 NLP:現有聯合抽取工作的不足之處
NLP:現有聯合抽取工作的不足之處
這是一篇關于實體關系聯合抽取的工作。關于現有的聯合抽取工作,作者提出了兩點不足之處:
Feature Confusiong: 用于同樣的特征表示進行NER和RE(關系分類)兩項任務,可能會對模型的學習造成誤解;
現有的基于Table-Filling方法去完成聯合抽取的工作,會將表結構轉化成一個序列結構,這樣導致丟失了重要的結構信息。
因此本文的工作有以下特點:
針對NER和RE,分別學習出不同的序列表示(sequence representations)和表格表示(table representations); 這兩種表示能分別捕獲任務相關的信息,同時作者還涉及了一種機制使他們彼此交互;
保持表格的結構,通過神經網絡結構來捕捉二維表格中的結構信息;同時,引入BERT中的attention權重,進行表格中元素表示的學習。
模型的核心部分包括以下模塊:
Text Embedding: 對于一個輸入的包含n個words的句子,其詞向量、字符向量和BERT詞向量的共同構成了每個word的表示。
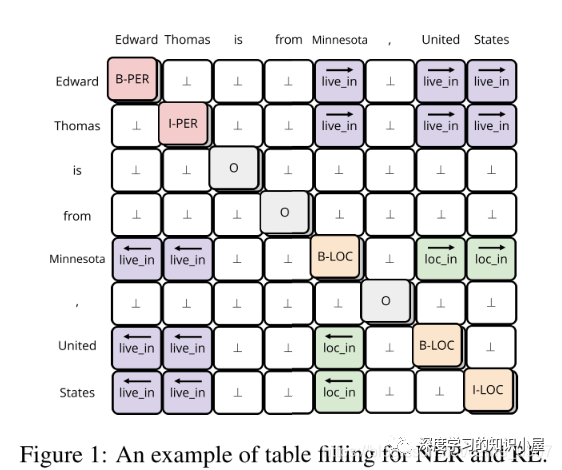
Table Encoder: 目標在于學出 N×N 表格下的向量表示,表格第i行第j列的向量表示,與句子中的第i個和第j個詞相對應,如Figure1所示。文中使用基于GRU結構的MD-RNN(多維RNN)作為Text Encoder,在更新表格中當前cell的信息時,通過MDRNN融合其上下左右四個方向上的信息,從而利用了表格的結構特點;同時引入當前cell所對應的兩個詞在Sequence Encoder下的表示,使得Table Encoder和Sequence Encoder之間發生信息的交流;
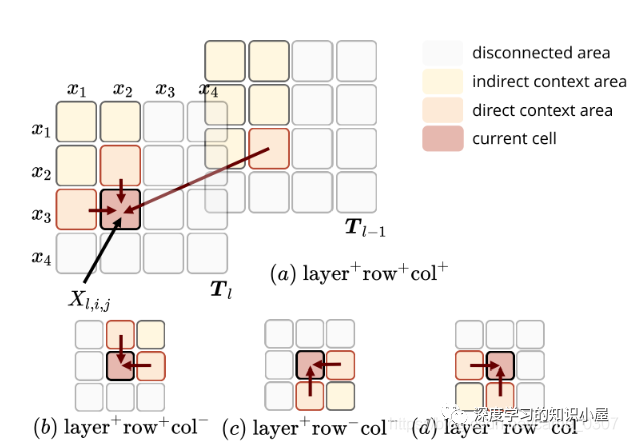
Sequence Encoder: Sequence Encoder的結構與Transformer類似,不同之處在于將Transformer中的scaled dot-product attention 替換為文中提出的 table-guided attention。具體地,將Transformer中計算Q,K之間分值的過程直接替換為對應兩個word在table中對應的向量:
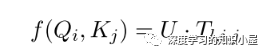
由于 T_ij 融合了四個方向上的信息,能夠更加充分的捕捉上下文信息以及詞與詞之間的關系,同時也使Table Encoder和Sequence Encoder之間產生了雙向的信息交流。
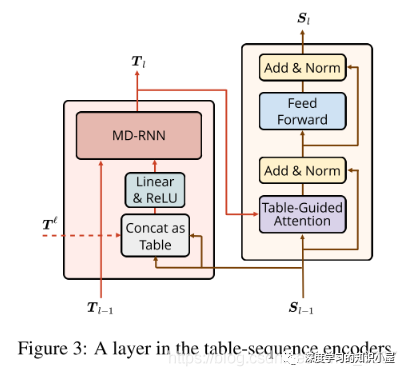
Exploit Pre-trained Attention Weights: Text Embeddings部分有用到BERT,因此將BERT中各個層上多頭attention每個頭上的atention權重堆疊起來,得到張量T l ∈ R N × N × ( L l × A l ) T^{l} in mathbb{R}^{N imes N imes (L^l imes A^l)} T和 Text Embedding中每個詞的表示,來構成Table的初始輸入:
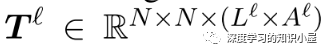
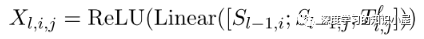
作者通過在不同數據集上的實驗證明了模型的有效性,并通過消融實驗進行了相關的分析。
責任編輯:xj
原文標題:【EMNLP2020】用填表的方式進行實體關系聯合抽取
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
自然語言處理
+關注
關注
1文章
619瀏覽量
13646 -
nlp
+關注
關注
1文章
489瀏覽量
22107
原文標題:【EMNLP2020】用填表的方式進行實體關系聯合抽取
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求助,使用ADS8326IDGKT遇到的疑問求解
PIC單片機的優勢和不足之處
nlp邏輯層次模型的特點
nlp神經語言和NLP自然語言的區別和聯系
nlp自然語言處理框架有哪些
nlp自然語言處理的主要任務及技術方法
nlp自然語言處理模型怎么做
nlp自然語言處理的應用有哪些
NLP技術在人工智能領域的重要性
什么是自然語言處理 (NLP)
特斯拉頻繁調價,馬斯克解釋傳統經銷商模式價格不穩
UART轉RS485電路的不足之處
汽車轉向器軸承滑動力測試深度解析






 工商網監
工商網監
評論