 深度學習:基于語境的文本分類弱監督學習
深度學習:基于語境的文本分類弱監督學習
高成本的人工標簽使得弱監督學習備受關注。seed-driven 是弱監督學習中的一種常見模型。該模型要求用戶提供少量的seed words,根據seed words對未標記的訓練數據生成偽標簽,增加訓練樣本。
但是由于一詞多義現象的存在,同一個seed word會出現在不同的類別中,從而增加生成正確偽標簽的難度;同時,單詞w在語料庫中的所有位置都使用一個的詞向量,也會降低分類模型的準確性。
而本篇論文主要貢獻有:
開發一種無監督的方法,可以根據詞向量和seed words,解決語料庫中單詞的一詞多義問題。
設計一種排序機制,消除seed words中一些無效的單詞;并將有效的單詞擴充進seed words中。
模型整體結構為:
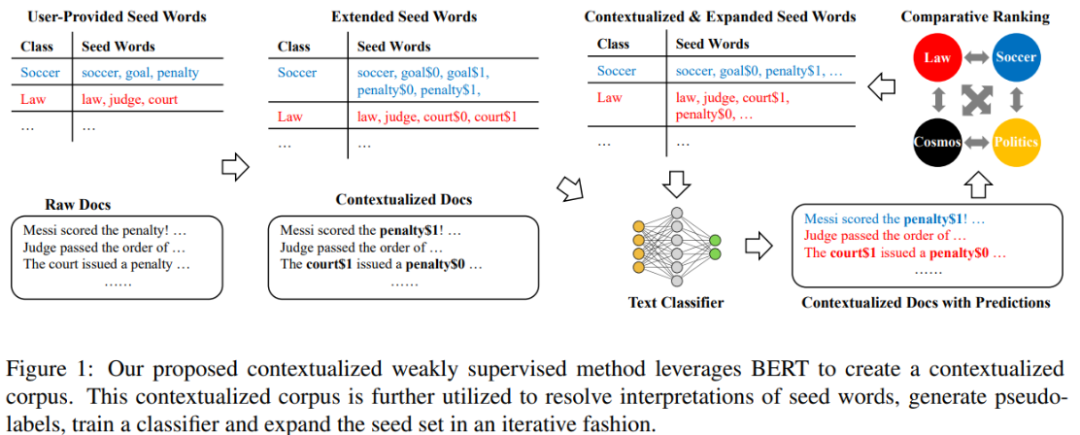
第一步:使用聚類算法解決語料庫中單詞的一詞多義問題
對于每一個單詞 w, 假設w出現在語料庫的n個不同位置, 分別為 ,使用K-Means算法將分成K類,這里K可理解為單詞w的K個不同解釋。
用下列公式計算K的值:
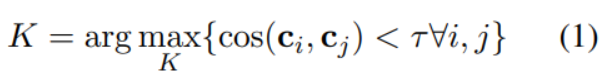
其中代表第i個聚類中心的向量。的計算方法如下:
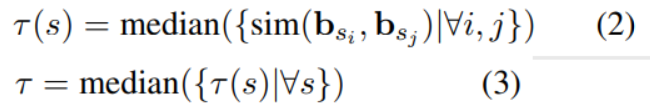
這里s表示一個seed word,且表示s在語料庫第i次出現,對應的詞向量為。
sim() 表示余弦函數,median( )表示取中位數。
則對于任意,有
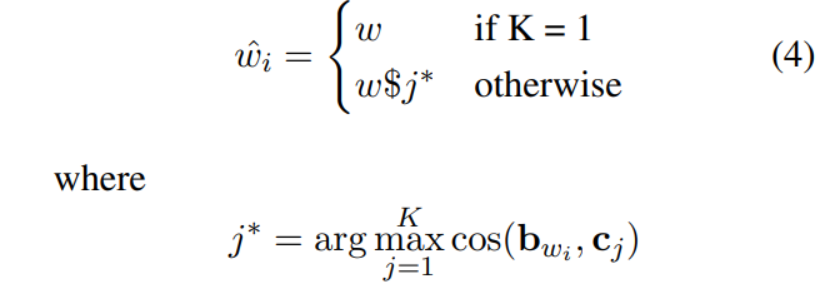
綜上,一詞多義問題解決算法如下:

使用上面算法,我們就可以將原始語料庫轉變為基于語境下的語料庫:

第二步:對未標記的訓練數據生成偽標簽令表示文檔d的偽標簽;表示類別為的seed word 集合;表示單詞w出現在文檔d的詞頻
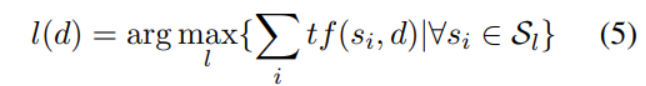
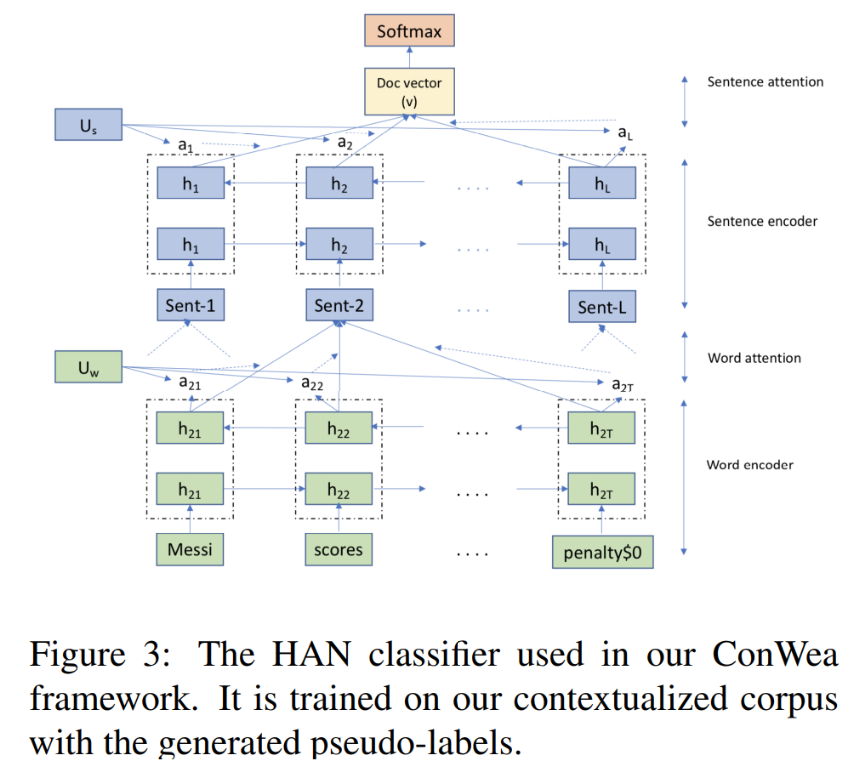
第三步:使用基于語境下的語料庫進行文檔分類
本篇論文使用Hierarchical Attention Networks (HAN) 進行文本分類。
第四步:設計排序函數,更新seed words我們設計出一個打分函數,用于表示單詞w僅高頻的出現在類別為的文檔。分值越高,表示單詞w對類別越重要。我們可以選擇分值最高的前幾個單詞作為新的seed word。也可以剔除一些不重要的seed word。

其中:
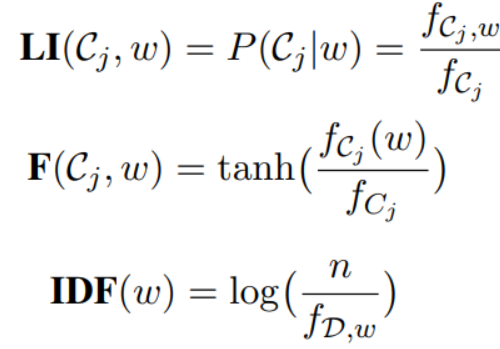
表示類別為的文檔的數量。表示類別為且含有單詞w的文檔的數量。表示在類別為的文檔中,單詞w的詞頻。
n為語料庫D的文檔總數目表示語料庫D中含有單詞w的文檔的數量。
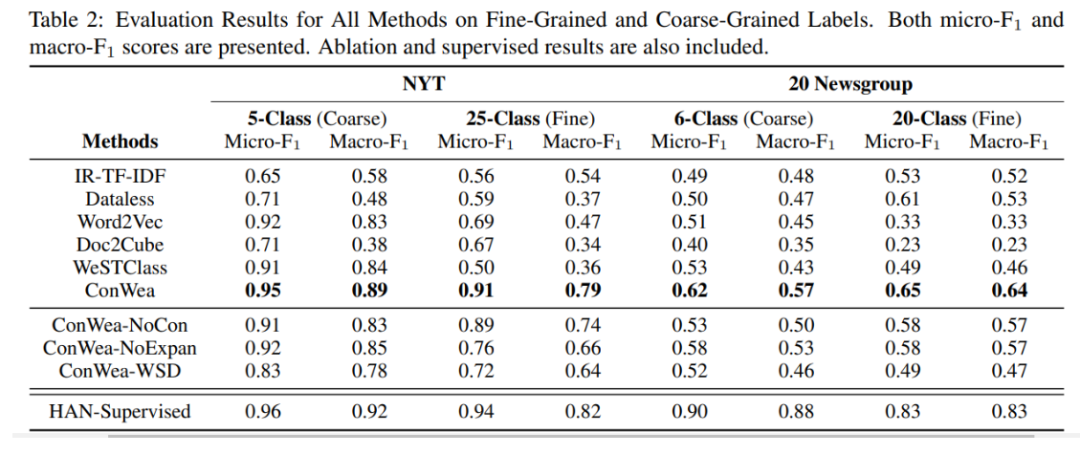
結果
我們的完整模型稱為 ConWea,
而 ConWea-NoCon是 ConWea確實缺少第一步的變體。
ConWea-NoExpan是 ConWea確實缺少第四步的變體。
ConWea-WSD是將 ConWea第一步的方法換成Lesk算法。
責任編輯:xj
原文標題:【ACL2020】基于語境的文本分類弱監督學習
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
文本分類
+關注
關注
0文章
18瀏覽量
7340 -
機器學習
+關注
關注
66文章
8438瀏覽量
133087 -
深度學習
+關注
關注
73文章
5515瀏覽量
121551
原文標題:【ACL2020】基于語境的文本分類弱監督學習
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時空引導下的時間序列自監督學習框架

NPU在深度學習中的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
利用Matlab函數實現深度學習算法
利用TensorFlow實現基于深度神經網絡的文本分類模型
神經網絡如何用無監督算法訓練
深度學習中的時間序列分類方法
卷積神經網絡在文本分類領域的應用
深度學習模型訓練過程詳解
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM

為什么深度學習的效果更好?






 工商網監
工商網監
評論