 深度學習:神經網絡和函數
深度學習:神經網絡和函數
據報道稱,由于采用基于云的技術和在大數據中使用深度學習系統,深度學習的使用在過去十年中迅速增長,預計到 2028 年,深度學習的市場規模將達到 930 億美元。但究竟什么是深度學習,它是如何工作的?深度學習是機器學習的一個子集,它使用神經網絡來執行學習和預測。深度學習在各種任務中都表現出了驚人的表現,無論是文本、時間序列還是計算機視覺。深度學習的成功主要來自大數據的可用性和計算能力。然而,不僅如此,這使得深度學習遠遠優于任何經典的機器學習算法。
深度學習:神經網絡和函數
神經網絡是一個相互連接的神經元網絡,每個神經元都是一個有限函數逼近器。這樣,神經網絡被視為通用函數逼近器。如果你還記得高中的數學,函數就是從輸入空間到輸出空間的映射。一個簡單的 sin(x) 函數是從角空間(-180° 到 180° 或 0° 到 360°)映射到實數空間(-1 到 1)。 讓我們看看為什么神經網絡被認為是通用函數逼近器。每個神經元學習一個有限的函數:f(.) = g(W*X) 其中 W 是要學習的權重向量,X 是輸入向量,g(.) 是非線性變換。W*X 可以可視化為高維空間(超平面)中的一條線(正在學習),而 g(.) 可以是任何非線性可微函數,如 sigmoid、tanh、ReLU 等(常用于深度學習領域)。在神經網絡中學習無非就是找到最佳權重向量 W。例如,在 y = mx+c 中,我們有 2 個權重:m 和 c。現在,根據 2D 空間中點的分布,我們找到滿足某些標準的 m & c 的最佳值:對于所有數據點,預測 y 和實際點之間的差異最小。
層的效果
現在每個神經元都是一個非線性函數,我們將幾個這樣的神經元堆疊在一個「層」中,每個神經元接收相同的一組輸入但學習不同的權重 W。因此,每一層都有一組學習函數:[f1, f2, …, fn],稱為隱藏層值。這些值再次組合,在下一層:h(f1, f2, ..., fn) 等等。這樣,每一層都由前一層的函數組成(類似于 h(f(g(x))))。已經表明,通過這種組合,我們可以學習任何非線性復函數。 深度學習是具有許多隱藏層(通常 > 2 個隱藏層)的神經網絡。但實際上,深度學習是從層到層的函數的復雜組合,從而找到定義從輸入到輸出的映射的函數。例如,如果輸入是獅子的圖像,輸出是圖像屬于獅子類的圖像分類,那么深度學習就是學習將圖像向量映射到類的函數。類似地,輸入是單詞序列,輸出是輸入句子是否具有正面/中性/負面情緒。因此,深度學習是學習從輸入文本到輸出類的映射:中性或正面或負面。
深度學習作為插值
從生物學的解釋來看,人類通過逐層解釋圖像來處理世界的圖像,從邊緣和輪廓等低級特征到對象和場景等高級特征。神經網絡中的函數組合與此一致,其中每個函數組合都在學習關于圖像的復雜特征。用于圖像的最常見的神經網絡架構是卷積神經網絡 (CNN),它以分層方式學習這些特征,然后一個完全連接的神經網絡將圖像特征分類為不同的類別。 通過再次使用高中數學,給定一組 2D 數據點,我們嘗試通過插值擬合曲線,該曲線在某種程度上代表了定義這些數據點的函數。我們擬合的函數越復雜(例如在插值中,通過多項式次數確定),它就越適合數據;但是,它對新數據點的泛化程度越低。這就是深度學習面臨挑戰的地方,也就是通常所說的過度擬合問題:盡可能地擬合數據,但在泛化方面有所妥協。幾乎所有深度學習架構都必須處理這個重要因素,才能學習在看不見的數據上表現同樣出色的通用功能。 深度學習先驅 Yann LeCun(卷積神經網絡的創造者和 ACM 圖靈獎獲得者)在他的推特上發帖(基于一篇論文):「深度學習并沒有你想象的那么令人印象深刻,因為它僅僅是美化曲線擬合的插值。但是在高維中,沒有插值之類的東西。在高維空間,一切都是外推。」因此,作為函數學習的一部分,深度學習除了插值,或在某些情況下,外推。就這樣!
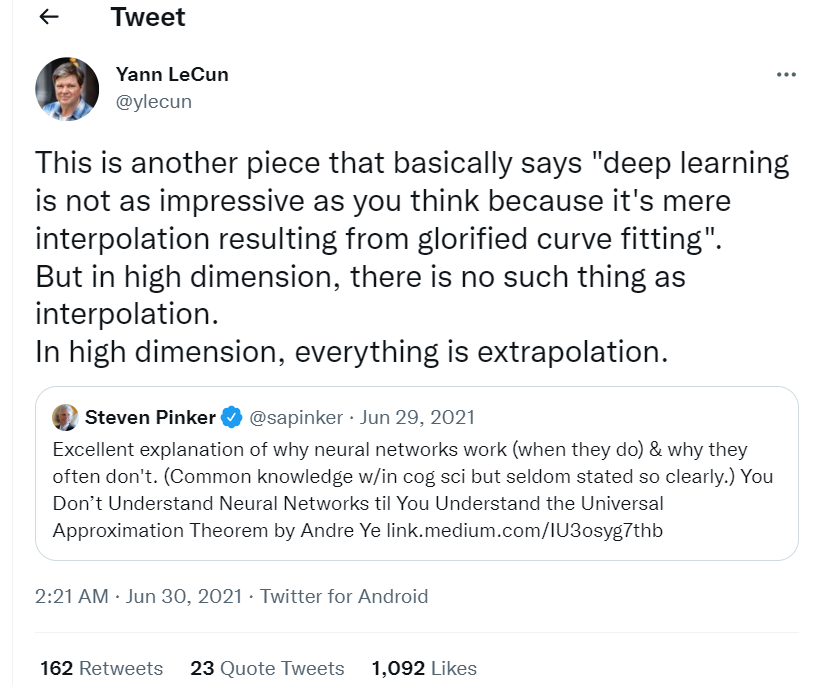
Twitter 地址:https://twitter.com/ylecun/status/1409940043951742981?lang=en
學習方面
那么,我們如何學習這個復雜的函數呢?這完全取決于手頭的問題,而這決定了神經網絡架構。如果我們對圖像分類感興趣,那么我們使用 CNN。如果我們對時間相關的預測或文本感興趣,那么我們使用 RNN 或 Transformer,如果我們有動態環境(如汽車駕駛),那么我們使用強化學習。除此之外,學習還涉及處理不同的挑戰:
確保模型學習通用函數,而不僅僅適合訓練數據;這是通過使用正則化處理的;
根據手頭的問題,選擇損失函數;松散地說,損失函數是我們想要的(真實值)和我們當前擁有的(當前預測)之間的誤差函數;
梯度下降是用于收斂到最優函數的算法;決定學習率變得具有挑戰性,因為當我們遠離最優時,我們想要更快地走向最優,而當我們接近最優時,我們想要慢一些,以確保我們收斂到最優和全局最小值;
大量隱藏層需要處理梯度消失問題;跳過連接和適當的非線性激活函數等架構變化,有助于解決這個問題。
計算挑戰
現在我們知道深度學習只是一個學習復雜的函數,它帶來了其他計算挑戰:
要學習一個復雜的函數,我們需要大量的數據;
為了處理大數據,我們需要快速的計算環境;
我們需要一個支持這種環境的基礎設施。
使用 CPU 進行并行處理不足以計算數百萬或數十億的權重(也稱為 DL 的參數)。神經網絡需要學習需要向量(或張量)乘法的權重。這就是 GPU 派上用場的地方,因為它們可以非常快速地進行并行向量乘法。根據深度學習架構、數據大小和手頭的任務,我們有時需要 1 個 GPU,有時,數據科學家需要根據已知文獻或通過測量 1 個 GPU 的性能來做出決策。 通過使用適當的神經網絡架構(層數、神經元數量、非線性函數等)以及足夠大的數據,深度學習網絡可以學習從一個向量空間到另一個向量空間的任何映射。這就是讓深度學習成為任何機器學習任務的強大工具的原因。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101169 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
深度學習
+關注
關注
73文章
5513瀏覽量
121546
原文標題:這就是深度學習如此強大的原因
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論