 Kaggle神器LightGBM的最全解讀
Kaggle神器LightGBM的最全解讀
1. LightGBM簡介
GBDT (Gradient Boosting Decision Tree) 是機器學習中一個長盛不衰的模型,其主要思想是利用弱分類器(決策樹)迭代訓練以得到最優模型,該模型具有訓練效果好、不易過擬合等優點。GBDT不僅在工業界應用廣泛,通常被用于多分類、點擊率預測、搜索排序等任務;在各種數據挖掘競賽中也是致命武器,據統計Kaggle上的比賽有一半以上的冠軍方案都是基于GBDT。而LightGBM(Light Gradient Boosting Machine)是一個實現GBDT算法的框架,支持高效率的并行訓練,并且具有更快的訓練速度、更低的內存消耗、更好的準確率、支持分布式可以快速處理海量數據等優點。
1.1 LightGBM提出的動機
常用的機器學習算法,例如神經網絡等算法,都可以以mini-batch的方式訓練,訓練數據的大小不會受到內存限制。而GBDT在每一次迭代的時候,都需要遍歷整個訓練數據多次。如果把整個訓練數據裝進內存則會限制訓練數據的大小;如果不裝進內存,反復地讀寫訓練數據又會消耗非常大的時間。尤其面對工業級海量的數據,普通的GBDT算法是不能滿足其需求的。
LightGBM提出的主要原因就是為了解決GBDT在海量數據遇到的問題,讓GBDT可以更好更快地用于工業實踐。
1.2 XGBoost的缺點及LightGBM的優化
(1)XGBoost的缺點
在LightGBM提出之前,最有名的GBDT工具就是XGBoost了,它是基于預排序方法的決策樹算法。這種構建決策樹的算法基本思想是:首先,對所有特征都按照特征的數值進行預排序。其次,在遍歷分割點的時候用的代價找到一個特征上的最好分割點。最后,在找到一個特征的最好分割點后,將數據分裂成左右子節點。
這樣的預排序算法的優點是能精確地找到分割點。但是缺點也很明顯:首先,空間消耗大。這樣的算法需要保存數據的特征值,還保存了特征排序的結果(例如,為了后續快速的計算分割點,保存了排序后的索引),這就需要消耗訓練數據兩倍的內存。其次,時間上也有較大的開銷,在遍歷每一個分割點的時候,都需要進行分裂增益的計算,消耗的代價大。最后,對cache優化不友好。在預排序后,特征對梯度的訪問是一種隨機訪問,并且不同的特征訪問的順序不一樣,無法對cache進行優化。同時,在每一層長樹的時候,需要隨機訪問一個行索引到葉子索引的數組,并且不同特征訪問的順序也不一樣,也會造成較大的cache miss。
(2)LightGBM的優化
為了避免上述XGBoost的缺陷,并且能夠在不損害準確率的條件下加快GBDT模型的訓練速度,lightGBM在傳統的GBDT算法上進行了如下優化:
基于Histogram的決策樹算法。
單邊梯度采樣 Gradient-based One-Side Sampling(GOSS):使用GOSS可以減少大量只具有小梯度的數據實例,這樣在計算信息增益的時候只利用剩下的具有高梯度的數據就可以了,相比XGBoost遍歷所有特征值節省了不少時間和空間上的開銷。
互斥特征捆綁 Exclusive Feature Bundling(EFB):使用EFB可以將許多互斥的特征綁定為一個特征,這樣達到了降維的目的。
帶深度限制的Leaf-wise的葉子生長策略:大多數GBDT工具使用低效的按層生長 (level-wise) 的決策樹生長策略,因為它不加區分的對待同一層的葉子,帶來了很多沒必要的開銷。實際上很多葉子的分裂增益較低,沒必要進行搜索和分裂。LightGBM使用了帶有深度限制的按葉子生長 (leaf-wise) 算法。
直接支持類別特征(Categorical Feature)
支持高效并行
Cache命中率優化
下面我們就詳細介紹以上提到的lightGBM優化算法。
2. LightGBM的基本原理
2.1 基于Histogram的決策樹算法
(1)直方圖算法
Histogram algorithm應該翻譯為直方圖算法,直方圖算法的基本思想是:先把連續的浮點特征值離散化成個整數,同時構造一個寬度為的直方圖。在遍歷數據的時候,根據離散化后的值作為索引在直方圖中累積統計量,當遍歷一次數據后,直方圖累積了需要的統計量,然后根據直方圖的離散值,遍歷尋找最優的分割點。
圖:直方圖算法
直方圖算法簡單理解為:首先確定對于每一個特征需要多少個箱子(bin)并為每一個箱子分配一個整數;然后將浮點數的范圍均分成若干區間,區間個數與箱子個數相等,將屬于該箱子的樣本數據更新為箱子的值;最后用直方圖(#bins)表示。看起來很高大上,其實就是直方圖統計,將大規模的數據放在了直方圖中。
我們知道特征離散化具有很多優點,如存儲方便、運算更快、魯棒性強、模型更加穩定等。對于直方圖算法來說最直接的有以下兩個優點:
內存占用更小:直方圖算法不僅不需要額外存儲預排序的結果,而且可以只保存特征離散化后的值,而這個值一般用位整型存儲就足夠了,內存消耗可以降低為原來的。也就是說XGBoost需要用位的浮點數去存儲特征值,并用位的整形去存儲索引,而 LightGBM只需要用 位去存儲直方圖,內存相當于減少為;
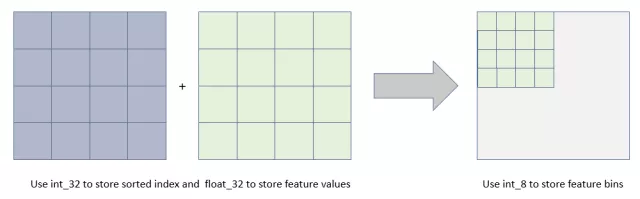
圖:內存占用優化為預排序算法的1/8
計算代價更小:預排序算法XGBoost每遍歷一個特征值就需要計算一次分裂的增益,而直方圖算法LightGBM只需要計算次(可以認為是常數),直接將時間復雜度從降低到,而我們知道。
當然,Histogram算法并不是完美的。由于特征被離散化后,找到的并不是很精確的分割點,所以會對結果產生影響。但在不同的數據集上的結果表明,離散化的分割點對最終的精度影響并不是很大,甚至有時候會更好一點。原因是決策樹本來就是弱模型,分割點是不是精確并不是太重要;較粗的分割點也有正則化的效果,可以有效地防止過擬合;即使單棵樹的訓練誤差比精確分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下沒有太大的影響。
(2)直方圖做差加速
LightGBM另一個優化是Histogram(直方圖)做差加速。一個葉子的直方圖可以由它的父親節點的直方圖與它兄弟的直方圖做差得到,在速度上可以提升一倍。通常構造直方圖時,需要遍歷該葉子上的所有數據,但直方圖做差僅需遍歷直方圖的k個桶。在實際構建樹的過程中,LightGBM還可以先計算直方圖小的葉子節點,然后利用直方圖做差來獲得直方圖大的葉子節點,這樣就可以用非常微小的代價得到它兄弟葉子的直方圖。

圖:直方圖做差
注意:XGBoost 在進行預排序時只考慮非零值進行加速,而 LightGBM 也采用類似策略:只用非零特征構建直方圖。
2.2 帶深度限制的 Leaf-wise 算法
在Histogram算法之上,LightGBM進行進一步的優化。首先它拋棄了大多數GBDT工具使用的按層生長 (level-wise) 的決策樹生長策略,而使用了帶有深度限制的按葉子生長 (leaf-wise) 算法。
XGBoost 采用 Level-wise 的增長策略,該策略遍歷一次數據可以同時分裂同一層的葉子,容易進行多線程優化,也好控制模型復雜度,不容易過擬合。但實際上Level-wise是一種低效的算法,因為它不加區分的對待同一層的葉子,實際上很多葉子的分裂增益較低,沒必要進行搜索和分裂,因此帶來了很多沒必要的計算開銷。
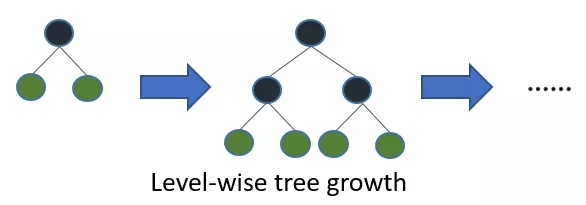
圖:按層生長的決策樹
LightGBM采用Leaf-wise的增長策略,該策略每次從當前所有葉子中,找到分裂增益最大的一個葉子,然后分裂,如此循環。因此同Level-wise相比,Leaf-wise的優點是:在分裂次數相同的情況下,Leaf-wise可以降低更多的誤差,得到更好的精度;Leaf-wise的缺點是:可能會長出比較深的決策樹,產生過擬合。因此LightGBM會在Leaf-wise之上增加了一個最大深度的限制,在保證高效率的同時防止過擬合。
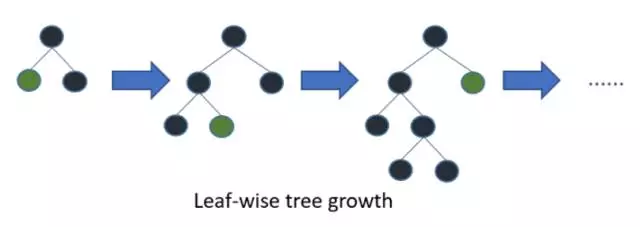
圖:按葉子生長的決策樹
2.3 單邊梯度采樣算法
Gradient-based One-Side Sampling 應該被翻譯為單邊梯度采樣(GOSS)。GOSS算法從減少樣本的角度出發,排除大部分小梯度的樣本,僅用剩下的樣本計算信息增益,它是一種在減少數據量和保證精度上平衡的算法。
AdaBoost中,樣本權重是數據重要性的指標。然而在GBDT中沒有原始樣本權重,不能應用權重采樣。幸運的是,我們觀察到GBDT中每個數據都有不同的梯度值,對采樣十分有用。即梯度小的樣本,訓練誤差也比較小,說明數據已經被模型學習得很好了,直接想法就是丟掉這部分梯度小的數據。然而這樣做會改變數據的分布,將會影響訓練模型的精確度,為了避免此問題,提出了GOSS算法。
GOSS是一個樣本的采樣算法,目的是丟棄一些對計算信息增益沒有幫助的樣本留下有幫助的。根據計算信息增益的定義,梯度大的樣本對信息增益有更大的影響。因此,GOSS在進行數據采樣的時候只保留了梯度較大的數據,但是如果直接將所有梯度較小的數據都丟棄掉勢必會影響數據的總體分布。所以,GOSS首先將要進行分裂的特征的所有取值按照絕對值大小降序排序(XGBoost一樣也進行了排序,但是LightGBM不用保存排序后的結果),選取絕對值最大的個數據。然后在剩下的較小梯度數據中隨機選擇個數據。接著將這個數據乘以一個常數,這樣算法就會更關注訓練不足的樣本,而不會過多改變原數據集的分布。最后使用這個數據來計算信息增益。下圖是GOSS的具體算法。

圖:單邊梯度采樣算法
2.4 互斥特征捆綁算法
高維度的數據往往是稀疏的,這種稀疏性啟發我們設計一種無損的方法來減少特征的維度。通常被捆綁的特征都是互斥的(即特征不會同時為非零值,像one-hot),這樣兩個特征捆綁起來才不會丟失信息。如果兩個特征并不是完全互斥(部分情況下兩個特征都是非零值),可以用一個指標對特征不互斥程度進行衡量,稱之為沖突比率,當這個值較小時,我們可以選擇把不完全互斥的兩個特征捆綁,而不影響最后的精度。互斥特征捆綁算法(Exclusive Feature Bundling, EFB)指出如果將一些特征進行融合綁定,則可以降低特征數量。這樣在構建直方圖時的時間復雜度從變為,這里指特征融合綁定后特征包的個數,且遠小于。
針對這種想法,我們會遇到兩個問題:
怎么判定哪些特征應該綁在一起(build bundled)?
怎么把特征綁為一個(merge feature)?
(1)解決哪些特征應該綁在一起
將相互獨立的特征進行綁定是一個 NP-Hard 問題,LightGBM的EFB算法將這個問題轉化為圖著色的問題來求解,將所有的特征視為圖的各個頂點,將不是相互獨立的特征用一條邊連接起來,邊的權重就是兩個相連接的特征的總沖突值,這樣需要綁定的特征就是在圖著色問題中要涂上同一種顏色的那些點(特征)。此外,我們注意到通常有很多特征,盡管不是%相互排斥,但也很少同時取非零值。如果我們的算法可以允許一小部分的沖突,我們可以得到更少的特征包,進一步提高計算效率。經過簡單的計算,隨機污染小部分特征值將影響精度最多,是每個綁定中的最大沖突比率,當其相對較小時,能夠完成精度和效率之間的平衡。具體步驟可以總結如下:
構造一個加權無向圖,頂點是特征,邊有權重,其權重與兩個特征間沖突相關;
根據節點的度進行降序排序,度越大,與其它特征的沖突越大;
遍歷每個特征,將它分配給現有特征包,或者新建一個特征包,使得總體沖突最小。
算法允許兩兩特征并不完全互斥來增加特征捆綁的數量,通過設置最大沖突比率來平衡算法的精度和效率。EFB 算法的偽代碼如下所示:

圖:貪心綁定算法
算法3的時間復雜度是,訓練之前只處理一次,其時間復雜度在特征不是特別多的情況下是可以接受的,但難以應對百萬維度的特征。為了繼續提高效率,LightGBM提出了一種更加高效的無圖的排序策略:將特征按照非零值個數排序,這和使用圖節點的度排序相似,因為更多的非零值通常會導致沖突,新算法在算法3基礎上改變了排序策略。
(2)解決怎么把特征綁為一捆
特征合并算法,其關鍵在于原始特征能從合并的特征中分離出來。綁定幾個特征在同一個bundle里需要保證綁定前的原始特征的值可以在bundle中識別,考慮到histogram-based算法將連續的值保存為離散的bins,我們可以使得不同特征的值分到bundle中的不同bin(箱子)中,這可以通過在特征值中加一個偏置常量來解決。比如,我們在bundle中綁定了兩個特征A和B,A特征的原始取值為區間,B特征的原始取值為區間,我們可以在B特征的取值上加一個偏置常量,將其取值范圍變為,綁定后的特征取值范圍為,這樣就可以放心的融合特征A和B了。具體的特征合并算法如下所示:

圖:特征合并算法
3. LightGBM的工程優化
我們將論文《Lightgbm: A highly efficient gradient boosting decision tree》中沒有提到的優化方案,而在其相關論文《A communication-efficient parallel algorithm for decision tree》中提到的優化方案,放到本節作為LightGBM的工程優化來向大家介紹。
3.1 直接支持類別特征
實際上大多數機器學習工具都無法直接支持類別特征,一般需要把類別特征,通過 one-hot 編碼,轉化到多維的特征,降低了空間和時間的效率。但我們知道對于決策樹來說并不推薦使用 one-hot 編碼,尤其當類別特征中類別個數很多的情況下,會存在以下問題:
會產生樣本切分不平衡問題,導致切分增益非常小(即浪費了這個特征)。使用 one-hot編碼,意味著在每一個決策節點上只能使用one vs rest(例如是不是狗,是不是貓等)的切分方式。例如,動物類別切分后,會產生是否狗,是否貓等一系列特征,這一系列特征上只有少量樣本為,大量樣本為,這時候切分樣本會產生不平衡,這意味著切分增益也會很小。較小的那個切分樣本集,它占總樣本的比例太小,無論增益多大,乘以該比例之后幾乎可以忽略;較大的那個拆分樣本集,它幾乎就是原始的樣本集,增益幾乎為零。比較直觀的理解就是不平衡的切分和不切分沒有區別。
會影響決策樹的學習。因為就算可以對這個類別特征進行切分,獨熱編碼也會把數據切分到很多零散的小空間上,如下圖左邊所示。而決策樹學習時利用的是統計信息,在這些數據量小的空間上,統計信息不準確,學習效果會變差。但如果使用下圖右邊的切分方法,數據會被切分到兩個比較大的空間,進一步的學習也會更好。下圖右邊葉子節點的含義是或者放到左孩子,其余放到右孩子。
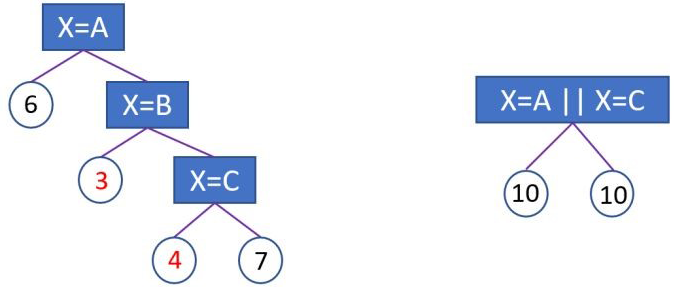
圖:左圖為基于 one-hot 編碼進行分裂,右圖為 LightGBM 基于 many-vs-many 進行分裂
而類別特征的使用在實踐中是很常見的。且為了解決one-hot編碼處理類別特征的不足,LightGBM優化了對類別特征的支持,可以直接輸入類別特征,不需要額外的展開。LightGBM采用 many-vs-many 的切分方式將類別特征分為兩個子集,實現類別特征的最優切分。假設某維特征有個類別,則有種可能,時間復雜度為,LightGBM 基于 Fisher的《On Grouping For Maximum Homogeneity》論文實現了的時間復雜度。
算法流程如下圖所示,在枚舉分割點之前,先把直方圖按照每個類別對應的label均值進行排序;然后按照排序的結果依次枚舉最優分割點。從下圖可以看到,為類別的均值。當然,這個方法很容易過擬合,所以LightGBM里面還增加了很多對于這個方法的約束和正則化。
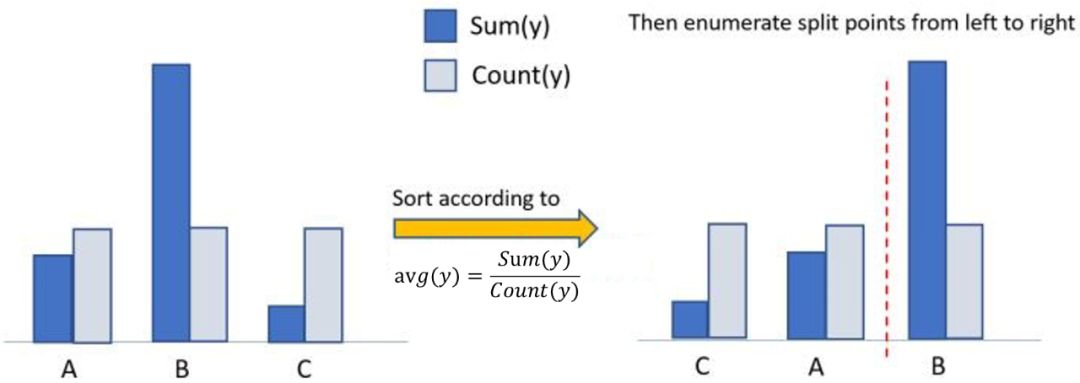
圖:LightGBM求解類別特征的最優切分算法
在Expo數據集上的實驗結果表明,相比展開的方法,使用LightGBM支持的類別特征可以使訓練速度加速倍,并且精度一致。更重要的是,LightGBM是第一個直接支持類別特征的GBDT工具。
3.2 支持高效并行
(1)特征并行
特征并行的主要思想是不同機器在不同的特征集合上分別尋找最優的分割點,然后在機器間同步最優的分割點。XGBoost使用的就是這種特征并行方法。這種特征并行方法有個很大的缺點:就是對數據進行垂直劃分,每臺機器所含數據不同,然后使用不同機器找到不同特征的最優分裂點,劃分結果需要通過通信告知每臺機器,增加了額外的復雜度。
LightGBM 則不進行數據垂直劃分,而是在每臺機器上保存全部訓練數據,在得到最佳劃分方案后可在本地執行劃分而減少了不必要的通信。具體過程如下圖所示。
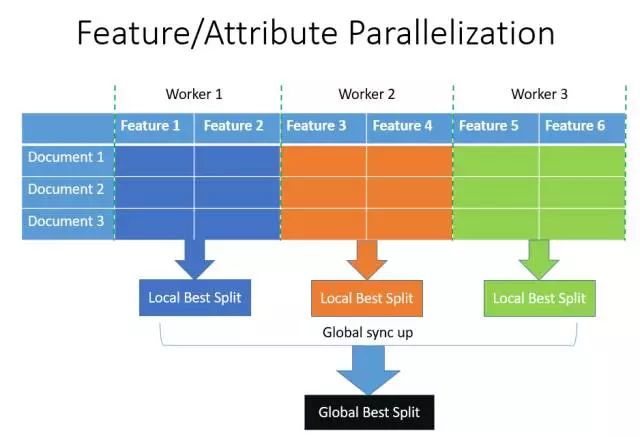
圖:特征并行
(2)數據并行
傳統的數據并行策略主要為水平劃分數據,讓不同的機器先在本地構造直方圖,然后進行全局的合并,最后在合并的直方圖上面尋找最優分割點。這種數據劃分有一個很大的缺點:通訊開銷過大。如果使用點對點通信,一臺機器的通訊開銷大約為;如果使用集成的通信,則通訊開銷為。
LightGBM在數據并行中使用分散規約 (Reduce scatter) 把直方圖合并的任務分攤到不同的機器,降低通信和計算,并利用直方圖做差,進一步減少了一半的通信量。具體過程如下圖所示。
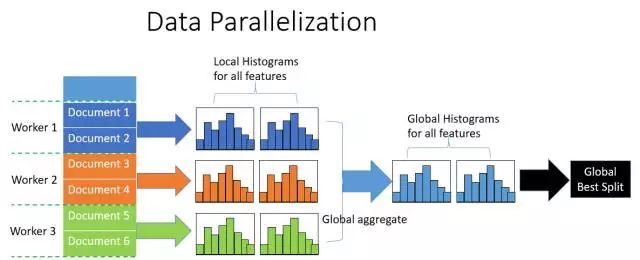
圖:數據并行
(3)投票并行
基于投票的數據并行則進一步優化數據并行中的通信代價,使通信代價變成常數級別。在數據量很大的時候,使用投票并行的方式只合并部分特征的直方圖從而達到降低通信量的目的,可以得到非常好的加速效果。具體過程如下圖所示。
大致步驟為兩步:
本地找出 Top K 特征,并基于投票篩選出可能是最優分割點的特征;
合并時只合并每個機器選出來的特征。
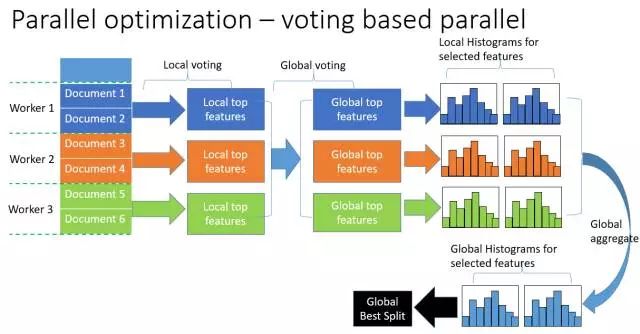
圖:投票并行
3.3 Cache命中率優化
XGBoost對cache優化不友好,如下圖所示。在預排序后,特征對梯度的訪問是一種隨機訪問,并且不同的特征訪問的順序不一樣,無法對cache進行優化。同時,在每一層長樹的時候,需要隨機訪問一個行索引到葉子索引的數組,并且不同特征訪問的順序也不一樣,也會造成較大的cache miss。為了解決緩存命中率低的問題,XGBoost 提出了緩存訪問算法進行改進。
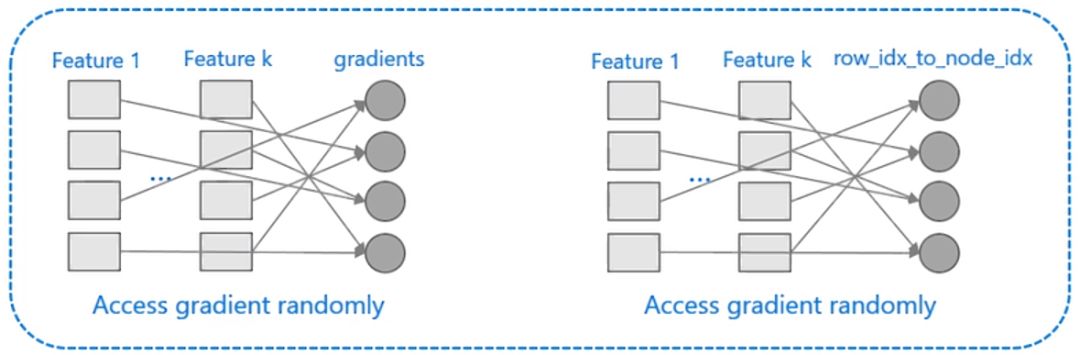
圖:隨機訪問會造成cache miss
而 LightGBM 所使用直方圖算法對 Cache 天生友好:
首先,所有的特征都采用相同的方式獲得梯度(區別于XGBoost的不同特征通過不同的索引獲得梯度),只需要對梯度進行排序并可實現連續訪問,大大提高了緩存命中率;
其次,因為不需要存儲行索引到葉子索引的數組,降低了存儲消耗,而且也不存在 Cache Miss的問題。
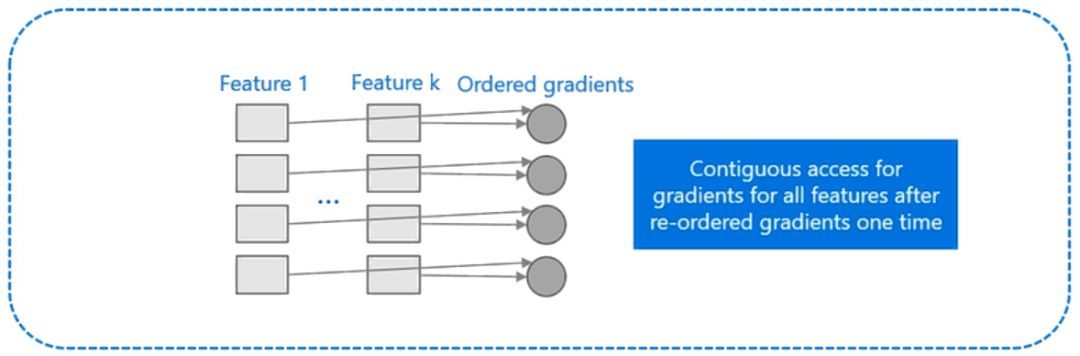
圖:LightGBM增加緩存命中率
4. LightGBM的優缺點
4.1 優點
這部分主要總結下 LightGBM 相對于 XGBoost 的優點,從內存和速度兩方面進行介紹。
(1)速度更快
LightGBM 采用了直方圖算法將遍歷樣本轉變為遍歷直方圖,極大的降低了時間復雜度;
LightGBM 在訓練過程中采用單邊梯度算法過濾掉梯度小的樣本,減少了大量的計算;
LightGBM 采用了基于 Leaf-wise 算法的增長策略構建樹,減少了很多不必要的計算量;
LightGBM 采用優化后的特征并行、數據并行方法加速計算,當數據量非常大的時候還可以采用投票并行的策略;
LightGBM 對緩存也進行了優化,增加了緩存命中率;
(2)內存更小
XGBoost使用預排序后需要記錄特征值及其對應樣本的統計值的索引,而 LightGBM 使用了直方圖算法將特征值轉變為 bin 值,且不需要記錄特征到樣本的索引,將空間復雜度從降低為,極大的減少了內存消耗;
LightGBM 采用了直方圖算法將存儲特征值轉變為存儲 bin 值,降低了內存消耗;
LightGBM 在訓練過程中采用互斥特征捆綁算法減少了特征數量,降低了內存消耗。
4.2 缺點
可能會長出比較深的決策樹,產生過擬合。因此LightGBM在Leaf-wise之上增加了一個最大深度限制,在保證高效率的同時防止過擬合;
Boosting族是迭代算法,每一次迭代都根據上一次迭代的預測結果對樣本進行權重調整,所以隨著迭代不斷進行,誤差會越來越小,模型的偏差(bias)會不斷降低。由于LightGBM是基于偏差的算法,所以會對噪點較為敏感;
在尋找最優解時,依據的是最優切分變量,沒有將最優解是全部特征的綜合這一理念考慮進去;
5. LightGBM實例
本篇文章所有數據集和代碼均在我的GitHub中,地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/LightGBM
5.1 安裝LightGBM依賴包
pipinstalllightgbm
5.2 LightGBM分類和回歸
LightGBM有兩大類接口:LightGBM原生接口 和 scikit-learn接口 ,并且LightGBM能夠實現分類和回歸兩種任務。
(1)基于LightGBM原生接口的分類
importlightgbmaslgb
fromsklearnimportdatasets
fromsklearn.model_selectionimporttrain_test_split
importnumpyasnp
fromsklearn.metricsimportroc_auc_score,accuracy_score
#加載數據
iris=datasets.load_iris()
#劃分訓練集和測試集
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.3)
#轉換為Dataset數據格式
train_data=lgb.Dataset(X_train,label=y_train)
validation_data=lgb.Dataset(X_test,label=y_test)
#參數
params={
learning_rate:0.1,
lambda_l1:0.1,
lambda_l2:0.2,
max_depth:4,
objective:multiclass,#目標函數
num_class:3,
}
#模型訓練
gbm=lgb.train(params,train_data,valid_sets=[validation_data])
#模型預測
y_pred=gbm.predict(X_test)
y_pred=[list(x).index(max(x))forxiny_pred]
print(y_pred)
#模型評估
print(accuracy_score(y_test,y_pred))
(2)基于Scikit-learn接口的分類
fromlightgbmimportLGBMClassifier
fromsklearn.metricsimportaccuracy_score
fromsklearn.model_selectionimportGridSearchCV
fromsklearn.datasetsimportload_iris
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.externalsimportjoblib
#加載數據
iris=load_iris()
data=iris.data
target=iris.target
#劃分訓練數據和測試數據
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.2)
#模型訓練
gbm=LGBMClassifier(num_leaves=31,learning_rate=0.05,n_estimators=20)
gbm.fit(X_train,y_train,eval_set=[(X_test,y_test)],early_stopping_rounds=5)
#模型存儲
joblib.dump(gbm,loan_model.pkl)
#模型加載
gbm=joblib.load(loan_model.pkl)
#模型預測
y_pred=gbm.predict(X_test,num_iteration=gbm.best_iteration_)
#模型評估
print(Theaccuracyofpredictionis:,accuracy_score(y_test,y_pred))
#特征重要度
print(Featureimportances:,list(gbm.feature_importances_))
#網格搜索,參數優化
estimator=LGBMClassifier(num_leaves=31)
param_grid={
learning_rate:[0.01,0.1,1],
n_estimators:[20,40]
}
gbm=GridSearchCV(estimator,param_grid)
gbm.fit(X_train,y_train)
print(Bestparametersfoundbygridsearchare:,gbm.best_params_)
(3)基于LightGBM原生接口的回歸
對于LightGBM解決回歸問題,我們用Kaggle比賽中回歸問題:House Prices: Advanced Regression Techniques,地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques 來進行實例講解。
該房價預測的訓練數據集中一共有列,第一列是Id,最后一列是label,中間列是特征。這列特征中,有列是分類型變量,列是整數變量,列是浮點型變量。訓練數據集中存在缺失值。
importpandasaspd
fromsklearn.model_selectionimporttrain_test_split
importlightgbmaslgb
fromsklearn.metricsimportmean_absolute_error
fromsklearn.preprocessingimportImputer
#1.讀文件
data=pd.read_csv(./dataset/train.csv)
#2.切分數據輸入:特征輸出:預測目標變量
y=data.SalePrice
X=data.drop([SalePrice],axis=1).select_dtypes(exclude=[object])
#3.切分訓練集、測試集,切分比例7.5:2.5
train_X,test_X,train_y,test_y=train_test_split(X.values,y.values,test_size=0.25)
#4.空值處理,默認方法:使用特征列的平均值進行填充
my_imputer=Imputer()
train_X=my_imputer.fit_transform(train_X)
test_X=my_imputer.transform(test_X)
#5.轉換為Dataset數據格式
lgb_train=lgb.Dataset(train_X,train_y)
lgb_eval=lgb.Dataset(test_X,test_y,reference=lgb_train)
#6.參數
params={
task:train,
boosting_type:gbdt,#設置提升類型
objective:regression,#目標函數
metric:{l2,auc},#評估函數
num_leaves:31,#葉子節點數
learning_rate:0.05,#學習速率
feature_fraction:0.9,#建樹的特征選擇比例
bagging_fraction:0.8,#建樹的樣本采樣比例
bagging_freq:5,#k意味著每k次迭代執行bagging
verbose:1#<0?顯示致命的,?=0?顯示錯誤?(警告),?>0顯示信息
}
#7.調用LightGBM模型,使用訓練集數據進行訓練(擬合)
#Addverbosity=2toprintmessageswhilerunningboosting
my_model=lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5)
#8.使用模型對測試集數據進行預測
predictions=my_model.predict(test_X,num_iteration=my_model.best_iteration)
#9.對模型的預測結果進行評判(平均絕對誤差)
print("MeanAbsoluteError:"+str(mean_absolute_error(predictions,test_y)))
(4)基于Scikit-learn接口的回歸
importpandasaspd
fromsklearn.model_selectionimporttrain_test_split
importlightgbmaslgb
fromsklearn.metricsimportmean_absolute_error
fromsklearn.preprocessingimportImputer
#1.讀文件
data=pd.read_csv(./dataset/train.csv)
#2.切分數據輸入:特征輸出:預測目標變量
y=data.SalePrice
X=data.drop([SalePrice],axis=1).select_dtypes(exclude=[object])
#3.切分訓練集、測試集,切分比例7.5:2.5
train_X,test_X,train_y,test_y=train_test_split(X.values,y.values,test_size=0.25)
#4.空值處理,默認方法:使用特征列的平均值進行填充
my_imputer=Imputer()
train_X=my_imputer.fit_transform(train_X)
test_X=my_imputer.transform(test_X)
#5.調用LightGBM模型,使用訓練集數據進行訓練(擬合)
#Addverbosity=2toprintmessageswhilerunningboosting
my_model=lgb.LGBMRegressor(objective=regression,num_leaves=31,learning_rate=0.05,n_estimators=20,
verbosity=2)
my_model.fit(train_X,train_y,verbose=False)
#6.使用模型對測試集數據進行預測
predictions=my_model.predict(test_X)
#7.對模型的預測結果進行評判(平均絕對誤差)
print("MeanAbsoluteError:"+str(mean_absolute_error(predictions,test_y)))
5.3 LightGBM調參
在上一部分中,LightGBM模型的參數有一部分進行了簡單的設置,但大都使用了模型的默認參數,但默認參數并不是最好的。要想讓LightGBM表現的更好,需要對LightGBM模型進行參數微調。下圖展示的是回歸模型需要調節的參數,分類模型需要調節的參數與此類似。
圖:LightGBM回歸模型調參
6. 關于LightGBM若干問題的思考
6.1 LightGBM與XGBoost的聯系和區別有哪些?
(1)LightGBM使用了基于histogram的決策樹算法,這一點不同于XGBoost中的貪心算法和近似算法,histogram算法在內存和計算代價上都有不小優勢。1)內存上優勢:很明顯,直方圖算法的內存消耗為(因為對特征分桶后只需保存特征離散化之后的值),而XGBoost的貪心算法內存消耗為:,因為XGBoost既要保存原始feature的值,也要保存這個值的順序索引,這些值需要位的浮點數來保存。2)計算上的優勢:預排序算法在選擇好分裂特征計算分裂收益時需要遍歷所有樣本的特征值,時間為,而直方圖算法只需要遍歷桶就行了,時間為。
(2)XGBoost采用的是level-wise的分裂策略,而LightGBM采用了leaf-wise的策略,區別是XGBoost對每一層所有節點做無差別分裂,可能有些節點的增益非常小,對結果影響不大,但是XGBoost也進行了分裂,帶來了不必要的開銷。leaft-wise的做法是在當前所有葉子節點中選擇分裂收益最大的節點進行分裂,如此遞歸進行,很明顯leaf-wise這種做法容易過擬合,因為容易陷入比較高的深度中,因此需要對最大深度做限制,從而避免過擬合。
(3)XGBoost在每一層都動態構建直方圖,因為XGBoost的直方圖算法不是針對某個特定的特征,而是所有特征共享一個直方圖(每個樣本的權重是二階導),所以每一層都要重新構建直方圖,而LightGBM中對每個特征都有一個直方圖,所以構建一次直方圖就夠了。
(4)LightGBM使用直方圖做差加速,一個子節點的直方圖可以通過父節點的直方圖減去兄弟節點的直方圖得到,從而加速計算。
(5)LightGBM支持類別特征,不需要進行獨熱編碼處理。
(6)LightGBM優化了特征并行和數據并行算法,除此之外還添加了投票并行方案。
(7)LightGBM采用基于梯度的單邊采樣來減少訓練樣本并保持數據分布不變,減少模型因數據分布發生變化而造成的模型精度下降。
(8)特征捆綁轉化為圖著色問題,減少特征數量。
原文標題:Kaggle神器LightGBM最全解讀!
文章出處:【微信公眾號:通信信號處理研究所】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
內存
+關注
關注
8文章
3055瀏覽量
74337 -
機器學習
+關注
關注
66文章
8441瀏覽量
133092
原文標題:Kaggle神器LightGBM最全解讀!
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
xgboost與LightGBM的優勢對比
PCM1680 does not support a board-to-board interface不支持板對板的是怎么解讀?


嵌入式澆花神器拆解

解讀MIPI A-PHY與車載Serdes芯片技術與測試
最全!2024年并網及儲能新國標解讀
驍銳單邊安全光柵,安全守護新神器








 工商網監
工商網監
評論