") 在機器學習領域,數(shù)據(jù)和模型哪個更重要
在機器學習領域,數(shù)據(jù)和模型哪個更重要
在機器學習領域,數(shù)據(jù)重要還是模型重要?這是一個很難回答的問題。
模型和數(shù)據(jù)是 AI 系統(tǒng)的基礎,這兩個組件在模型的開發(fā)中扮演著重要的角色。
人工智能領域最權威的學者之一吳恩達曾提出「80% 的數(shù)據(jù) + 20% 的模型 = 更好的機器學習」,他認為一個團隊研究 80% 的工作應該放在數(shù)據(jù)準備上,數(shù)據(jù)質量是重要的,但很少有人在乎。如果更多地強調以數(shù)據(jù)為中心而不是以模型為中心,機器學習會發(fā)展的更快。
我們不禁會問,機器學習的進步是模型帶來的還是數(shù)據(jù)帶來的,目前還沒有一個明確的答案。
在本文中,Android 開發(fā)者和機器學習愛好者 Harshil Patel 介紹了「機器學習:以數(shù)據(jù)為中心 VS 以模型為中心」,通過對比以確定兩者中哪個更重要,此外,Patel 還介紹了如何使用以數(shù)據(jù)為中心的基礎設施。
以數(shù)據(jù)為中心的方法 VS 以模型為中心的方法
以模型為中心的方法意味著需要通過實驗來提高機器學習模型性能,這涉及模型架構的選擇、訓練過程。而在以模型為中心的方法中,你需要保持數(shù)據(jù)相同,通過改進代碼和模型架構來提高性能。此外,對代碼的改進是以模型為中心的根本目標。
目前,大多數(shù) AI 應用都是以模型為中心的,其中一個可能的原因是學術研究非常重視 AI 領域。根據(jù)吳恩達的說法,AI 領域 90% 以上的研究論文都是以模型為中心的,因為我們很難創(chuàng)建大型數(shù)據(jù)集,使其成為公認的標準。因此,AI 社區(qū)認為以模型為中心的機器學習更有前景。研究者在專注于模型的同時,往往會忽略數(shù)據(jù)的重要性。
對于研究者而言,數(shù)據(jù)是每個決策過程的核心,以數(shù)據(jù)為中心的公司通過使用其運營產(chǎn)生的信息,可以獲得更準確、更有條理、更透明的結果,從而可以幫助公司組織更順利地運行。以數(shù)據(jù)為中心的方法涉及系統(tǒng)地改進、改進數(shù)據(jù)集,以提高 ML 應用程序的準確性,對數(shù)據(jù)進行處理是以數(shù)據(jù)為中心的中心目標。
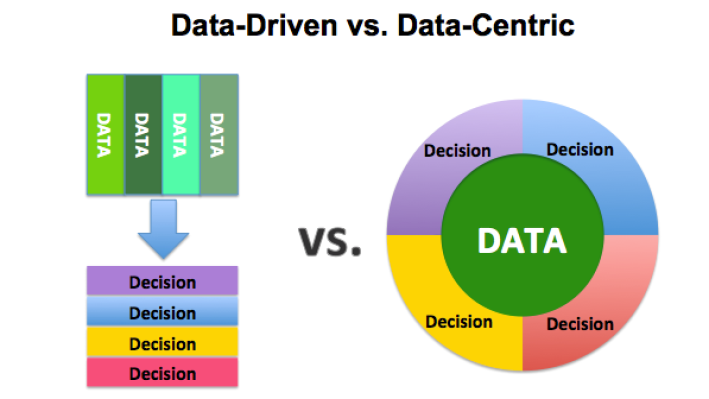
數(shù)據(jù)驅動 VS 以數(shù)據(jù)為中心
許多人經(jīng)常混淆「以數(shù)據(jù)為中心」和「數(shù)據(jù)驅動」這兩個概念。數(shù)據(jù)驅動是一種從數(shù)據(jù)中收集、分析和提取見解的方法,它有時被稱為「分析」。另一方面,以數(shù)據(jù)為中心的方法側重于使用數(shù)據(jù)來定義應該首先創(chuàng)建的內(nèi)容;而以數(shù)據(jù)為中心的架構指的是一個系統(tǒng),其中數(shù)據(jù)是主要和永久的資產(chǎn)。數(shù)據(jù)驅動架構意味著通過利用大量數(shù)據(jù)來創(chuàng)建技術、技能和環(huán)境。
對于數(shù)據(jù)科學家和機器學習工程師來說,以模型為中心的方法似乎更受歡迎。這是因為從業(yè)者可以利用自身知識儲備來解決特定問題。另一方面,沒有人愿意花大量時間去標注數(shù)據(jù)。
然而,在當今的機器學習中,數(shù)據(jù)至關重要,但在 AI 發(fā)展中卻經(jīng)常被忽視和處理不當。由于數(shù)據(jù)錯誤,研究者可能花費大量時間進行查錯。模型精度較低的根本原因可能不是來自模型本身,而是來自錯誤的數(shù)據(jù)集。

除了關注數(shù)據(jù)外,模型和代碼也很重要。但研究者往往傾向于在關注模型的同時忽略數(shù)據(jù)的重要性。最好的方法是同時關注數(shù)據(jù)和模型的混合方法。根據(jù)應用程序的不同,研究者應該兼顧數(shù)據(jù)和模型。
以數(shù)據(jù)為中心的基礎架構
以模型為中心的機器學習系統(tǒng)主要關注模型架構優(yōu)化及其參數(shù)優(yōu)化。
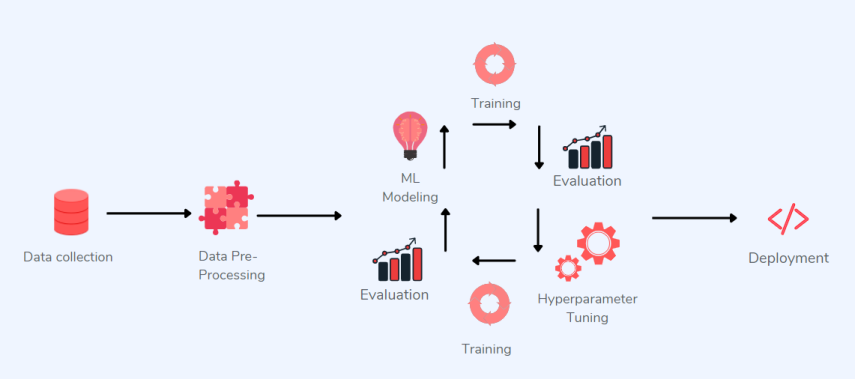
以模型為中心的 ML 應用程序
上圖中描述的是以模型為中心的工作流適用于少數(shù)行業(yè),如媒體、廣告、醫(yī)療保健或制造業(yè)。但也可能面臨如下挑戰(zhàn):
需要高級定制系統(tǒng):不同于媒體和廣告行業(yè),許多企業(yè)無法使用單一的機器學習系統(tǒng)來檢測其產(chǎn)品的生產(chǎn)故障。雖然媒體公司可以負擔得起有一個完整的 ML 部門來處理優(yōu)化問題,但需要多個 ML 解決方案的制造企業(yè)不能按照這樣的模板進行實施;
大型數(shù)據(jù)集的重要性:在大多數(shù)情況下,公司沒有大量數(shù)據(jù)可供使用。相反,他們經(jīng)常被迫處理微小的數(shù)據(jù)集,如果他們的方法是以模型為中心的,那么這些數(shù)據(jù)集很容易產(chǎn)生令人失望的結果。
吳恩達曾在他的 AI 演講中解釋了他如何相信以數(shù)據(jù)為中心的 ML 更有價值,并倡導社區(qū)朝著以數(shù)據(jù)為中心的方向發(fā)展。他曾經(jīng)舉了一個「鋼鐵缺陷檢測」的例子,其中以模型為中心的方法未能提高模型的準確率,而以數(shù)據(jù)為中心的方法將準確率提高了 16%。
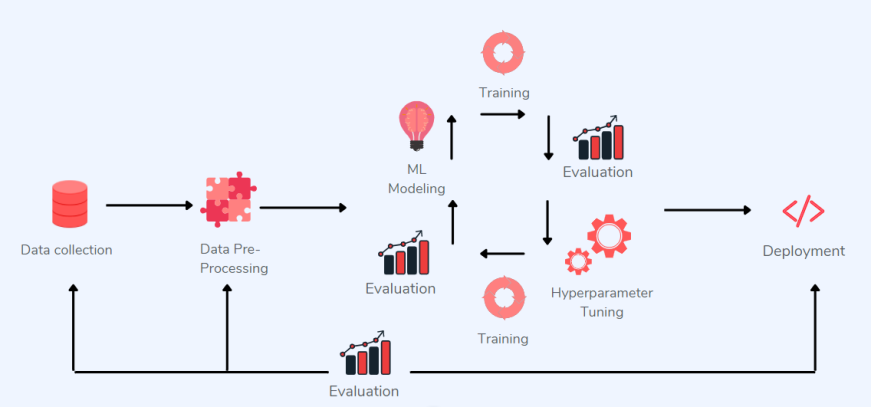
以數(shù)據(jù)為中心的 ML 應用程序
在實施以數(shù)據(jù)為中心的架構時,可以將數(shù)據(jù)視為比應用程序和基礎架構更耐用的基本資產(chǎn)。以數(shù)據(jù)為中心的 ML 使數(shù)據(jù)共享和移動變得簡單。那么,在以數(shù)據(jù)為中心的機器學習到底涉及什么?在實現(xiàn)以數(shù)據(jù)為中心的方法時,我們應該考慮以下因素:
數(shù)據(jù)標簽質量:當大量的圖像被錯誤標記時,會出現(xiàn)意想不到的錯誤,因此需要提高數(shù)據(jù)標注質量;
數(shù)據(jù)增強:讓有限的數(shù)據(jù)產(chǎn)生更多的數(shù)據(jù),增加訓練樣本的數(shù)量以及多樣性(噪聲數(shù)據(jù)),提升模型穩(wěn)健性;
特征工程:通過改變輸入數(shù)據(jù)、先驗知識或算法向模型添加特征,常被用于機器學習,以幫助提高預測模型的準確性;
數(shù)據(jù)版本控制:開發(fā)人員通過比較兩個版本來跟蹤錯誤并查看沒有意義的內(nèi)容,數(shù)據(jù)版本控制是維護數(shù)據(jù)中最不可或缺的步驟之一,它可以幫助研究者跟蹤數(shù)據(jù)集的更改(添加和刪除),版本控制使代碼協(xié)作和數(shù)據(jù)集管理變得更加容易;
領域知識:在以數(shù)據(jù)為中心的方法中,領域知識非常有價值。領域專家通常可以檢測到 ML 工程師、數(shù)據(jù)科學家和標注人員無法檢測到的細微差異,ML 系統(tǒng)中仍然缺少涉及領域專家的內(nèi)容。如果有額外的領域知識可用,ML 系統(tǒng)可能會表現(xiàn)得更好。
應該優(yōu)先考慮哪一個:數(shù)據(jù)數(shù)量還是數(shù)據(jù)質量?
需要強調的是,數(shù)據(jù)量多并不等同于數(shù)據(jù)質量好。當然,訓練神經(jīng)網(wǎng)絡不能只用幾張圖就能完成,數(shù)據(jù)數(shù)量是一個方面,但現(xiàn)在的重點是質量而不是數(shù)量。
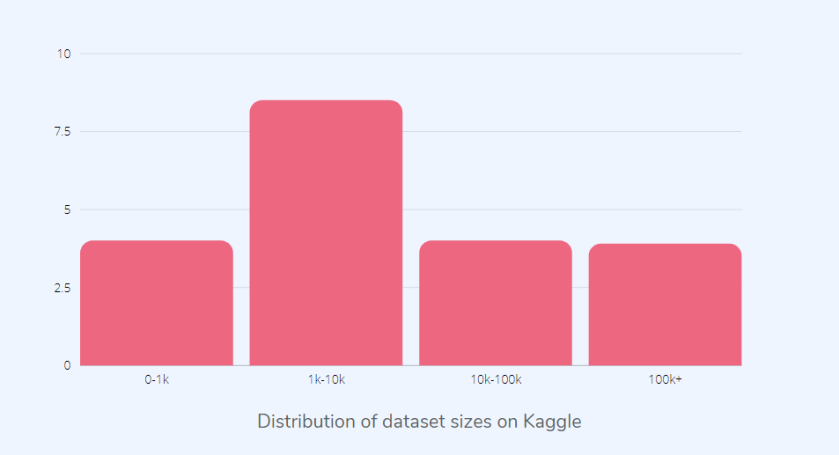
如上圖所示,大多數(shù) Kaggle 數(shù)據(jù)集并沒有那么大。在以數(shù)據(jù)為中心的方法中,數(shù)據(jù)集的大小并不那么重要,并且可以使用質量較小的數(shù)據(jù)集完成更多的工作。不過需要注意的是,數(shù)據(jù)質量高且標注正確。
上圖中是另一種標注數(shù)據(jù)的方式,單獨或組合標注。例如,如果數(shù)據(jù)科學家 1 單獨標注菠蘿,而數(shù)據(jù)科學家 2 將其組合標注,則兩者標注的數(shù)據(jù)不兼容,導致學習算法變得混亂。因此,需要將數(shù)據(jù)標簽保持一致;如果需要單獨標注,請確保所有標注都以相同的方式進行。

上圖為吳恩達解釋了小數(shù)據(jù)集一致性的重要性
到底需要多少數(shù)據(jù)?
數(shù)據(jù)質量不可忽視,但數(shù)據(jù)量也是至關重要的,研究者必須有足夠的數(shù)據(jù)支撐才能解決問題。深度網(wǎng)絡具有低偏差、高方差特性,我們可以預見更多的數(shù)據(jù)可以解決方差問題。但是多少數(shù)據(jù)才夠呢?目前這個問題還很難回答,不過我們可以認為擁有大量的數(shù)據(jù)是一種優(yōu)勢,但也不是必須的。
如果你采用以數(shù)據(jù)為中心的方法,請記住以下幾點:
確保在整個 ML 項目周期中數(shù)據(jù)保持一致;
數(shù)據(jù)標注保持一致;
要及時反饋結果;
進行錯誤分析;
消除噪聲樣本。
那么,我們哪里可以找到高質量的數(shù)據(jù)集?這里推薦幾個網(wǎng)站,首先是 Kaggle:在 Kaggle 中,你會找到進行數(shù)據(jù)科學工作所需的所有代碼和數(shù)據(jù),Kaggle 擁有超過 50,000 個公共數(shù)據(jù)集和 400,000 個公共 notebook,可以快速完成任務。
其次是 Datahub.io:Datahub 是一個主要專注于商業(yè)和金融的數(shù)據(jù)集平臺。許多數(shù)據(jù)集,例如國家、人口和地理邊界列表,目前在 DataHub 上可用。
最后是 Graviti Open Datasets:Graviti 是一個新的數(shù)據(jù)平臺,主要為計算機視覺提供高質量的數(shù)據(jù)集。個人開發(fā)人員或組織可以輕松訪問、共享和更好地管理開放數(shù)據(jù)。
原文標題:90%論文都是以模型為中心,AI領域,數(shù)據(jù)和模型到底哪個重要?
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
數(shù)據(jù)
+關注
關注
8文章
7145瀏覽量
89584 -
AI
+關注
關注
87文章
31536瀏覽量
270348 -
模型
+關注
關注
1文章
3313瀏覽量
49232
原文標題:90%論文都是以模型為中心,AI領域,數(shù)據(jù)和模型到底哪個重要?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論