") 命名實體識別實踐 - CRF
命名實體識別實踐 - CRF
1
條件隨機(jī)場-CRF
CRF,英文全稱為Conditional Random Field, 中文名為條件隨機(jī)場,是給定一組輸入隨機(jī)變量條件下另一組輸出隨機(jī)變量的條件概率分布模型,其特點是假設(shè)輸出隨機(jī)變量構(gòu)成馬爾可夫(Markov)隨機(jī)場。
較為簡單的條件隨機(jī)場是定義在線性鏈上的條件隨機(jī)場,稱為線性鏈條件隨機(jī)場(linear chain conditional random field)。
線性鏈條件隨機(jī)場可以用于序列標(biāo)注等問題,需要解決的命名實體識別(NER)任務(wù)正好可通過序列標(biāo)注方法解決。
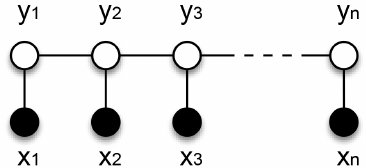
在條件概率模型P(Y|X)中,Y是輸出變量,表示標(biāo)記序列(或狀態(tài)序列),X是輸入變量,表示需要標(biāo)注的觀測序列。
訓(xùn)練時,利用訓(xùn)練數(shù)據(jù)集通過極大似然估計或正則化的極大似然估計得到條件概率模型p(Y|X); 預(yù)測時,對于給定的輸入序列x,求出條件概率p(y|x)最大的輸出序列y
利用線性鏈CRF來做實體識別的時候,需要假設(shè)每個標(biāo)簽 的預(yù)測同時依賴于先前預(yù)測的標(biāo)簽 和 的詞語輸入序列,如下圖所示 每個 NER標(biāo)簽僅依賴于其直接前前繼和后繼標(biāo)簽以及 x
每個 NER標(biāo)簽僅依賴于其直接前前繼和后繼標(biāo)簽以及 x
CRF是一種選擇因子的特定方式,換句話說,就是特征函數(shù)。定義因子的 CRF 方法是采用實值特征函數(shù) 與參數(shù) 和 的線性組合的指數(shù),下面是特征函數(shù)與權(quán)重參數(shù)在時間步上是對應(yīng)的:
關(guān)于Linear-chain CRF的訓(xùn)練推導(dǎo),可以查看文章:條件隨機(jī)場CRF(一)從隨機(jī)場到線性鏈條件隨機(jī)場
2
實踐1:基于CRF++實現(xiàn)NER
CRF++簡介
CRF++是著名的條件隨機(jī)場的開源工具,也是目前綜合性能最佳的CRF工具,采用C++語言編寫而成。其最重要的功能我認(rèn)為是采用了特征模板。這樣就可以自動生成一系列的特征函數(shù),而不用我們自己生成特征函數(shù),我們要做的就是尋找特征,比如詞性等。 官網(wǎng)地址:http://taku910.github.io/crfpp/
官網(wǎng)地址:http://taku910.github.io/crfpp/
安裝
CRF++的安裝可分為Windows環(huán)境和Linux環(huán)境下的安裝。關(guān)于Linux環(huán)境下的安裝,可以參考文章:CRFPP/CRF++編譯安裝與部署 。在Windows中CRF++不需要安裝,下載解壓CRF++0.58文件即可以使用
訓(xùn)練語料創(chuàng)建
在訓(xùn)練之前需要將標(biāo)注數(shù)據(jù)轉(zhuǎn)化為CRF++訓(xùn)練格式文件:
分兩列,第一列是字符,第二例是對應(yīng)的標(biāo)簽,中間用 分割。
比如標(biāo)注方案采用BISO,效果如下:

模板
模板是使用CRF++的關(guān)鍵,它能幫助我們自動生成一系列的特征函數(shù),而不用我們自己生成特征函數(shù),而特征函數(shù)正是CRF算法的核心概念之一。一個簡單的模板文件如下: 在這里,我們需要好好理解下模板文件的規(guī)則。T**:%x[#,#]中的T表示模板類型,兩個"#"分別表示相對的行偏移與列偏移。一共有兩種模板:
在這里,我們需要好好理解下模板文件的規(guī)則。T**:%x[#,#]中的T表示模板類型,兩個"#"分別表示相對的行偏移與列偏移。一共有兩種模板:
訓(xùn)練
crf_learn-f3-c4.0-m100templatetrain.datacrf_model>train.rst
其中,template為模板文件,train.data為訓(xùn)練語料,-t表示可以得到一個model文件和一個model.txt文件,其他可選參數(shù)說明如下:
-f,–freq=INT使用屬性的出現(xiàn)次數(shù)不少于INT(默認(rèn)為1) -m,–maxiter=INT設(shè)置INT為LBFGS的最大迭代次數(shù)(默認(rèn)10k) -c,–cost=FLOAT設(shè)置FLOAT為代價參數(shù),過大會過度擬合(默認(rèn)1.0) -e,–eta=FLOAT設(shè)置終止標(biāo)準(zhǔn)FLOAT(默認(rèn)0.0001) -C,–convert將文本模式轉(zhuǎn)為二進(jìn)制模式 -t,–textmodel為調(diào)試建立文本模型文件 -a,–algorithm=(CRF|MIRA)選擇訓(xùn)練算法,默認(rèn)為CRF-L2 -p,–thread=INT線程數(shù)(默認(rèn)1),利用多個CPU減少訓(xùn)練時間 -H,–shrinking-size=INT設(shè)置INT為最適宜的跌代變量次數(shù)(默認(rèn)20) -v,–version顯示版本號并退出 -h,–help顯示幫助并退出
輸出信息
iter:迭代次數(shù)。當(dāng)?shù)螖?shù)達(dá)到maxiter時,迭代終止 terr:標(biāo)記錯誤率 serr:句子錯誤率 obj:當(dāng)前對象的值。當(dāng)這個值收斂到一個確定值的時候,訓(xùn)練完成 diff:與上一個對象值之間的相對差。當(dāng)此值低于eta時,訓(xùn)練完成
預(yù)測
在訓(xùn)練完模型后,我們可以使用訓(xùn)練好的模型對新數(shù)據(jù)進(jìn)行預(yù)測,預(yù)測命令格式如下:
crf_test-mcrf_modeltest.data>test.rstt
-m model表示使用我們剛剛訓(xùn)練好的model模型,預(yù)測的數(shù)據(jù)文件為test.data> test.rstt 表示將預(yù)測后的數(shù)據(jù)寫入到test.rstt 中。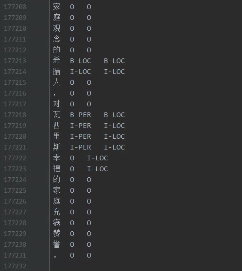
3
實踐2:基于sklearn_crfsuite實現(xiàn)NER
sklearn_crfsuite簡介
sklearn-crfsuite是基于CRFsuite庫的一款輕量級的CRF庫。該庫兼容sklearn的算法,因此可以結(jié)合sklearn庫的算法設(shè)計實體識別系統(tǒng)。sklearn-crfsuite不僅提供了條件隨機(jī)場的訓(xùn)練和預(yù)測方法還提供了評測方法。
https://sklearn-crfsuite.readthedocs.io/en/latest/#
安裝:pip install sklearn-crfsuite
特征與模型創(chuàng)建
特征構(gòu)造: 模型初始化
模型初始化
crf_model=sklearn_crfsuite.CRF(algorithm='lbfgs',c1=0.25,c2=0.018,max_iterations=100, all_possible_transitions=True,verbose=True) crf_model.fit(X_train,y_train)
完整代碼如下:
importre importsklearn_crfsuite fromsklearn_crfsuiteimportmetrics importjoblib importyaml importwarnings warnings.filterwarnings('ignore') defload_data(data_path): data=list() data_sent_with_label=list() withopen(data_path,mode='r',encoding="utf-8")asf: forlineinf: ifline.strip()=="": data.append(data_sent_with_label.copy()) data_sent_with_label.clear() else: data_sent_with_label.append(tuple(line.strip().split(""))) returndata defword2features(sent,i): word=sent[i][0] features={ 'bias':1.0, 'word':word, 'word.isdigit()':word.isdigit(), } ifi>0: word1=sent[i-1][0] words=word1+word features.update({ '-1:word':word1, '-1:words':words, '-1:word.isdigit()':word1.isdigit(), }) else: features['BOS']=True ifi>1: word2=sent[i-2][0] word1=sent[i-1][0] words=word1+word2+word features.update({ '-2:word':word2, '-2:words':words, '-3:word.isdigit()':word1.isdigit(), }) ifi>2: word3=sent[i-3][0] word2=sent[i-2][0] word1=sent[i-1][0] words=word1+word2+word3+word features.update({ '-3:word':word3, '-3:words':words, '-3:word.isdigit()':word1.isdigit(), }) ifi
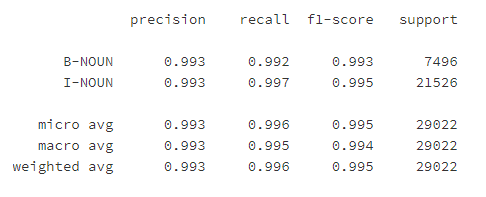
訓(xùn)練效果如下:
labels=list(crf_model.classes_) labels.remove("O") y_pred=crf_model.predict(X_dev) metrics.flat_f1_score(y_dev,y_pred, average='weighted',labels=labels) sorted_labels=sorted(labels,key=lambdaname:(name[1:],name[0])) print(metrics.flat_classification_report( y_dev,y_pred,labels=sorted_labels,digits=3 ))完整代碼 https://www.heywhale.com/home/competition/6216f74572960d0017d5e691/content/
審核編輯 :李倩
發(fā)布評論請先 登錄
相關(guān)推薦
做ADS解碼專用 實踐ADS1605
貼片共模電感的命名規(guī)格、特征及應(yīng)用
臺灣華科貼片電容的命名及封裝
風(fēng)華貼片瓷介電容型號識別及命名方法

GaN晶體管的命名、類型和結(jié)構(gòu)


三星電容命名規(guī)則,了解三星電容參數(shù) 知識篇
nlp自然語言處理的主要任務(wù)及技術(shù)方法
llm模型有哪些格式
剛剛,美國再拉黑37家中國實體!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論