 為什么我們需要分布式數據庫
為什么我們需要分布式數據庫
數據庫領域圖靈獎獲得者 Jim Gray 說過:“所有的存儲系統最終都會演變成數據庫系統。(All storage systems will eventually evolve to be database systems.)”
數據庫系統經過幾十年演進后,分布式數據庫在近幾年發展如火如荼,國內外出現了很多分布式數據庫創業公司,為什么分布式數據庫開始流行?在計算機歷史上出現過數百個數據庫系統,為什么我們需要分布式數據庫?
為何走向分布式數據庫
讓我們追溯數據庫發展歷史,看看分布式數據庫為何出現。
1960 年代:第一個數據庫
1961 年,Charles Bachman 等人設計了第一個計算機數據庫管理系統(DBMS),這個網狀模型(Network model)的數據庫被稱為 IDS(Integrated Data Store)。隨后不久,IBM 在 1968 年開發了層次模型(hierarchical model)的數據庫 IMS(Information Management System)。這兩個數據庫都是實驗性的先行者。
無論是網狀模型還是層次模型,最開始的數據庫都非常難用,沒有很多我們如今習慣的東西:
沒有表,更沒有 SQL;
數據粗暴存儲,不得不通過指針遍歷整個數據結構來進行查詢;
邏輯層和物理層并不分離,沒有獨立的模式(schema),要增加屬性,必須重新加載全部的數據然后轉存;
最初的數據庫沒有獨立存儲數據,沒有任何抽象,這導致開發者需要耗費大量精力來使用。
1970 年代:關系型數據庫
到了20世紀70年代,IBM 的研究員 Edgar Frank Codd 看到他周圍的程序員每天花費大量時間處理查詢、改變模式和思考如何存儲數據,于是他創造了今天眾所周知的關系模型。
關系模型建立之后,IBM 開啟了著名的 System R 進行專項研究,該項目是第一個實現 SQL 和事務的 DBMS。System R 的設計對后來各類數據庫產生了積極的影響。
關系模型擺脫了查詢和數據存儲之間的緊密耦合,查詢獨立于存儲,數據庫可以自由地在幕后進行優化,程序員無需知道背后的存儲方式,只需要通過 SQL 與數據庫進行交互,這對于開發者非常友好。
1978 年 Oracle 發布,點燃了商業數據庫的導火線。
20世紀末:走向成熟
接下來的幾十年里,數據庫進入成長期,一步步走向成熟。早期的層次模型和網狀模型消失了,關系型數據庫成為主流。SQL 成為數據庫標準查詢語言,直到今天我們仍然在使用。
數據庫商業化也越來越完善,同時開始出現如 PostgreSQL 和 MySQL 等開源數據庫。由于大型商業數據庫非常昂貴,一些互聯網企業開始使用 MySQL 等開源數據庫作為替代方案。
2000 年代:NoSQL
21 世紀伊始,互聯網走向繁榮,突然間許多公司需要支持越來越多的用戶,并且必須 24 * 7 不間斷運行服務,為此互聯網公司不得不在多臺計算機上復制(replication)和分片(shard)存儲他們的數據。
分片存儲即將表按照某個關鍵字拆分成多個分片,例如按照年進行拆分,2000 年的數據存儲在第一臺機器上,2001 年的數據存儲在第二臺機器上,以此類推。這通常由數據庫管理員來完成。同時為了讓應用程序不修改代碼、無感知地讀寫分片數據,必須要將一個中間件放到這些分片前面,將應用程序原本的 SQL 轉換為支持分片的 SQL。如下圖所示。
當然,這類方案也有一些缺點,例如:
不支持跨分片事務;
重新分片是困難的,會成為數據庫管理員的噩夢;
Google 等公司如此分片存儲數據庫,目的是不惜一切代價來獲得可擴展性,因為他們需要構建越來越大的應用,服務越來越多的用戶。這些事情都是為了追求可擴展性。
為此,這些公司還開發了 NoSQL,不惜放棄了關系模型,放棄了事務,放棄了數據一致性保證(有的 NoSQL 只保證最終一致性)。
前文提到,20世紀70年代 Edgar Frank Codd 為了減輕開發人員心智負擔而設計了關系型數據庫,而 NoSQL 解決了應用程序所需的可擴展性,但又好似退回到了以前,程序員又要面臨 NoSQL 功能不足的問題——也就是 Jim Gray 所說的:“所有的存儲系統最終都會演變成數據庫系統。”
2010 年代:分布式數據庫
為什么要構建分布式數據庫呢?通過歷史發展分析應該相當清楚了,現有的數據庫解決方案給開發者和管理員帶來了過重的負擔。當你開始一個新的大項目,選擇一個單點數據庫會犧牲掉未來的可擴展性,選擇一個 NoSQL 又會讓開發者承受額外的負擔來解決問題,并且可能不支持事務等優秀的功能。
分布式數據庫試圖結合兩者優點,構建成為兩全其美的系統:既能支持完整的關系模型,又能提供高可擴展性和可用性。分布式數據庫常被稱為 NewSQL 或 Distributed SQL——無論怎么稱呼,都指那些在多臺機器運行的數據庫。
這不是說 NoSQL 是完全沒用的,事實上人們在 NoSQL 上構建了許多成功的系統,但這要困難得多。Google 的分布式數據庫 Spanner 論文中有一句話:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
翻譯過來就是:“我們認為最好讓應用程序開發者來解決因過度使用事務而導致的性能問題,而不是讓開發者總是圍繞著缺少事務編寫代碼。”
也就是說,事務是否會造成性能影響的應該由業務開發者來考慮,而作為一個數據庫必須提供事務機制,來滿足各種應用常見的需求。
Spanner 論文發表后,開始涌現出許多優秀的開源分布式數據庫,其中具有代表性的有:CockroachDB、TiDB、YugabyteDB 和最近開源的 OceanBase 等等。
通過回顧數據庫歷史進程,我們知道了為什么出現分布式數據庫,現在我們要關注如何實現分布式數據庫。
如何實現分布式數據庫
分布式數據庫我們關注:
數據如何在機器上分布;
數據副本如何保持一致性;
如何支持 SQL;
分布式事務如何實現;
當然,本文只會簡述分布式數據庫的簡單原理,許多細節不會涉及,如果你想要深入學習,除了學習源代碼外,可以關注筆者的公眾號和筆者下半年將要出版的書籍。
數據分布
NewSQL 和 NoSQL 的數據分布是類似的,他們都認為所有數據不適合存放在一臺機器上,必須分片存儲。因此需要考慮:
如何劃分分片?
如何定位特定的數據?
分片主要有兩種方法:哈希或范圍。
哈希分片將某個關鍵字通過哈希函數計算得到一個哈希值,根據哈希值來判斷數據應該存儲的位置。這樣做的優點是易于定位數據,只需要運行一下哈希函數就能夠知道數據存儲在哪臺機器;但缺點也十分明顯,由于哈希函數是隨機的,數據將無法支持范圍查詢。
范圍分片指按照某個范圍劃分數據存儲的位置,舉個最簡單的例子,按照首字母從 A-Z 分為 26 個分區,這樣的分片方式對于范圍查詢非常有用;缺點是通常需要對關鍵字進行查詢才知道數據處于哪個節點,這看起來會造成一些性能損耗,但由于范圍很少會改變,很容易將范圍信息緩存起來。
例如下圖所示,我們按照關鍵字劃分為三個范圍:[a 開頭,h 開頭)、[h 開頭,p 開頭)、[p 開頭,無窮)。
如下圖所示,這樣進行范圍查詢效率會更高。
我們關心的最后一個問題是,當某個分片的數據過大,超過我們所設的閾值時,如何擴展分片?由于有一個中間層進行轉換,這也很容易進行,只需要在現有的范圍中選取某個點,然后將該范圍一分為二,便得到兩個分區。
如下圖所示,當 p-z 的數據量超過閾值,為了避免負載壓力,我們拆分該范圍。
顯然,這里有一個取舍(trade-off),如果范圍閾值設置得很大,那么在機器之間移動數據會很慢,也很難快速恢復某個故障機器的數據;但如果范圍閾值設置得很小,中間轉換層可能會增長得非常快,增加查詢的開銷,同時數據也會頻繁拆分。一般范圍閾值選擇 64 MB 到 128 MB,Cockroachdb 使用 64MB 大小,TiDB 默認閾值為 96 MB 大小。
數據一致性
一個帶有“分布式”三個字的系統當然需要容忍錯誤,為了避免一臺機器掛掉后數據徹底丟失,通常會將數據復制到多臺機器上冗余存儲。但分布式系統中請求會丟失、機器會宕機、網絡會延遲,因此我們需要某種方式知道冗余的副本中哪些數據是最新的,
最常見的復制數據方式是主從同步(或者直接復制冷備數據),主節點將更新操作同步到從節點。但這樣存在潛在的數據不一致問題,同步更新操作丟失了怎么辦?從節點恰好寫入失敗了怎么辦?有時這些錯誤甚至會永久損壞數據,需要數據庫管理員介入。
保持一致性常常會以性能為代價(以后我們會討論),因此,大部分 NoSQL 只保證最終一致性,并通過一些沖突處理方案來解決數據不一致。
很多名詞沒有加以解釋,如果你覺得很多名詞你不了解,想要了解更多內容,請關注我的公眾號,或是期待我下半年將出版的新書。
現有著名的復制數據的算法是我們經常聽到的 Paxos、Raft、Zab 或 Viewstamped Replication 等算法。其中,Google 花了數年時間才實現了一個滿足生產需要的 Paxos 算法。而 Raft 是一個后起新秀,是斯坦福大學的博士生 Ongaro Diego 基于 Paxos 設計的一個更具理解性的共識算法。Raft 誕生后便席卷了分布式共識算法領域,如今你可以在 Github 搜到許許多多的 Raft 開源實現,把他們 clone 到你的應用中來實現可靠的數據復制吧(千萬別真的這么干!)。
Raft 未必真的易于使用,但它已經使得編寫具有一致性的系統比以往更容易,具體算法細節不再展開,感興趣的同學請閱讀前文《條分縷析 Raft 共識算法》。
簡而言之,Raft 算法只需要超過半數的節點寫入成功,即認為本次寫操作成功,并返回結果給客戶端。發生故障時,Raft 算法可以重新選舉領導者,只要少于半數的節點發生故障,Raft 就能正常工作。
Raft 算法可以滿足可靠復制數據,同時系統能夠容忍不超過半數的節點故障。
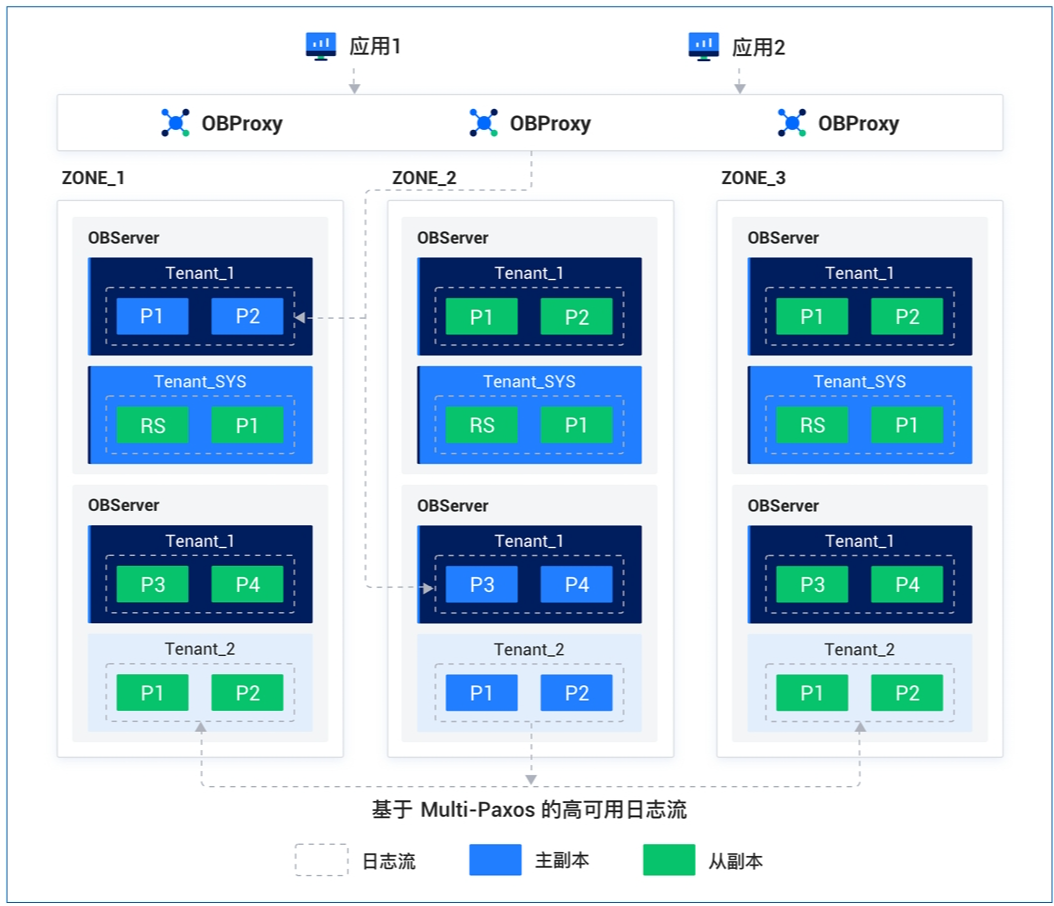
在分布式數據庫中,一個分片使用一個共識組(consensus group)復制數據,具體的 Raft 共識組稱為 Raft 組(Raft group),Paxos 共識組稱為 Paxos 組(Paxos group)。
我從 TiDB 官網中找來一張圖,TiDB 將一個分片稱為一個 Region,如圖中有三個 Raft 組,用來復制三個 Region 的數據。
軟件工程沒有銀彈,使用共識算法仍然需要面臨許多生產問題,例如成員變更、范圍分區變更、實現線性一致性等等問題都要去克服。只不過現在我們有了堅實的學術支撐,這樣進行復制是正確的。
SQL 表數據 KV 化存儲
解決了 KV 存儲以后,我們還要想辦法用 KV 結構來存儲表結構。通常,增刪查改可以抽象成如下 5 個 KV 操作(也許可以再多些,但基本就是這些)。
Get(key) Put(key, value) ConditionalPut(key, value, exp) Scan(startKey, endKey) Del(key)
我們討論的是 OLTP 類分布式數據庫都是行存。我們以 CockroachDB 舉例,一個表通常包含行和列,可以將一個表轉換成如下結構:
/







 工商網監
工商網監
評論