 如何優化MySQL百萬數據的深分頁問題
如何優化MySQL百萬數據的深分頁問題
前言
我們日常做分頁需求時,一般會用limit實現,但是當偏移量特別大的時候,查詢效率就變得低下。本文將分四個方案,討論如何優化MySQL百萬數據的深分頁問題,并附上最近優化生產慢SQL的實戰案例。
limit深分頁為什么會變慢?
先看下表結構哈:
CREATETABLEaccount(
idint(11)NOTNULLAUTO_INCREMENTCOMMENT'主鍵Id',
namevarchar(255)DEFAULTNULLCOMMENT'賬戶名',
balanceint(11)DEFAULTNULLCOMMENT'余額',
create_timedatetimeNOTNULLCOMMENT'創建時間',
update_timedatetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新時間',
PRIMARYKEY(id),
KEYidx_name(name),
KEYidx_update_time(update_time)//索引
)ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8ROW_FORMAT=REDUNDANTCOMMENT='賬戶表';
假設深分頁的執行SQL如下:
selectid,name,balancefromaccountwhereupdate_time>'2020-09-19'limit100000,10;
這個SQL的執行時間如下:

執行完需要0.742秒,深分頁為什么會變慢呢?如果換成 limit 0,10,只需要0.006秒哦

我們先來看下這個SQL的執行流程:
- 通過普通二級索引樹idx_update_time,過濾update_time條件,找到滿足條件的記錄ID。
- 通過ID,回到主鍵索引樹,找到滿足記錄的行,然后取出展示的列(回表)
- 掃描滿足條件的100010行,然后扔掉前100000行,返回。
 SQL的執行流程
SQL的執行流程
執行計劃如下:
SQL變慢原因有兩個:
-
limit語句會先掃描offset+n行,然后再丟棄掉前offset行,返回后n行數據。也就是說
limit 100000,10,就會掃描100010行,而limit 0,10,只掃描10行。 -
limit 100000,10掃描更多的行數,也意味著回表更多的次數。
通過子查詢優化
因為以上的SQL,回表了100010次,實際上,我們只需要10條數據,也就是我們只需要10次回表其實就夠了。因此,我們可以通過減少回表次數來優化。
回顧B+ 樹結構
那么,如何減少回表次數呢?我們先來復習下B+樹索引結構哈~
InnoDB中,索引分主鍵索引(聚簇索引)和二級索引
- 主鍵索引,葉子節點存放的是整行數據
- 二級索引,葉子節點存放的是主鍵的值。
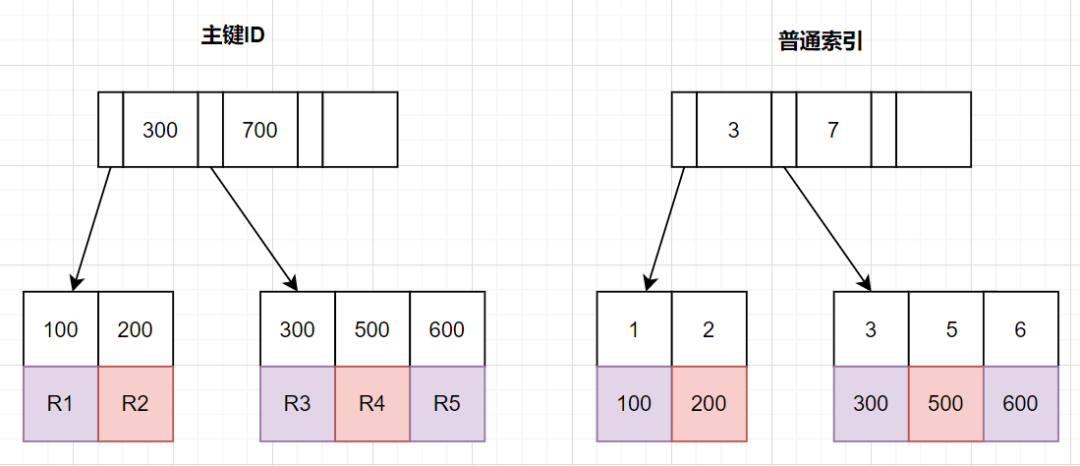
把條件轉移到主鍵索引樹
如果我們把查詢條件,轉移回到主鍵索引樹,那就可以減少回表次數啦。轉移到主鍵索引樹查詢的話,查詢條件得改為主鍵id了,之前SQL的update_time這些條件咋辦呢?抽到子查詢那里嘛~
子查詢那里怎么抽的呢?因為二級索引葉子節點是有主鍵ID的,所以我們直接根據update_time來查主鍵ID即可,同時我們把 limit 100000的條件,也轉移到子查詢,完整SQL如下:
selectid,name,balanceFROMaccountwhereid>=(selecta.idfromaccountawherea.update_time>='2020-09-19'limit100000,1)LIMIT10;寫漏了,可以補下時間條件在外面
查詢效果一樣的,執行時間只需要0.038秒!

我們來看下執行計劃
由執行計劃得知,子查詢 table a查詢是用到了idx_update_time索引。首先在索引上拿到了聚集索引的主鍵ID,省去了回表操作,然后第二查詢直接根據第一個查詢的 ID往后再去查10個就可以了!

因此,這個方案是可以的~
INNER JOIN 延遲關聯
延遲關聯的優化思路,跟子查詢的優化思路其實是一樣的:都是把條件轉移到主鍵索引樹,然后減少回表。不同點是,延遲關聯使用了inner join代替子查詢。
優化后的SQL如下:
SELECTacct1.id,acct1.name,acct1.balanceFROMaccountacct1INNERJOIN(SELECTa.idFROMaccountaWHEREa.update_time>='2020-09-19'ORDERBYa.update_timeLIMIT100000,10)ASacct2onacct1.id=acct2.id;
查詢效果也是杠桿的,只需要0.034秒

執行計劃如下:
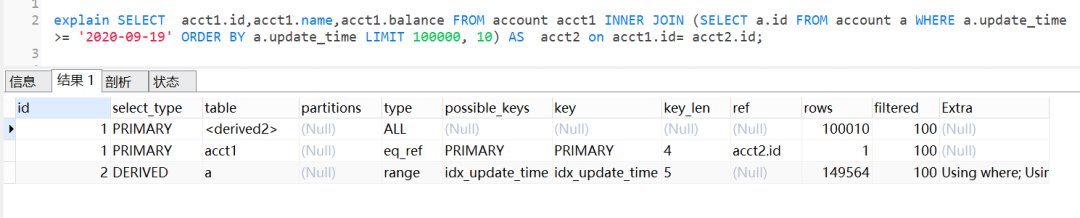
查詢思路就是,先通過idx_update_time二級索引樹查詢到滿足條件的主鍵ID,再與原表通過主鍵ID內連接,這樣后面直接走了主鍵索引了,同時也減少了回表。
標簽記錄法
limit 深分頁問題的本質原因就是:偏移量(offset)越大,mysql就會掃描越多的行,然后再拋棄掉。這樣就導致查詢性能的下降。
其實我們可以采用標簽記錄法,就是標記一下上次查詢到哪一條了,下次再來查的時候,從該條開始往下掃描。就好像看書一樣,上次看到哪里了,你就折疊一下或者夾個書簽,下次來看的時候,直接就翻到啦。
假設上一次記錄到100000,則SQL可以修改為:
selectid,name,balanceFROMaccountwhereid>100000orderbyidlimit10;
這樣的話,后面無論翻多少頁,性能都會不錯的,因為命中了id索引。但是這種方式有局限性:需要一種類似連續自增的字段。
使用between...and...
很多時候,可以將limit查詢轉換為已知位置的查詢,這樣MySQL通過范圍掃描between...and,就能獲得到對應的結果。
如果知道邊界值為100000,100010后,就可以這樣優化:
selectid,name,balanceFROMaccountwhereidbetween100000and100010orderbyid;
手把手實戰案例
我們一起來看一個實戰案例哈。假設現在有表結構如下,并且有200萬數據.
CREATETABLEaccount(
idvarchar(32)COLLATEutf8_binNOTNULLCOMMENT'主鍵',
account_novarchar(64)COLLATEutf8_binNOTNULLDEFAULT''COMMENT'賬號'
amountdecimal(20,2)DEFAULTNULLCOMMENT'金額'
typevarchar(10)COLLATEutf8_binDEFAULTNULLCOMMENT'類型A,B'
create_timedatetimeDEFAULTNULLCOMMENT'創建時間',
update_timedatetimeDEFAULTNULLCOMMENT'更新時間',
PRIMARYKEY(id),
KEY`idx_account_no`(account_no),
KEY`idx_create_time`(create_time)
)ENGINE=InnoDBDEFAULTCHARSET=utf8COLLATE=utf8_binCOMMENT='賬戶表'
業務需求是這樣:獲取最2021年的A類型賬戶數據,上報到大數據平臺。
一般思路的實現方式
很多伙伴接到這么一個需求,會直接這么實現了:
//查詢上報總數量
Integertotal=accountDAO.countAccount();
//查詢上報總數量對應的SQL
'countAccount'resultType="java.lang.Integer">
seelctcount(1)
fromaccount
wherecreate_time>='2021-01-010000'
andtype='A'
//計算頁數
intpageNo=total%pageSize==0?total/pageSize:(total/pageSize+1);
//分頁查詢,上報
for(inti=0;ilist=accountDAO.listAccountByPage(startRow,pageSize);
startRow=(pageNo-1)*pageSize;
//上報大數據
postBigData(list);
}
//分頁查詢SQL(可能存在limit深分頁問題,因為account表數據量幾百萬)
'listAccountByPage'>
seelct*
fromaccount
wherecreate_time>='2021-01-010000'
andtype='A'
limit#{startRow},#{pageSize}
實戰優化方案
以上的實現方案,會存在limit深分頁問題,因為account表數據量幾百萬。那怎么優化呢?
其實可以使用標簽記錄法,有些伙伴可能會有疑惑,id主鍵不是連續的呀,真的可以使用標簽記錄?
當然可以,id不是連續,我們可以通過order by讓它連續嘛。優化方案如下:
//查詢最小ID
StringlastId=accountDAO.queryMinId();
//查詢最小ID對應的SQL
"queryMinId"returnType=“java.lang.String”>
selectMIN(id)
fromaccount
wherecreate_time>='2021-01-010000'
andtype='A'
//一頁的條數
IntegerpageSize=100;
Listlist;
do{
list=listAccountByPage(lastId,pageSize);
//標簽記錄法,記錄上次查詢過的Id
lastId=list.get(list,size()-1).getId();
//上報大數據
postBigData(list);
}while(CollectionUtils.isNotEmpty(list));
"listAccountByPage">
select*
fromaccount
wherecreate_time>='2021-01-010000'
andid>#{lastId}
andtype='A'
orderbyidasc
limit#{pageSize}
-
SQL
+關注
關注
1文章
775瀏覽量
44254 -
MySQL
+關注
關注
1文章
829瀏覽量
26744
原文標題:聊聊如何解決 MySQL 深分頁問題
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從Delphi、C++ Builder和Lazarus連接到MySQL數據庫
使用插件將Excel連接到MySQL/MariaDB
適用于MySQL和MariaDB的Python連接器:可靠的MySQL數據連接器和數據庫
MySQL數據庫的安裝

數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
什么是虛擬內存分頁 Windows系統虛擬內存優化方法
MySQL還能跟上PostgreSQL的步伐嗎

香港云服務器怎么部署MySQL數據庫?
MySQL編碼機制原理
適用于MySQL的dbForge架構比較
MySQL性能優化淺析及線上案例
華納云:如何修改MySQL的默認端口

MySQL的整體邏輯架構





 工商網監
工商網監
評論