 全面概述ARM Mali GPU架構演進!
全面概述ARM Mali GPU架構演進!
年初有機會調研了一下歷代ARM Mali GPU架構,目前一共四代【1】,分別是Utgard,Midgard,Bifrost和Valhall。有感于他的演進是大GPU架構發展的縮影,所以作文一篇記錄心得。我不打算逐一介紹各代架構的細節,而是針對Shader處理器聊一聊每代GPU的發展。對各代架構細節有興趣或者希望了解全貌的同學可以參考【2】【3】【4】【5】。
Shader處理器
圖形API發展到OpenGL 2.0之后,圖形處理管線擺脫了之前的固定模式,實現了高度的可定制化。出現了針對圖形管線各階段的Shader,比如Vertex Shader,Fragment Shader,再到后來的Geometry Shader,Tessellation Shader和Compute Shader。每個Shader都是一個用戶編寫的小程序,執行這些小程序就是GPU中Shader處理器的工作。
Shader處理器作為核心組件,它的架構關系到GPU的性能表現,也是演進最為激烈的部分。每代Mali GPU都會對Shader處理器做較大調整以適應圖形API和應用的發展。這里著重討論兩個主要變化——統一處理器架構和TLP驅動的架構設計。
從獨立到統一
初代的Utgard架構有兩種Shader處理器,GP——執行Vertex Shader,PP——執行Fragment Shader。兩者采用不同的硬件架構和指令集,所以編譯器會將不同的Shader編譯成各自Shader處理器的機器碼后交由它們分別執行。
Vertex Shader是對每一個頂點執行一次,而Fragment Shader是對每一個像素執行一次,一般情況下Fragment Shader的執行次數會多于Vertex Shader;而且很多圖形效果的實現,Fragment Shader都比Vertex Shader更加復雜。所以Utgard是一個GP配上多個PP,比如一個GP配四個PP就是MP4,最高能配到MP8。單個PP的硬件設計也相對GP更加復雜。
這種獨立Shader處理器的架構Shader處理器之間算力無法互通,當一種Shader算力需求遠大于另一種時,另一種Shader處理器只能干等著無法幫忙,造成利用率下降。而且隨著圖形API加入新的Shader種類,給每一種Shader設計一種處理器會不斷增加軟件和硬件的復雜度。但其實這些Shader在純計算部分幾乎是一樣的,可以復用大部分的設計,不必每一個Shader都搞一套。
所以從Midgard這一代開始,采用了統一Shader處理器架構。不同種類的Shader共享計算部分作為統一Shader處理器,頂點插值和光柵化這些固定功能操作獨立于外。這樣每種Shader都能跑滿所有的處理器,提高了硬件利用率。
從ILP到TLP
ILP(Instruction Level Parallelism)和TLP(Thread Level Parallelism)都或多或少同時存在于每代的Shader處理器架構中,但是趨勢是TLP的比重逐漸加大。
Utgard和Midgard架構下TLP僅限于處理器級別,Shader處理器就像CPU的一個核心,一次運行一個頂點或者像素的Shader,有幾個處理器就有幾個線程。比如Mali400MP4,有四個PP,可以并行處理四個像素的fragment shader。每個處理器完全采用了ILP的方式著重優化單線程的處理能力。
我們可以從兩種架構所使用的VLIW指令【6】一窺ILP的設計。Utgard PP的指令編碼可以參見【7】,包含兩個向量處理單元、兩個標量處理單元、一個函數處理單元,還有負責各類數據加載和執行控制的單元。這種VLIW指令和普通的CPU指令不同,一條指令可以完成多個操作。它對應了硬件上的管線(pipeline)結構,如圖一所示。管線是處理器執行指令的一條流水線,可以分成多個階段(stage)。VLIW指令里的各個操作由這條管線里的各個階段完成。
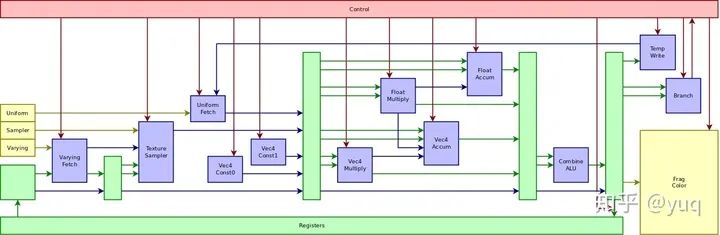
圖一:Utgard PP處理器管線【7】
比如這一系列操作:取貼圖數據,然后做加法,再做乘法,最后寫結果到內存。精簡指令集(RISC)一般需要四條指令,每條指令都有各自的取指令,執行,寫結果的步驟;但是VLIW可以在一條指令里將這些操作依序串起來,取出的貼圖數據不需要寫進寄存器文件,直接傳給加法單元處理,加法單元的結果也是這樣直接傳遞給乘法單元,最后輸出到內存。所以VLIW管線會更長,但是由于略去了操作的中間步驟,整合后更加高效。
普通CPU會通過復雜的硬件設計,動態調度要執行的指令來提高單線程性能,比如并行執行和亂序執行。VLIW卻是通過在編譯階段,依靠編譯器靜態調度各個操作填充到VLIW指令的單元中。所以很多早期的GPU包括桌面和移動的,為了簡化硬件降低功耗,都采用VLIW來加強ILP。但是這種設計對編譯器要求很高。如何調度Shader里的操作以充分利用一條指令里的所有操作單元決定了硬件的執行效率。當然Shader本身的邏輯也決定了有沒有足夠可以并行的操作。這些都是ILP發展方向的限制條件。
好在圖形計算是一個天生的數據并行良好的鄰域——有大量的圖元需要計算,而且每個圖元的計算可以獨立進行,不依賴其他圖元。所以每個圖元的計算都可以作為一個線程,繪制出一幀畫面就是跑完這成千上萬個線程的工作。利用大量的線程,獲得很多可以并行執行的操作,不用很復雜的調度就能達到很高的硬件利用率,這就是GPU里TLP設計的出發點。
從Bifrost架構開始,ARM在單處理器內部也引入了TLP。方法是將大量線程每4個一組(后來擴展為8、16個),然后一組一組在單個處理器中運行。同組的線程執行相同的指令,類似于SIMD。這樣就不需要為每個線程都準備一套完整的處理器設計,而是可以多個線程共享除了執行器和寄存器以外的部分。再乘上核心數,同時運行的線程數量大大增加。
而且為了隱藏一些操作比如內存訪問的延遲,還有一個線程組的池,里面可以準備執行到不同指令的幾十組線程,在一組線程因為數據訪問等依賴無法馬上執行時,硬件調度器可以掛起這組線程執行另一組的線程。也算是利用線程數量的例子。
不過Bifrost架構里依然有很多ILP的設計,比如句式(Clause)指令(圖二):將很多串行指令組成一個指令塊——句子,句子是硬件調度器調度的最小單位。句子內部可以有一些加速操作,比如當一個加法指令輸出是一個減法指令輸入的時候,可以不通過寄存器文件直接傳遞數據。而且單個指令雖然減少了單元數量,但還是有三個計算單元。所以編譯器還是需要考慮單指令單元填充以及多指令組成句子的問題。
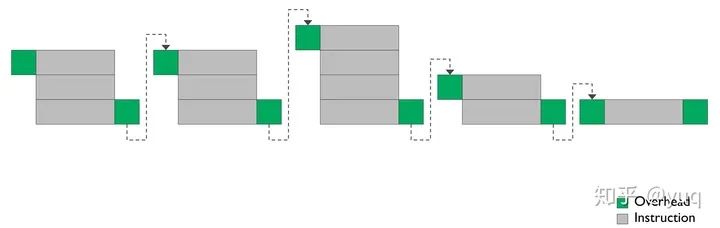
圖二:Bifrost句式指令【4】
Valhall架構就更加依賴TLP來提升性能了,為此放棄了句式指令和多單元指令這些依賴軟件的ILP特性,減小了調度粒度的同時也縮短了處理器管線。如圖三所示,Valhall的處理器有三個計算單元,包括一個FMA(Fused-Multiply-Add),一個CVT(Convert)和一個SFU(Special Function Unit),線程組調度器可以在線程組池里找出三個當前指令使用不同計算單元的線程組,讓他們在四個時鐘周期內同時在三個計算單元內執行。而Bifrost雖然也有三個計算單元,但是他們屬于一條長指令,而且ADD和Table排在FMA下游,是一個串行結構,這一條管線需要八個時鐘周期。
對比來看Valhall再次加強了TLP,一個處理器最多可以同時運行三個線程組,而Bifrost最多只有一個。反過來看Valhall將三個Bifrost處理器壓縮為一個,減少了控制邏輯,就可以有更多的空間增加處理器的數量,也是增加了TLP。

圖三:Valhall和Bifrost處理器對比【5】
結語
在GPU架構歷史上,統一Shader處理器和TLP驅動架構設計都是趨勢。各家各代的GPU都或多或少經歷了這個過程。我們純從架構上看后期的GPU都比前期來的先進,但是放在當時的環境下,早期的圖形應用Shader負載不是很復雜,而且移動鄰域處理器對于面積和功耗方面的嚴格控制,都是他合理性的來源。
引用
Mali (GPU):https://zh.wikipedia.org/wiki/Mali_(GPU)
Lima driver status update:https://xdc2019.x.org/event/5/contributions/328/attachments/420/670/lima.pdf
ARM‘s Mali Midgard Architecture Explored:https://www.anandtech.com/show/8234/arms-mali-midgard-architecture-explored
ARM Unveils Next Generation Bifrost GPU Architecture & Mali-G71: The New High-End Mali:https://www.anandtech.com/show/10375/arm-unveils-bifrost-and-mali-g71
Arm’s New Mali-G77 & Valhall GPU Architecture: A Major Leap:https://www.anandtech.com/show/14385/arm-announces-malig77-gpu
Very long instruction word:https://en.wikipedia.org/wiki/Very_long_instruction_wordA4%E5%AD%97
Mali ISA:https://gitlab.freedesktop.org/panfrost/mali-isa-docs/-/tree/master
編輯:jq
-
GP
+關注
關注
0文章
30瀏覽量
23527 -
編譯器
+關注
關注
1文章
1642瀏覽量
49286 -
TLP
+關注
關注
0文章
32瀏覽量
15671 -
GPU架構
+關注
關注
0文章
15瀏覽量
8491
原文標題:ARM Mali GPU架構演進
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機網絡架構的演進
芯原發布新一代Vitality架構GPU IP系列
一文詳解Arm架構Armv9.6-A中的最新功能
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
GPU服務器AI網絡架構設計

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
京東廣告投放平臺整潔架構演進之路

ARM進軍GPU領域,挑戰英偉達與英特爾
Arm發布針對旗艦智能手機的新一代CPU和GPU IP
Arm發布Arm v9架構CPU、GPU IP及設計軟件,助力AI計算
X-Silicon發布RISC-V新架構 實現CPU/GPU一體化
Arm v9芯片新架構揭秘






 工商網監
工商網監
評論