qū)動(dòng)的感知、導(dǎo)航和操作具有苛刻的計(jì)算能力,以提供強(qiáng)大的自主操作。應(yīng)用包括制造、工業(yè)檢測(cè)、精準(zhǔn)農(nóng)業(yè)和家庭服務(wù)。向最終消費(fèi)者遞送包裹并支持倉(cāng)庫(kù)、商店和工廠物流的自主遞送機(jī)器人代表了一類應(yīng)用。
全自動(dòng)交付和物流的典型處理流程需要多個(gè)階段的視覺和感知任務(wù),如圖 14 所示。移動(dòng)交付機(jī)器人通常具有多個(gè)外圍高清攝像頭,除了激光雷達(dá)和其他測(cè)距傳感器之外,還提供 360° 態(tài)勢(shì)感知。與慣性傳感器一起融合在軟件中。經(jīng)常使用前向立體驅(qū)動(dòng)攝像頭,需要預(yù)處理和立體深度映射。NVIDIA 創(chuàng)建了Stereo DNN模型,其準(zhǔn)確性高于傳統(tǒng)的塊匹配方法來支持這一點(diǎn)。
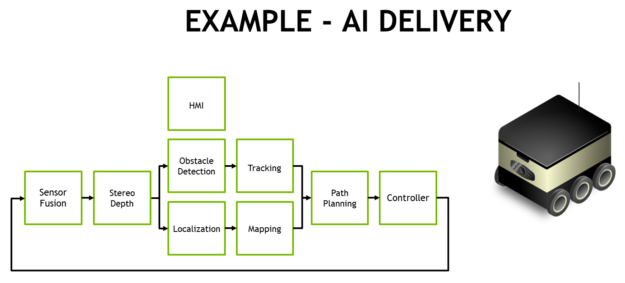
圖 14. 自主配送和物流機(jī)器人的 AI 處理流程示例
SSD 或 Faster-RCNN 等對(duì)象檢測(cè)模型和基于特征的跟蹤通常會(huì)告知行人、車輛和地標(biāo)的避障。對(duì)于倉(cāng)庫(kù)和店面機(jī)器人,這些對(duì)象檢測(cè)模型可以定位感興趣的物品,例如產(chǎn)品、貨架和條形碼。面部識(shí)別、姿勢(shì)估計(jì)和自動(dòng)語音識(shí)別 (ASR) 促進(jìn)了人機(jī)交互 (HMI),使機(jī)器人能夠與人類進(jìn)行有效協(xié)調(diào)和交流。
高幀率同步定位和映射 (SLAM) 對(duì)于保持機(jī)器人在 3D 中準(zhǔn)確定位至關(guān)重要。GPS 本身缺乏亞米級(jí)定位的精度,并且在室內(nèi)無法使用。SLAM 將最新的傳感器數(shù)據(jù)與系統(tǒng)在其點(diǎn)云中積累的先前數(shù)據(jù)進(jìn)行配準(zhǔn)和對(duì)齊。經(jīng)常有噪聲的傳感器數(shù)據(jù)需要大量過濾才能正確定位,尤其是來自移動(dòng)平臺(tái)的數(shù)據(jù)。
路徑規(guī)劃階段通常使用 ResNet-18 FCN、SegNet 或 DeepLab 等語義分割網(wǎng)絡(luò)來執(zhí)行自由空間檢測(cè),告訴機(jī)器人在哪里行駛而不被遮擋。現(xiàn)實(shí)世界中經(jīng)常存在太多需要單獨(dú)檢測(cè)和跟蹤的通用障礙物類型,因此基于分割的方法用其分類標(biāo)記每個(gè)像素或體素。與管道的前幾個(gè)階段一起,這會(huì)通知規(guī)劃者和控制回路它可以采取的安全路線。
Jetson AGX Xavier 的性能和效率使得這些機(jī)器人能夠?qū)崟r(shí)處理所有需要的組件,以實(shí)現(xiàn)完全自主的安全運(yùn)行,包括用于實(shí)時(shí)感知、導(dǎo)航和操作的高性能視覺算法。隨著獨(dú)立的 Jetson AGX Xavier 模塊現(xiàn)已投入生產(chǎn),開發(fā)人員可以將這些 AI 解決方案部署到下一代自主機(jī)器。
立即開始構(gòu)建下一波自主機(jī)器
Jetson AGX Xavier 為機(jī)器人和邊緣設(shè)備帶來了改變游戲規(guī)則的計(jì)算水平,為針對(duì)尺寸、重量和功率進(jìn)行了優(yōu)化的嵌入式平臺(tái)帶來了高端工作站性能。
關(guān)于作者
Dustin 是 NVIDIA Jetson 團(tuán)隊(duì)的一名開發(fā)人員推廣員。Dustin 擁有機(jī)器人技術(shù)和嵌入式系統(tǒng)方面的背景,喜歡在社區(qū)中提供幫助并與 Jetson 合作開展項(xiàng)目。
審核編輯:郭婷
-
機(jī)器人
+關(guān)注
關(guān)注
211文章
28641瀏覽量
208417 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103722
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
研華發(fā)布全系列車載AI控制器,引領(lǐng)智能軌道交通新時(shí)代
交通運(yùn)輸領(lǐng)先企業(yè)率先采用NVIDIA Cosmos平臺(tái)
NVIDIA發(fā)布小巧高性價(jià)比的Jetson Orin Nano Super開發(fā)者套件
NVIDIA 推出高性價(jià)比的生成式 AI 超級(jí)計(jì)算機(jī)

u-blox深化與NVIDIA Jetson和NVIDIA DRIVE Hyperion平臺(tái)合作
使用NVIDIA AI平臺(tái)確保醫(yī)療數(shù)據(jù)安全
初創(chuàng)公司借助NVIDIA Metropolis和Jetson提高生產(chǎn)線效率
使用NVIDIA Jetson打造機(jī)器人導(dǎo)盲犬
使用機(jī)器學(xué)習(xí)和NVIDIA Jetson邊緣AI和機(jī)器人平臺(tái)打造機(jī)器人導(dǎo)盲犬
GPU計(jì)算主板學(xué)習(xí)資料第735篇:基于3U VPX的AGX Xavier GPU計(jì)算主板 信號(hào)計(jì)算主板 視頻處理 相機(jī)信號(hào)
差動(dòng)放大器通常是應(yīng)用在什么場(chǎng)合?
fx3系列的硬件主要由什么組成
NVIDIA JetPack 6.0版本的關(guān)鍵功能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論