") 我們可以使用transformer來干什么?
我們可以使用transformer來干什么?
前言
2021年4月,距離論文“Attention is all you need”問市過去快4年了。這篇論文的引用量正在沖擊2萬大關(guān)。
筆者所在的多個學(xué)習(xí)交流群也經(jīng)常有不少同學(xué)在討論:transformer是什么?transformer能干啥?為什么要用transformer?transformer能替代cnn嗎?怎么讓transformer運(yùn)行快一點(diǎn)?以及各種個樣的transformer技術(shù)細(xì)節(jié)問題。
解讀以上所有問題不再本文范疇內(nèi),但筆者也將在后續(xù)文章中繼續(xù)探索以上問題。本文重點(diǎn)關(guān)注:我們用transformer干啥?
我們用transformer干啥?筆者突然發(fā)現(xiàn)這句話有兩種理解(orz中文博大精深),希望我的語文不是體育老師教的。
疑問句:
我們使用transformer在做什么?
解決什么深度學(xué)習(xí)任務(wù)?
反問句:
我們用用transformer干啥?
為啥不用LSTM和CNN或者其他神經(jīng)網(wǎng)絡(luò)呢?
疑問句:用transformer干啥?
谷歌學(xué)術(shù)看一眼。
為了簡潔+有理有據(jù)回答這個問題(有缺失之處忘大家指出),筆者首先在谷歌學(xué)術(shù)上搜尋了一下“Attention is all you need”看了一下被引,到底是哪些文章在引用transformer呢?
“Attention is all you need”被引:19616次。
先看一下前幾名引用的被引:
最高引用的“Bert:Pre-training of deep bidirectional transformers for language understanding“被引:17677次。BERT在做自然語言處理領(lǐng)域的語言模型。
第2和4名:“Squeeze and Excitaion Networks”被引用6436次,“Non-local neural networks”。計算機(jī)視覺領(lǐng)域,但還沒有直接用transformer。
第3名:“Graph attention networks”被引用3413,一種圖神經(jīng)網(wǎng)絡(luò),該文也不是直接使用transformer的,但使用了attention。
第5和6名:“Xlnet:Generalized autoregressive pretraining for language undersstanding“ 2318次和 ”Improving language understanding by generative pretraining“ 1876次。自然語言處理領(lǐng)域預(yù)訓(xùn)練/語言模型/生成模型。
第7名“self-attention generative adversarial networks” 1508次。基于self-attetnion的生成對抗網(wǎng)絡(luò)。
第8、9、10都屬于自然語言處理領(lǐng)域,一個是GLUE數(shù)據(jù)集,一個做multi-task learning。
從Top的引用已經(jīng)看出自然語言處理領(lǐng)域肯定是使用transformer的大頭了。隨后筆者對熟悉的深度學(xué)習(xí)任務(wù)關(guān)鍵詞搜了一下被引用:
計算機(jī)視覺領(lǐng)域vision前2的被引用:“Vibert”和“Stand-alone self-attetnion in vision model”分別為385和171次。
語音信號處理領(lǐng)域speech:“state-of-the-art speech recognition with sequence-to-sequence model” 被引710次。
多模態(tài)任務(wù)modal:“Unicoder-Vl:
A universal encoder for vision and language by cross-model pre-training。
檢索領(lǐng)域etrieval:“multilingual universal sentence encoder for semantic retrieval”被引73次
推薦領(lǐng)域recommendation:驚訝的我發(fā)現(xiàn)居然只有10篇文章orz。
初步結(jié)論:transformer在自然語言處理任務(wù)中大火,隨后是語音信號領(lǐng)域和計算機(jī)視覺領(lǐng)域,然后信息檢索領(lǐng)域也有所啟航,推薦領(lǐng)域文章不多似乎剛剛起步。
執(zhí)著的筆者擴(kuò)大搜索范圍直接谷歌搜索了一下,找到了這篇文章BERT4Rec(被引用128):”BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer“。
Github上搜一搜。
排名第1的是HuggingFace/transformers代碼庫。筆者對這個庫還算熟悉,但最近瘋狂新增的模型缺失還沒有完全跟進(jìn)過,于是也整理看了一下。
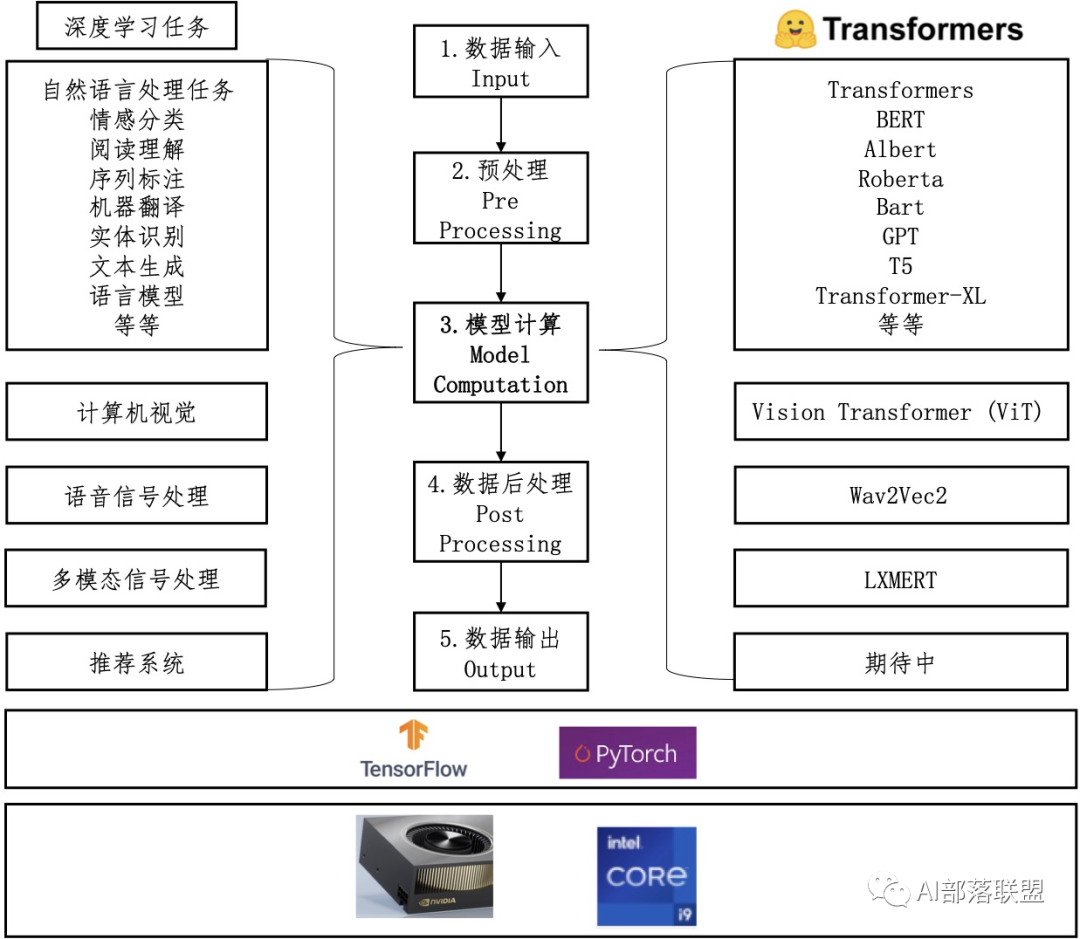
圖1 HuggingFace/transformers代碼庫關(guān)系圖
如圖1所示,左邊展示了Huggingface/transformers代碼庫能處理的各種深度學(xué)習(xí)任務(wù),中間展示的是處理這些任務(wù)的統(tǒng)一流水線(pipeline),右邊展示的是與任務(wù)對應(yīng)的transformers模型名稱,下方表示用transformers解決這些深度學(xué)習(xí)任務(wù)可以在cpu或者gpu上進(jìn)行,可以使用tensorflow也可以使用pytorch框架。
那么根據(jù)谷歌和github結(jié)果基本可以得到這個核心結(jié)論啦:transformer能干啥?目前已有的transformer開源代碼和模型里自然語言處理任務(wù)占大頭(幾乎覆蓋了所有自然語言處理任務(wù)),隨后是計算機(jī)視覺和語音信號處理,最后自然而然進(jìn)行多模態(tài)信號處理啦,推薦系統(tǒng)中的序列建模也逐步開始應(yīng)用transformer啦。
有一點(diǎn)值得注意:自然語言處理里,所有研究同學(xué)的詞表庫基本統(tǒng)一,所有谷歌/facebook在大規(guī)模語料上預(yù)訓(xùn)練的transformer模型大家都可以使用。推薦系統(tǒng)不像自然語言處理,各家對user ID,Item ID或者物品類別ID的定義是不一樣的,所以各家的pretrain的模型基本也沒法分享給其他家使用(哈哈哈商業(yè)估計也不讓分享),也或許也是為什么transformer的開源推薦系統(tǒng)較少的原因之一吧,但不代表各大廠/研究機(jī)構(gòu)用的少哦。
反問句:用transformer干啥?
為什么非要使用transformer呢?
筆者從一個散修(哈哈修仙界對修煉者的一種稱呼)的角度聊一聊自己的看法。
不得不用。
首先谷歌/Facebook一眾大廠做出來了基于transformer的BERT/roberta/T5等,刷新了各種任務(wù)的SOTA,還開源了模型和代碼。
注意各種任務(wù)啊,啊這,咱們做論文一般都得在幾個數(shù)據(jù)集上驗(yàn)證自己的方法是否有效,人家都SOTA了,咱得引,得復(fù)現(xiàn)呀,再說,站在巨人的肩上創(chuàng)下新SOTA也是香的。
的確好用。
Transformer是基于self-attetion的,self-attention的確有著cnn和lstm都沒有的優(yōu)勢:
比如比cnn看得更寬更遠(yuǎn),比lstm訓(xùn)練更快。
重復(fù)累加多層multi-head self-attetion還在被不短證明著其強(qiáng)大的表達(dá)能力!
改了繼續(xù)用。
如果不說transformer的各種優(yōu)點(diǎn),說一個大缺點(diǎn)自然就是:
參數(shù)量大、耗時耗機(jī)器。
但這些問題又被一眾efficient transformers再不斷被解決。
比如本來整型數(shù)運(yùn)算的硬件開發(fā)板無法使用transformers,隨后就有INT-BERT說我們不僅可以用,還能更快更好。
上手就用。
以Huggingface/Transformers為例子,一個代碼庫包含多種深度學(xué)習(xí)任務(wù),多個開源的transfromer模型,各種預(yù)訓(xùn)練transformer模型,以至于各種深度學(xué)習(xí)任務(wù)上手就來,十分方便。
筆者似乎并沒有看到其他模型結(jié)構(gòu)有如此大的應(yīng)用范圍和規(guī)模了。
未來還要用。
從上一章節(jié)可以看出,transformer這股風(fēng)已經(jīng)從自然語言處理領(lǐng)域吹出去了,其他領(lǐng)域的SOTA也在不斷被transformer打破,那么以為這,自然語言處理領(lǐng)域的歷史逐漸在其他領(lǐng)域復(fù)現(xiàn)(當(dāng)然只是筆者個人觀點(diǎn)哈)。
原文標(biāo)題:我們用transformer干啥?
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
Transforme
+關(guān)注
關(guān)注
0文章
12瀏覽量
8797 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5513瀏覽量
121544
原文標(biāo)題:我們用transformer干啥?
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
transformer專用ASIC芯片Sohu說明

PLM項(xiàng)目管理系統(tǒng)主要干什么?制造業(yè)企業(yè)的PLM應(yīng)用與效益

AI開發(fā)平臺可以干什么
如何限制容器可以使用的CPU資源






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論