 時序數據庫的前世今生
時序數據庫的前世今生
時序數據庫忽然火了起來。Facebook開源了beringei時序數據庫,基于PostgreSQL打造的時序數據庫TimeScaleDB也開源了。時序數據庫作為物聯網方向一個非常重要的服務,業界的頻頻發聲,正說明各家企業已經迫不及待的擁抱物聯網時代的到來。
本文會從時序數據庫的基本概念、應用場景、需求與能力等方面一一展開,帶你了解時序數據庫的前世今生。
01
應用場景
時序數據庫是一種針對時序數據高度優化的垂直型數據庫。在制造業、銀行金融、DevOps、社交媒體、衛生保健、智慧家居、網絡等行業都有大量適合時序數據庫的應用場景:
制造業:
比如輕量化的生產管理云平臺,運用物聯網和大數據技術,采集、分析生產過程產生的各類時序數據,實時呈現生產現場的生產進度、目標達成狀況,以及人、機、料的利用狀況,讓生產現場完全透明,提高生產效率。
銀行金融:
傳統證券、新興的加密數字貨幣的交易系統,采集、分析交易過程中產生的時序數據,實現金融量化交易。
DevOps:
IT基礎設施和應用的運維系統,采集、分析設備運行和應用服務運行監控指標,實時掌握設備和應用的健康狀態。
社交媒體:
社交APP大數據平臺,跟蹤用戶交互數據,分析用戶習慣、改善用戶體驗;直播系統,采集直播過程中包括主播、觀眾以及中間各環節的監控指標數據,監控直播質量。
衛生保健:
商業智能工具,采集智能手表,智能手環中的健康數據,跟蹤關鍵指標和業務的總體健康情況;
智慧家居:
居家物聯網平臺,采集家居智能設備數據,實現遠程監控。
網絡:
網絡監控系統,實時呈現網絡延時、帶寬使用情況。
02
時序數據的需求
在上述場景中,特別在IoT物聯網以及OPS運維監控領域,存在海量的監控數據需要存儲管理。以華為云Cloud Eye Service(CES)服務為例,單個Region需要監控7000多萬個監控指標,每秒需要處理90萬個上報的監控指標項,假設每個指標50個字節,一年的監控數據有1PB;自動駕駛的車輛一天各種傳感器監測數據就80G。 傳統關系型數據庫很難支撐這么大的數據量以及這么大的寫入壓力,Hadoop大數據解決方案以及現有的時序數據庫也會面臨非常大的挑戰。大規模IoT物聯網,以及公有云規模的運維監控場景,對時序數據庫的需求主要包括:
持續高性能寫入:
監控指標往往以固定的頻率采集,部分工業物聯網場景傳感器的采集頻率非常高,有的已經達到100ns,公有云運維監控場景基本也是秒級采集。時序數據庫需要支持7*24小時不中斷的持續高壓力寫入。
高性能查詢:
時序數據庫的價值在于數據分析,而且有較高的實時性要求,典型分析任務如異常檢測及預測性維護,這類時序分析任務需要頻繁的從數據庫中獲取大量時序數據,為了保證分析的實時性,時序數據庫需要能快速響應海量數據查詢請求。
低存儲成本:
IoT物聯網及運維監控場景的數據量呈現指數級增長,數據量是典型的OLTP數據庫場景的千倍以上,并且對成本非常敏感,需要提供低成本的存儲方案。
支持海量時間線:
在大規模IoT物聯網及公有云規模的運維場景,需要監控的指標通常在千萬級甚至億級,時序數據庫要能支持億級時間線的管理能力;
彈性:
監控場景也存在業務突發增長的場景,例如:華為Welink服務的運維監控數據在疫情期間暴增100倍,時序數據庫需要提供足夠靈敏的彈性伸縮能力,能夠快速擴容以應對突發的業務增長。
03
開源時序數據庫能力

過去10年,隨著移動互聯網、大數據、人工智能、物聯網、機器學習等相關技術的快速應用和發展,涌現出許多時序數據庫,因為不同數據庫采用的技術和設計初衷不一樣,所以在解決上述時序數據需求上,他們之間也表現出現較大的差異,本文在下面內容將選擇使用最多的幾種開源時序數據庫為分析對象進行討論。
OpenTSDB
OpenTSDB基于Hbase數據庫作為底層存儲,向上封裝自己的邏輯層和對外接口層。這種架構可以充分利用Hbase的特性實現了數據的高可用和較好的寫入性能。但相比Influxdb,OpenTSDB數據棧較長,在讀寫性能和數據壓縮方面都還有進一步優化的空間。
InfluxDB
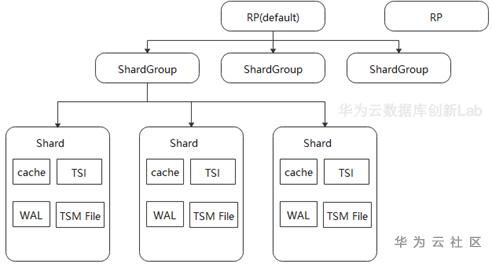
Influxdb是業界比較流行的一個時間序列數據庫,它擁有自研的數據存儲引擎,引入倒排索引增強了多維條件查詢的功能,非常適合在時序業務場景中使用。由于時序洞察報表和時序數據聚合分析,是時序數據庫主要的查詢應用場景,每次查詢可能需要處理上億數據的分組聚合運算,所以在這方面,InfluxDB采用的火山模型對聚合查詢性能影響較大。
Timescale
TimeScale是一個基于傳統關系型數據庫postgresql改造的時間序列數據庫,繼承了postgresql許多優點,比如支持SQL,支持軌跡數據存儲,支持join,可擴展等等,讀寫性能好。TimeScale采用固定schema,數據占用空間大,對于時序業務長期相對固定且對數據存儲成本不敏感的業務來說,也是一種選擇。
04
針對高性能寫入、海量時間線和高數據壓縮的需求,當前還未能有比較好的開源解決方案。GaussDB(For Influx)汲取了開源各家之長,設計了云原生架構的時序數據庫。架構如下圖所示。
相比現有的開源時序數據庫,架構設計上有以下兩方面的考慮:
存儲與計算分離
存儲計算分離,一方面利用成熟的分布式存儲系統提高系統的可靠性。監控數據一直持續高性能寫入,同時還有大量的查詢業務,任何系統故障導致業務中斷甚至數據丟失都會造成嚴重的業務影響,而利用經過驗證的成熟的分布式存儲系統,能夠顯著的提升系統可靠性,降低數據丟失風險,并明顯縮短構建本系統的時間。
另一方面,解除在傳統Share Nothing架構下,數據和節點物理綁定的約束,數據只是邏輯上歸宿于某個計算節點,使得計算節點無狀態化。這樣在擴容計算節點時,可以避免在計算節點間遷移大量的數據,只需要邏輯上將部分數據從一個節點移交給另外一個節點即可,可以將集群擴容的耗時從以天為單位縮短為分鐘級別。
再一方面,通過將多副本復制從計算節點卸載到分布式存儲節點,可以避免用戶以Cloud Hosting形態在云上自建數據庫時,分布式數據庫和分布式存儲分別做3副本復制導致總共9副本冗余的問題,能夠顯著降低存儲成本。
Kernel Bypass
為了避免在用戶態內核態來回拷貝數據帶來的性能損失,GaussDB(for Influx)系統端到端考慮Kernel bypass設計,沒有選擇使用標準的分布式塊或分布式文件服務,而是定制的針對數據庫設計的分布式存儲,對外暴露用戶態接口,計算節點采用容器化部署,通過專用存儲網絡直接和存儲節點通信。
除了架構之外,GaussDB(for Influx)還針對IoT物聯網及運維監控場景的其他需求做了如下優化:
1、寫優化的LSM-Tree布局和異步Logging方案,相比當前時序數據庫提升94%寫性能。
2、通過向量化查詢引擎,ARC Block Cache,以及Aggregation Result Cache提升聚合查詢性能,相比當前時序數據庫提升最高可達9倍;
3、設計針對時序數據分布特征的壓縮算法,壓縮率相比Gorilla提升2倍,并自動將冷數據分級到對象存儲,降低60%存儲成本;
4、優化海量時間線的索引算法,提升索引效率,在千萬時間線量級下,寫入性能是當前時序數據庫的5倍;
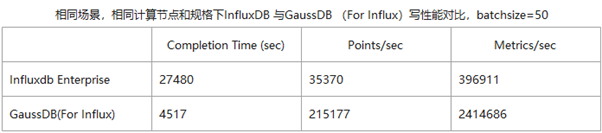
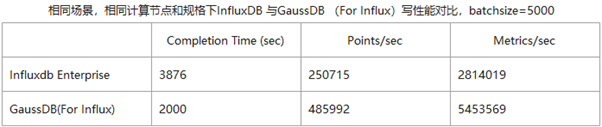
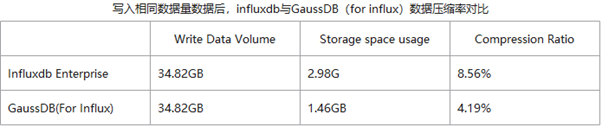
GaussDB(for Influx)成功保障了公司welink和云監控CES兩大服務之后上線商用,接下來我們還將探索如何在海量數據中尋找有價值數據的高效分析方法,為用戶提供更加合適的分析和洞察能力。
參考文獻:
https://zhuanlan.zhihu.com/p/32709932
https://www.cnblogs.com/jpfss/p/12183214.html
責任編輯:xj
原文標題:大廠為啥親睞時序數據庫?讀完你就懂了
文章出處:【微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
-
數據庫
+關注
關注
7文章
3846瀏覽量
64685 -
時序
+關注
關注
5文章
392瀏覽量
37427
原文標題:大廠為啥親睞時序數據庫?讀完你就懂了
文章出處:【微信號:Huawei_Developer,微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分布式云化數據庫有哪些類型
MySQL數據庫的安裝
云數據庫是哪種數據庫類型?
時序數據庫TDengine 2024年保持高增長,實現收入翻倍

數據庫加密辦法
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫事件觸發的設置和應用
數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

有云服務器還需要租用數據庫嗎?
Oracle數據恢復—異常斷電后Oracle數據庫啟庫報錯的數據恢復案例
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例






 工商網監
工商網監
評論