") AI將如何重振摩爾定律的良性循環(huán)
AI將如何重振摩爾定律的良性循環(huán)
在這篇文章中,天數(shù)智芯首席技術(shù)官呂堅(jiān)平(CP Lu)博士闡述了當(dāng)今AI硬件淵源,跳脫過去芯片設(shè)計(jì)窠臼,以可微分GPU及可微分ISP為例,提倡以AI為本的可微分硬件理念。希望借此可重振軟硬件彼此加持的雄風(fēng),緩解甚至逆轉(zhuǎn)摩爾定律的衰退。
INNOVATIONS
人工智能將如何重振摩爾定律的良性循環(huán)
據(jù)報(bào)道,正值全球芯片短缺之際,臺(tái)積電提高了芯片價(jià)格并推遲了3nm制程的生產(chǎn)進(jìn)程。無論這類新聞是否準(zhǔn)確或預(yù)示著一種長期趨勢,它們都在提醒我們,摩爾定律的衰退將帶來越來越嚴(yán)重的影響,并迫使我們重新思考人工智能硬件——它會(huì)受到這種衰退的影響,還是會(huì)幫助扭轉(zhuǎn)這種趨勢?
如果我們希望恢復(fù)摩爾定律(Moore’s Law)的良性循環(huán),這其中,軟件和硬件曾經(jīng)相互加持,使一部現(xiàn)代智能手機(jī)比過去10年占據(jù)整個(gè)倉庫的超級(jí)計(jì)算機(jī)功能更強(qiáng)大。人們普遍接受后摩爾時(shí)代的良性循環(huán)是基于更大的數(shù)據(jù)迸發(fā)更大的模型并需要更強(qiáng)大的機(jī)器。但事實(shí)上,這樣的循環(huán)是不可持續(xù)的。
除非我們重新定義并行性,我們不能再指望縮小晶體管來制造越來越寬的并行處理器。我們也不能依賴于它,除非特定領(lǐng)域架構(gòu)(DSA)有助于促進(jìn)及適應(yīng)軟件的發(fā)展。
與其搞清楚哪類硬件是用于 AI 這個(gè)不斷發(fā)展的移動(dòng)目標(biāo),我們不如從AI以可微分編程為核心的角度來看待AI 硬件。這樣說,人工智能軟件程序是一個(gè)計(jì)算圖,由一起訓(xùn)練實(shí)現(xiàn)端到端目標(biāo)的計(jì)算節(jié)點(diǎn)組成。只要一個(gè)深度線程DSA硬件是可微的,它就可以作為一個(gè)計(jì)算節(jié)點(diǎn)。軟件程序員可以自由地將可微硬件插入計(jì)算圖中,以實(shí)現(xiàn)高性能和以創(chuàng)意解決問題,就像預(yù)構(gòu)建的可定制軟件組件一樣。AI 硬件不應(yīng)再有“血統(tǒng)純正度”審查,畢竟它現(xiàn)在可以包括各樣可微硬件。
但愿這樣,軟件和硬件將再次通過良性循環(huán)并行發(fā)展,就像摩爾定律盛行時(shí)那樣。
人工智能硬件架構(gòu)師的苦惱
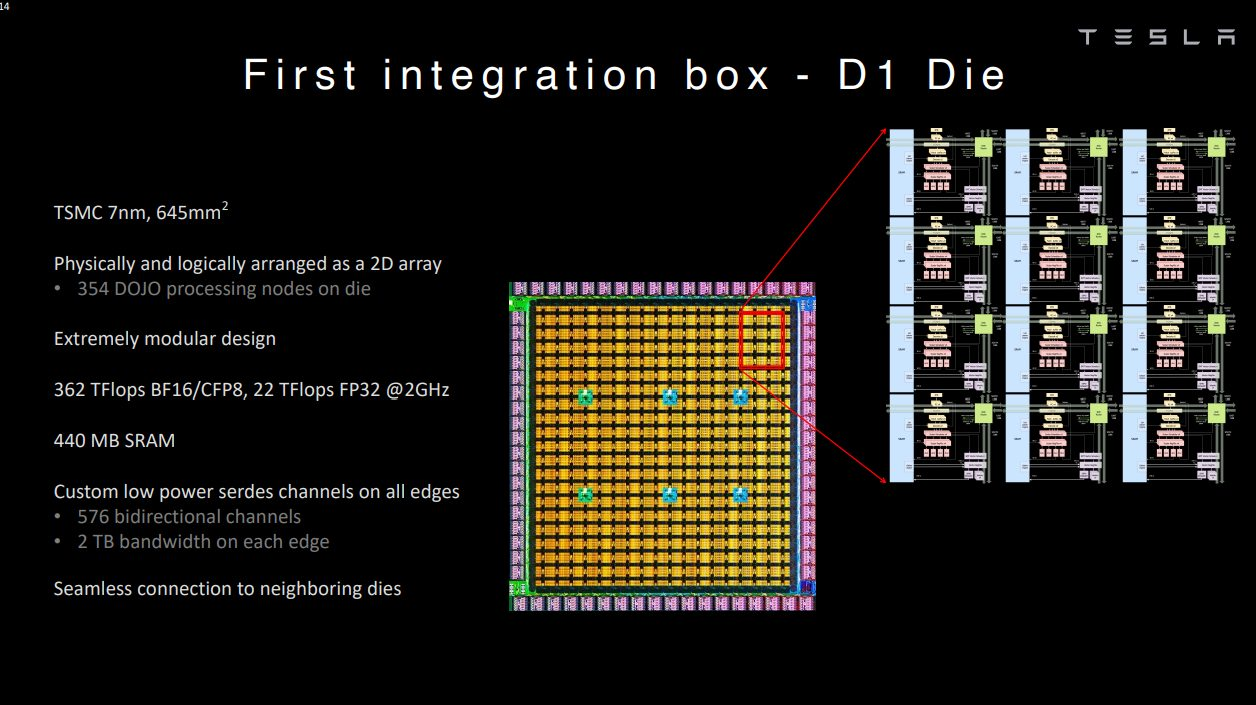
在人工智能市場的眾多GPU競爭者中,特斯拉推出了Dojo超級(jí)計(jì)算機(jī)。Dojo似乎是網(wǎng)絡(luò)、集成和可延展性方面的杰作。而另一方面,Dojo 的組件 D1 芯片則稱不上是架構(gòu)上的突破。我們可以將GPU競爭者分為兩個(gè)陣營,Many-Core 和Many-MAC。D1是Many-Core陣營的一個(gè)例子,它是將多個(gè)CPU核心連接起來的“網(wǎng)格”。另一方面,特斯拉FSD或谷歌TPU是Many-MAC陣營的縮影,其特點(diǎn)是少量大型矩陣乘法(MM)加速器,每個(gè)都在一個(gè)“網(wǎng)格”中封裝許多乘累積(MAC)單元。正如我們所看到的,關(guān)于AI架構(gòu)的爭論可以說是處于網(wǎng)格和GPU之間。
在制造芯片帶來的飛速增長的沖力下,AI硬件架構(gòu)師面對(duì)著巨大壓力,總是膽戰(zhàn)心驚的看待媒體對(duì)基準(zhǔn)測試和學(xué)術(shù)大會(huì)的報(bào)導(dǎo)。人工智能硬件常常跑不動(dòng)基準(zhǔn)測試和最新出爐的NN模型,而諷刺的是,這些模型在所謂“老掉牙”的GPU上,卻運(yùn)行良好。如下圖所示,Many-Core和GPU本質(zhì)上只是數(shù)據(jù)交換方式有所不同。前者通過一個(gè)互聯(lián)的網(wǎng)格傳遞數(shù)據(jù),而后者通過一個(gè)存儲(chǔ)器層次結(jié)構(gòu)共享數(shù)據(jù)。這種差異與人工智能沒有什么關(guān)系。Many-Core芯片(如D1芯片)是否最終會(huì)超過GPU,還有待觀察,稍后我將介紹Many-MAC 。
現(xiàn)在,讓我們快速回顧一下網(wǎng)格和GPU在高性能計(jì)算(HPC)中的共同根源。
HPC的傳承
HPC用于解決計(jì)算密集的如軍事研究、科學(xué)發(fā)現(xiàn)、油氣勘探等問題。超級(jí)計(jì)算機(jī)(簡稱超算)一直是高性能計(jì)算的關(guān)鍵硬件解決方案。與處理指針豐富的數(shù)據(jù)結(jié)構(gòu)(如樹和鏈表)的通用程序相比,HPC程序主要花時(shí)間在“回圈”中重復(fù)數(shù)據(jù)并行計(jì)算。
矢量超算的興衰
在20世紀(jì)70年代和90年代,矢量超算,通過將數(shù)據(jù)并行回圈展開成矢量來加速高性能計(jì)算程序,主導(dǎo)了高性能計(jì)算市場。在那期間,矢量超算等同于超級(jí)計(jì)算機(jī)。
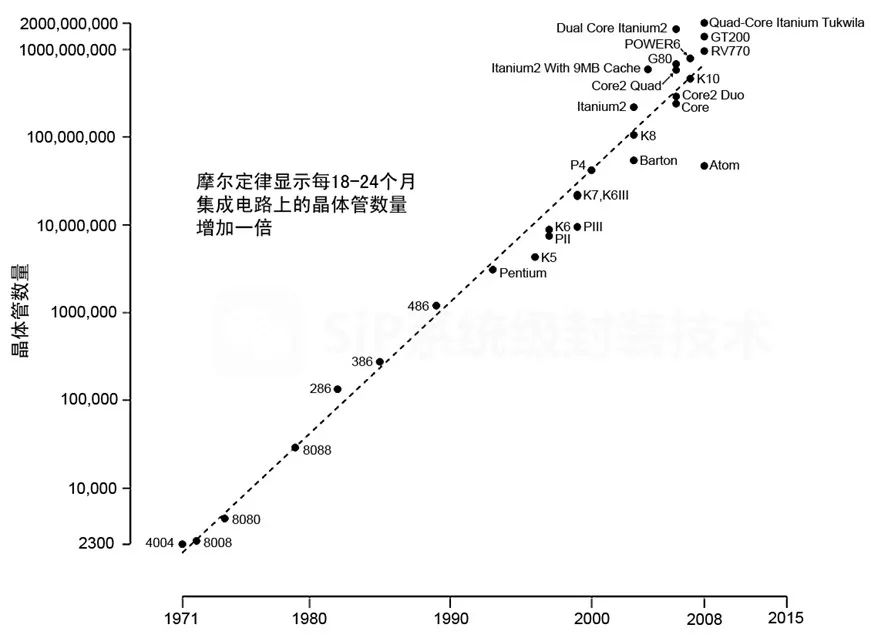
在 1990 年代,正當(dāng)摩爾定律鼎盛之時(shí),通過將許多現(xiàn)成的 CPU 排列在網(wǎng)格或某種類似的拓?fù)浣Y(jié)構(gòu)中來構(gòu)建超級(jí)計(jì)算機(jī)變得可行。這種趨勢導(dǎo)致了分布式超算的出現(xiàn)。尚未接受分布式超算的HPC 社區(qū)抗拒地將其稱為 The Attack of the Killer Micros,其中“Micro”意味著微處理器。這種觀點(diǎn)源于一個(gè)芯片上的CPU在早期被稱之為微處理器,而“CPU”通常是一個(gè)由分立組件組成的系統(tǒng)。最終,分布式超算取代了矢量超算,成為今天超級(jí)計(jì)算機(jī)的代名詞。
矢量超算以GPGPU的身份王者再臨
在21世紀(jì)初,摩爾定律開始呈現(xiàn)老化,導(dǎo)致CPU時(shí)鐘速度競賽戛然而止。然而CPU時(shí)鐘速度曾是單晶片計(jì)算性能的主要來源。業(yè)界的回應(yīng)是在一個(gè)芯片上安裝多個(gè)CPU核,期望并行性成為新的主要性能來源。這一趨勢帶來雙核、四核以及最終的多核,有效地形成了分布式超算集于一芯,將多個(gè)CPU核心排列在一個(gè)網(wǎng)格中。Many-Core的例子包括英特爾在市場上挑戰(zhàn)GPU的兩次挫敗,Larrabee在3D市場,以及Larrabee的后代Xeon Phi系列在HPC。
GPU傳統(tǒng)上對(duì)頂點(diǎn)、三角形和像素等圖形單元上展開“回圈”。GPU架構(gòu)師將這種能力擴(kuò)展到HPC應(yīng)用中的回圈,使GPU有效地成為矢量超算集于“一芯”。然后他們將GPU在HPC中的使用命名為通用GPU (即GPGPU)。當(dāng)矢量超算在HPC市場讓位給分布式超算時(shí),它就化身為GPU來報(bào)復(fù)它的競爭對(duì)手。我們可以看到GPU在頂級(jí)超算機(jī)上的商業(yè)成功,比如橡樹嶺國家實(shí)驗(yàn)室的Titan超算機(jī)和瑞士國家超算中心的Piz Daint。
簡而言之
——分布式超算機(jī)將矢量超算機(jī)從HPC市場踢出局
——Many-Core是分布式超算“集于一芯”
GPU是將高性能計(jì)算的矢量超算“集于一芯”
矩陣乘法(MM)和AI
網(wǎng)格,計(jì)算機(jī)架構(gòu)中的“舊錘子”,如何自我升級(jí)改造視人工智能為“新釘子”?
MM和HPC
計(jì)算機(jī)體系結(jié)構(gòu)中的一條永恒規(guī)則是,搬動(dòng)數(shù)據(jù)比計(jì)算數(shù)據(jù)更昂貴,這就要求計(jì)算機(jī)架構(gòu)在較少的數(shù)據(jù)上進(jìn)行更多的計(jì)算。幸運(yùn)的是, HPC社區(qū)從幾十年的實(shí)戰(zhàn)經(jīng)驗(yàn)中學(xué)到,他們可以用MM來表達(dá)大多數(shù) HPC問題,大致說來,MM在數(shù)據(jù)上的操作具有很高的計(jì)算-通信比。如果運(yùn)用得當(dāng),使用MM解決問題可以通過隱藏?cái)?shù)據(jù)傳輸來實(shí)現(xiàn)高性能。因此,HPC程序員只需要超算機(jī)供應(yīng)商提供的一個(gè)健全的MM程序庫。當(dāng)計(jì)算MM時(shí),今天的分布式超級(jí)計(jì)算可以充分利用分布在數(shù)十萬平方英尺上的數(shù)十萬節(jié)點(diǎn),有效地令每個(gè)單個(gè)節(jié)點(diǎn)都忙于計(jì)算。
矩陣乘法(MM)在AI中的崛起
運(yùn)用基于神經(jīng)網(wǎng)絡(luò)(NN)的機(jī)器學(xué)習(xí)(ML)是現(xiàn)代人工智能的特征。神經(jīng)網(wǎng)絡(luò)模型由多層ML核心程序組成。在卷積神經(jīng)網(wǎng)絡(luò)(CNN)之前,最流行的神經(jīng)網(wǎng)絡(luò)(NN)是多層感知器(MLP)。MLP的基本ML核心程序是矩陣矢量乘法(MVM),它對(duì)數(shù)據(jù)進(jìn)行粗略的MAC操作,幾乎沒有數(shù)據(jù)重用。另一方面,CNN目前主要的運(yùn)作元是張量卷積(Tensor Convolution, TC)。正如我在我的文章“All Tensors Secretly Wish to Be Themselves”中解釋的那樣,在數(shù)據(jù)搬動(dòng)和共享方面,MM和TC在結(jié)構(gòu)上是等價(jià)的,所以我們經(jīng)常可以互換使用張量和矩陣。
將MM作為運(yùn)作元給HPC和人工智能帶來了突破。CNN主要使用了MM,引發(fā)了計(jì)算機(jī)視覺領(lǐng)域人工智能的突破。Transformer也廣泛使用了MM,點(diǎn)燃了人工智能在自然語言理解(NLP)方面的突破。
多虧了人工智能及其對(duì)MM的大量使用,計(jì)算機(jī)體系結(jié)構(gòu)社區(qū)才有了一個(gè)世紀(jì)一遇的機(jī)會(huì),能夠聚焦在優(yōu)化MM這單純的目標(biāo),而又能同時(shí)對(duì)計(jì)算產(chǎn)生廣泛的影響——等于是事半功倍。
Many-Core 可以運(yùn)行與分布式超算相同的MM算法。從某種意義上說,從事人工智能的Many-Core 可以說是歸宗到HPC。
Many-MAC的浪潮
1982年,脈動(dòng)陣列被引入加速M(fèi)M和其他應(yīng)用。如果當(dāng)年在人工智能的背景下加速M(fèi)M像今天一樣酷,那么脈動(dòng)陣列的研究人員就不會(huì)為MM之外應(yīng)用而費(fèi)心了。脈動(dòng)陣列是一種比CPU內(nèi)核更密集地封裝MAC單元的機(jī)制。缺點(diǎn)是,我們不能在其他地方使用MM MAC單元。由于缺乏通用性,直到因?yàn)锳I成為MM的殺手級(jí)應(yīng)用,谷歌在TPU上采用脈動(dòng)陣列作為MM加速器,脈動(dòng)陣列才被市場接受。從那時(shí)起,市場上就出現(xiàn)了許多改進(jìn)原作的版本。在這里,我將原始的脈動(dòng)陣列及其變體稱為Many-MAC。為了處理非MM操作,Many-MAC增加了配套處理器。
另一方面,Many-Core 中的 CPU 核心,例如 D1 芯片或GPU 的著色器核心,可以使用更小的 Many-MAC,從而有效地成為 Many-MAC 容器。
簡而言之
—— AI和HPC因?yàn)槭褂么罅縈M而命運(yùn)交匯。
—— Many-Core 和 Many-MAC基本上不比GPU更適配AI。
領(lǐng)域轉(zhuǎn)移和領(lǐng)域特定的并行性
暗硅和功耗墻
在2010年之后,業(yè)界意識(shí)雖然理論上來說,并行度加倍是計(jì)算性能的主要來源,然而擁有兩倍的CPU核心,不可能保持這種良性循環(huán)。這是因?yàn)槊總€(gè) CPU 核無法將其功耗降低一半,或每瓦并行度翻倍。在幾次迭代的核加倍后,我們會(huì)看到大多數(shù)核在相同的功率預(yù)算下無法被供電,從而產(chǎn)生了暗硅,或者更準(zhǔn)確地說,是暗核。如下圖的概念圖所示,當(dāng)我們從 2 核變?yōu)?4 核時(shí),4 個(gè)核中只有 3 個(gè)可以供電,而當(dāng)我們從 4 核變?yōu)?8 核時(shí),只能為 4 個(gè)核供電。最后,16 個(gè)內(nèi)核中只有 4 個(gè)可以供電,因此從 8 核變?yōu)?16 核沒有任何好處。我們將這種現(xiàn)象稱為“功耗撞墻(hitting the Power Wall)”。
由于這個(gè)原因,相當(dāng)一部分計(jì)算機(jī)架構(gòu)社區(qū)成員疏遠(yuǎn)并行化。此外,悲觀主義者傾向于將并行度低、指針豐富的計(jì)算作為主流,并將具有并行性的HPC視為一個(gè)小眾市場。他們認(rèn)為,良性循環(huán)將過早止于阿姆達(dá)爾上限,也就是并行運(yùn)算的極致。
人工智能的及時(shí)救援
巧合的是,在這種悲觀情緒中出現(xiàn)了人工智能。根據(jù)斯坦福 AI 指數(shù)報(bào)告,人工智能一直不斷進(jìn)步,就好像功耗墻不存在一樣!
關(guān)鍵在于主流軟件可能會(huì)發(fā)生領(lǐng)域轉(zhuǎn)移,導(dǎo)致不同并行模式。如下面的概念圖所示,當(dāng)主流軟件從多指針計(jì)算轉(zhuǎn)向數(shù)據(jù)并行計(jì)算時(shí),它將一個(gè)并行度重新定義為單指令多數(shù)據(jù)(Single-Instruction-Multiple-Data, SIMD)的一條通道而不是一個(gè)CPU核。我們看到一條比CPU核曲線更高的曲線(標(biāo)記為SIMD lanes for data-parallel)。接下來,當(dāng)主流軟件進(jìn)入著重于MM的AI領(lǐng)域時(shí),添加了更高的曲線(標(biāo)記為MM MACs for MM-heavy),一個(gè)MM MAC代表一個(gè)并行度。正如我們所看到的,通過探索更有效的領(lǐng)域特定并行模式和提高阿姆達(dá)爾定律的上限,計(jì)算性能在功耗墻之內(nèi)繼續(xù)增長。
順帶一句,著重于MM的AI 有自己的阿姆達(dá)爾上限。AI 應(yīng)用程序需要有回圈前端,將 MM 操作分配到并行計(jì)算資源,以及回圈后端收集計(jì)算結(jié)果進(jìn)行串行操作(如歸一化或 softmax)的結(jié)果。當(dāng)有足夠多的 MM MAC 來加速 MM 時(shí),阿姆達(dá)爾定律就會(huì)發(fā)揮作用,從而使回圈前端和后端成為瓶頸。
此外,隨著摩爾定律的衰落越來越嚴(yán)重,制造更寬的加速M(fèi)M的機(jī)器是否能維持AI的良性循環(huán)就成了問題。為了解決這個(gè)問題,進(jìn)一步提高阿姆達(dá)爾的上限,我們需要轉(zhuǎn)移到更新的領(lǐng)域并探索新的領(lǐng)域特定并行性。換句話說,我們要考慮是否需要在下面的概念圖中添加一條新的曲線。
簡而言之
——通過將指針豐富的領(lǐng)域轉(zhuǎn)移到數(shù)據(jù)并行,進(jìn)而到重于MM的計(jì)算,我們不斷在功耗墻內(nèi)提升性能。
下一個(gè)領(lǐng)域轉(zhuǎn)移
可微分編程
英特爾的 Raja Koduri 表示,“神經(jīng)網(wǎng)絡(luò)是新的應(yīng)用程序。我們看到的是,每個(gè)插槽,[無論是] CPU、GPU 還是 IPU,都將具有矩陣加速功能。”
特斯拉的Ganesh Venkataramanan將他們的D1芯片描述為“純正”ML機(jī)器,專門運(yùn)行“ML核心程序”,無需傳統(tǒng)硬件。或許,他在暗示GPU不像D1那樣血統(tǒng)純正,因?yàn)樗膱D形專用硬件在AI處理過程中處于閑置狀態(tài)。
以上兩種觀點(diǎn)引出了兩個(gè)問題——人工智能的領(lǐng)域轉(zhuǎn)移應(yīng)該止于加速矩陣乘法嗎? 傳統(tǒng)領(lǐng)域特定的設(shè)計(jì)是否該被排除在人工智能硬件之外?
現(xiàn)在,我們從AI的核心是可微編程(DP)的角度來探索AI硬件的不同觀點(diǎn)。AI軟件程序是一個(gè)計(jì)算圖,如下圖所示,由參數(shù)化計(jì)算節(jié)點(diǎn)組成,每個(gè)節(jié)點(diǎn)將上游節(jié)點(diǎn)的輸出作為輸入,并將計(jì)算輸出提供給下游節(jié)點(diǎn)。我們通過“訓(xùn)練”決定所有計(jì)算節(jié)點(diǎn)的參數(shù),訓(xùn)練程序首先計(jì)算用到最終輸出的端到端損耗,然后計(jì)算該損耗的輸出梯度。沿著用于計(jì)算輸出的相反方向,它進(jìn)一步使用標(biāo)準(zhǔn)的微積分鏈規(guī)則重復(fù)計(jì)算中間梯度。
DP只要求任一個(gè)計(jì)算節(jié)點(diǎn)是可微的,使得它可以與所有其他節(jié)點(diǎn)共同優(yōu)化,通過梯度下降最小化端到端損失。計(jì)算節(jié)點(diǎn)的可微性使其能夠維持一條從下游到上游的反饋路徑,最終完成一個(gè)端到端的反饋回圈。在DP下,計(jì)算節(jié)點(diǎn)不一定是傳統(tǒng)的“ML核心程序”。計(jì)算圖可以是異構(gòu)的,包括非ML軟件和硬件節(jié)點(diǎn),只要它們滿足可微性要求。
一個(gè)計(jì)算節(jié)點(diǎn),使用參數(shù)w 及輸入x計(jì)算輸出y, 同時(shí)計(jì)算并記住用于計(jì)算輸入梯度的輸出/輸入微分。反饋路徑將輸入梯度傳播到上游節(jié)點(diǎn),如藍(lán)色虛線所示。如果有必要,它計(jì)算并記住輸出/參數(shù)微分,以計(jì)算參數(shù)梯度來調(diào)整參數(shù)。讓我們來看一些例子。
回圈中的可微分圖形硬件
越來越多的神經(jīng)網(wǎng)絡(luò)模型具有異構(gòu)計(jì)算節(jié)點(diǎn),符合可微分編程的定義。很好的例子是那些解決逆向圖形問題的例子。與正向圖形(從三維場景參數(shù)生成二維圖像)不同,逆向圖形從二維圖像恢復(fù)場景參數(shù)。新興的基于人工智能的逆向圖形解決方案通常包括一個(gè)不同于傳統(tǒng)的可微分圖形渲染器。它將梯度逆向傳播到上游節(jié)點(diǎn),參與梯度下降以最小化端到端損失。具有可微身處回圈圖形的逆圖形線程的強(qiáng)大功能在于使逆圖形“自我監(jiān)督”化,如下圖所示。
重建神經(jīng)網(wǎng)絡(luò)從真實(shí)圖像中獲取場景參數(shù),可微圖形根據(jù)場景參數(shù)繪制虛擬圖像。兩個(gè)共享下游NN處理好真實(shí)世界和虛擬世界的圖像來計(jì)算它們之間的端到端損失。假設(shè)回圈中沒有可微圖形,我們必須為場景參數(shù)準(zhǔn)備3D的基本事實(shí)。相反,真實(shí)世界的圖像有效地充當(dāng)虛擬世界圖像的基本事實(shí),使過程自我監(jiān)督化。
目前的可微分渲染器,如Soft Rasterizer, DIB-R,以及那些在AI框架中使用的渲染器,如PyTorch3D, TensorFlow Graphics,都是不使用特定于圖形硬件的軟件渲染器。這種軟件實(shí)現(xiàn)不像典型的ML核那樣著重MM,因此不能利用MM加速。
另一方面,GPU架構(gòu)師用足夠深的線程設(shè)計(jì)和提供特定于圖形的硬件,以便它們速度快,很少成為瓶頸。現(xiàn)在,假設(shè)我們制作了這樣一個(gè)線程“可微硬件”。軟件程序員可以在計(jì)算圖中有效地使用可微硬件,類似于使用預(yù)構(gòu)建的軟件組件。由于圖形專用硬件的深層線程并行性,這種循環(huán)中的硬件圖形應(yīng)該比其軟件對(duì)應(yīng)物快得多。
回圈中的可微分ISP
除了使用微分硬件作為預(yù)構(gòu)建的軟件組件外,我們還可以通過梯度下降調(diào)整其參數(shù)來“編程”,就像我們“訓(xùn)練”ML核心程序一樣。例如,圖像信號(hào)處理器(ISP)通過鏡頭捕獲圖像,并線上對(duì)其進(jìn)行處理,以生成供人類觀賞或下游圖像理解(IU)任務(wù)(如物件偵測或語義分割)使用的圖像。傳統(tǒng)的ISP有充足的參數(shù)空間,但需要專家對(duì)其進(jìn)行調(diào)整,以滿足人類的需求。目前為止,人類專家沒有能力針對(duì)下游IU神經(jīng)網(wǎng)絡(luò)模型,調(diào)整該參數(shù)空間。相反,ISP在特定參數(shù)設(shè)置下預(yù)捕獲和預(yù)處理的圖像被用來訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型。此外,捕獲圖像的透鏡系統(tǒng)在制造和操作期間可能存在缺陷。如果沒有與ISP的聯(lián)合優(yōu)化和設(shè)備調(diào)整,IU NN模型將無法令人滿意地執(zhí)行任務(wù)。
目前已經(jīng)有很多提議用 NN 模型替換某些 ISP 處理階段,這在具有特定功率和實(shí)時(shí)要求的場景中不一定實(shí)用或更好。另一方面,已經(jīng)有新興研究試圖利用 ISP 的未開發(fā)的參數(shù)空間。這里有些例子:
回圈中的不可微ISP硬件,用于非ML優(yōu)化的參數(shù)自動(dòng)調(diào)整。
經(jīng)過訓(xùn)練的 NN 模型模仿 ISP的可微代理, 用 于基于ML 的參數(shù)自動(dòng)調(diào)整。
上述研究表明,通過為特定 IU 任務(wù)設(shè)置端到端目標(biāo),自動(dòng)調(diào)整的 ISP 優(yōu)于沒有自動(dòng)調(diào)整的 ISP。
第一種方法,不可微ISP不能與其他神經(jīng)網(wǎng)絡(luò)模型聯(lián)合優(yōu)化。另一方面,雖然使用可微代理的第二種方法有助于訓(xùn)練,但其缺點(diǎn)是我們需要在仔細(xì)控制的環(huán)境中單獨(dú)訓(xùn)練此代理。
現(xiàn)在,想象一下使ISP可微。我們可以在回圈中使用ISP組成一個(gè)自適應(yīng)傳感線程,如下圖所示。它可以在具有ISP前和ISP后NN模型的設(shè)備上聯(lián)合調(diào)整自身,以適應(yīng)操作環(huán)境和特定UI任務(wù)。請(qǐng)注意,我們不固定ISP前和ISP后NN模型,就像GPU架構(gòu)師不指定圖形著色器一樣(請(qǐng)參閱我的文章《GPU將成為計(jì)算機(jī)體系結(jié)構(gòu)黃金時(shí)代的明星》)。
結(jié)論
我們使用回圈中的圖形硬件和回圈中的ISP 的例子介紹了可微分硬件的概念。更進(jìn)一步,假設(shè)我們已經(jīng)在芯片上同時(shí)擁有可微分 ISP 和可微分 GPU,并且我們還需要自監(jiān)督逆向圖形和自適應(yīng)傳感。如下所示,我們可以通過連接回圈中的圖形硬件和回圈線程中的ISP組成一個(gè)新線程。
我們可以看到,一個(gè)可微分硬件單元在以下三個(gè)方面看,是可編程的:
1.AI程序員可以在計(jì)算圖中使用它,因相當(dāng)于他們在軟件開發(fā)中使用預(yù)構(gòu)建和可定制的軟件組件。
2.AI程序員可以使用用于訓(xùn)練NN模型的相同ML框架自動(dòng)調(diào)整此可微硬件單元的參數(shù)。
3.AI程序員可以自由選擇各種NN模型來搭配這種可微硬件單元,就像圖形編程人員可以自由編程不同類型的著色器一樣。
AI 已將主流軟件的領(lǐng)域轉(zhuǎn)移到著重MM的計(jì)算。軟件程序員可以將廣泛的應(yīng)用程序簡化為 ML 核心程序。為了重振摩爾定律的良性循環(huán),我們需要另一個(gè)領(lǐng)域轉(zhuǎn)移。與其搞清楚哪些硬件是用于 AI 這個(gè)不斷發(fā)展的移動(dòng)目標(biāo),我們應(yīng)該遵循 AI 的精神——可微分編程,改變我們設(shè)計(jì)和使用計(jì)算硬件的方式。不再對(duì) AI 硬件進(jìn)行“血統(tǒng)純度”審查,因?yàn)樗梢园晌⒎钟布?/p>
如此一來,硬件有望在創(chuàng)新軟件中延長其生命周期,軟件可以利用硬件作為預(yù)構(gòu)建和可定制的組件。希望雙方都能加持彼此進(jìn)入一個(gè)新的良性循環(huán),就像摩爾定律鼎盛時(shí)那樣。
責(zé)任編輯:haq
-
芯片
+關(guān)注
關(guān)注
456文章
51192瀏覽量
427295 -
AI
+關(guān)注
關(guān)注
87文章
31536瀏覽量
270343 -
人工智能
+關(guān)注
關(guān)注
1796文章
47683瀏覽量
240302
原文標(biāo)題:人工智能將如何重振摩爾定律的良性循環(huán)
文章出處:【微信號(hào):IluvatarCoreX,微信公眾號(hào):天數(shù)智芯】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
擊碎摩爾定律!英偉達(dá)和AMD將一年一款新品,均提及HBM和先進(jìn)封裝

AI時(shí)代的存儲(chǔ)墻,哪種存算方案才能打破?
石墨烯互連技術(shù):延續(xù)摩爾定律的新希望
摩爾定律是什么 影響了我們哪些方面

Cadence如何應(yīng)對(duì)AI芯片設(shè)計(jì)挑戰(zhàn)
后摩爾定律時(shí)代,提升集成芯片系統(tǒng)化能力的有效途徑有哪些?
奇異摩爾專用DSA加速解決方案重塑人工智能與高性能計(jì)算
高算力AI芯片主張“超越摩爾”,Chiplet與先進(jìn)封裝技術(shù)迎百家爭鳴時(shí)代

“自我實(shí)現(xiàn)的預(yù)言”摩爾定律,如何繼續(xù)引領(lǐng)創(chuàng)新
英特爾CEO:AI時(shí)代英特爾動(dòng)力不減
封裝技術(shù)會(huì)成為摩爾定律的未來嗎?

電源解決方案跟摩爾定律有何關(guān)系?它如何跟上摩爾定律的步伐?

Chiplet封裝用有機(jī)基板的信號(hào)完整性設(shè)計(jì)

功能密度定律是否能替代摩爾定律?摩爾定律和功能密度定律比較





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論