") TensorFlow Lite (TFLite) 在內(nèi)存使用方面的改進(jìn)
TensorFlow Lite (TFLite) 在內(nèi)存使用方面的改進(jìn)
文 /Juhyun Lee 和 Yury Pisarchyk,軟件工程師
由于資源限制嚴(yán)重,必須在苛刻的功耗要求下使用資源有限的硬件,因此在移動(dòng)和嵌入式設(shè)備上進(jìn)行推理頗有難度。在本文中,我們將展示 TensorFlow Lite (TFLite) 在內(nèi)存使用方面的改進(jìn),更適合在邊緣設(shè)備上運(yùn)行推理。
中間張量
一般而言,神經(jīng)網(wǎng)絡(luò)可以視為一個(gè)由算子(例如 CONV_2D 或 FULLY_CONNECTED)和保存中間計(jì)算結(jié)果的張量(稱為中間張量)組成的計(jì)算圖。這些中間張量通常是預(yù)分配的,目的是減少推理延遲,但這樣做會(huì)增加內(nèi)存用量。不過,如果只是以簡單的方式實(shí)現(xiàn),那么在資源受限的環(huán)境下代價(jià)有可能很高,它會(huì)占用大量空間,有時(shí)甚至比模型本身高幾倍。例如,MobileNet v2 中的中間張量占用了 26MB 的內(nèi)存(圖 1),大約是模型本身的兩倍。
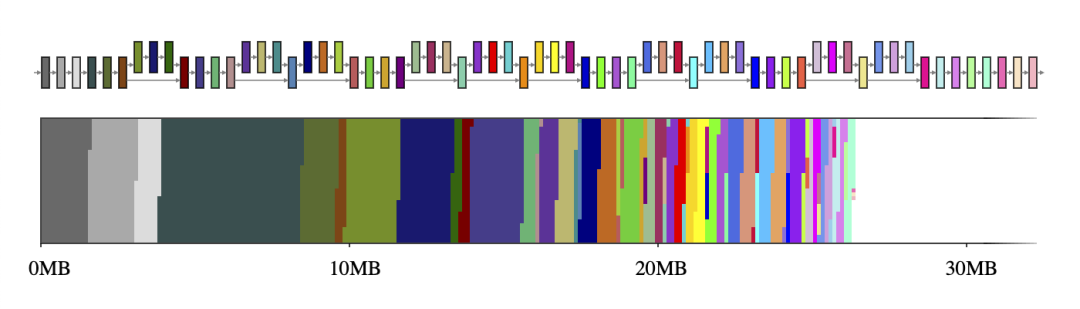
圖 1. MobileNet v2 的中間張量(上圖)及其到二維內(nèi)存空間大小的映射(下圖)。如果每個(gè)中間張量分別使用一個(gè)專用的內(nèi)存緩沖區(qū)(用 65 種不同的顏色表示),它們將占用約 26MB 的運(yùn)行時(shí)內(nèi)存
好消息是,通過數(shù)據(jù)相關(guān)性分析,這些中間張量不必共存于內(nèi)存中。如此一來,我們便可以重用中間張量的內(nèi)存緩沖區(qū),從而減少推理引擎占用的總內(nèi)存。如果網(wǎng)絡(luò)呈簡單的鏈條形狀,則兩個(gè)大內(nèi)存緩沖區(qū)即夠用,因?yàn)樗鼈兛梢栽谡麄€(gè)網(wǎng)絡(luò)中來回互換。然而,對(duì)于形成復(fù)雜計(jì)算圖的任意網(wǎng)絡(luò),這個(gè)NP 完備(NP-complete)資源分配問題需要一個(gè)良好的近似算法。
我們針對(duì)此問題設(shè)計(jì)了許多不同的近似算法,這些算法的表現(xiàn)取決于神經(jīng)網(wǎng)絡(luò)和內(nèi)存緩沖區(qū)的屬性,但都通過張量使用記錄。中間張量的張量使用記錄是一種輔助數(shù)據(jù)結(jié)構(gòu),其中包含有關(guān)張量的大小以及在給定的網(wǎng)絡(luò)執(zhí)行計(jì)劃中首次最后一次使用時(shí)間的信息。借助這些記錄,內(nèi)存管理器能夠在網(wǎng)絡(luò)執(zhí)行的任何時(shí)刻計(jì)算中間張量的使用情況,并優(yōu)化其運(yùn)行時(shí)內(nèi)存以最大限度減少占用空間。
共享內(nèi)存緩沖區(qū)對(duì)象
在 TFLite GPU OpenGL 后端中,我們?yōu)檫@些中間張量采用 GL 紋理。這種方式有幾個(gè)有趣的限制:(a) 紋理一經(jīng)創(chuàng)建便無法修改大小,以及 (b) 在給定時(shí)間只有一個(gè)著色器程序可以獨(dú)占訪問紋理對(duì)象。在這種共享內(nèi)存緩沖區(qū)對(duì)象模式的目標(biāo)是最小化對(duì)象池中創(chuàng)建的所有共享內(nèi)存緩沖區(qū)對(duì)象的大小總和。這種優(yōu)化與眾所周知的寄存器分配問題類似,但每個(gè)對(duì)象的大小可變,因此優(yōu)化起來要復(fù)雜得多。
根據(jù)前面提到的張量使用記錄,我們設(shè)計(jì)了 5 種不同的算法,如表 1 所示。除了“最小成本流”以外,它們都是貪心算法,每個(gè)算法使用不同的啟發(fā)式算法,但仍會(huì)達(dá)到或非常接近理論下限。根據(jù)網(wǎng)絡(luò)拓?fù)洌承┧惴ǖ男阅芤獌?yōu)于其他算法,但總體來說,GREEDY_BY_SIZE_IMPROVED 和 GREEDY_BY_BREADTH 產(chǎn)生的對(duì)象分配占用內(nèi)存最小。
理論下限
https://arxiv.org/abs/2001.03288
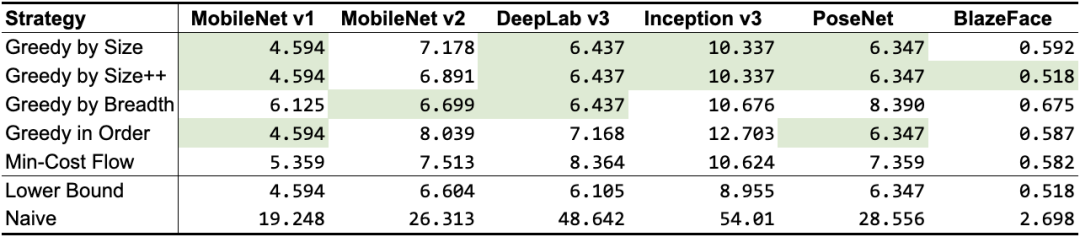
表 1. “共享對(duì)象”策略的內(nèi)存占用量(以 MB 為單位;最佳結(jié)果以綠色突出顯示)。前 5 行是我們的策略,后 2 行用作基準(zhǔn)(“下限”表示最佳數(shù)的近似值,該值可能無法實(shí)現(xiàn),而“樸素”表示為每個(gè)中間張量分配專屬內(nèi)存緩沖區(qū)的情況下可能的最差數(shù))
回到我們的第一個(gè)示例,GREEDY_BY_BREADTH 在 MobileNet v2 上表現(xiàn)最佳,它利用了每個(gè)算子的寬度,即算子配置文件中所有張量的總和。圖 2,尤其是與圖 1 相比,突出了使用智能內(nèi)存管理器的優(yōu)勢。
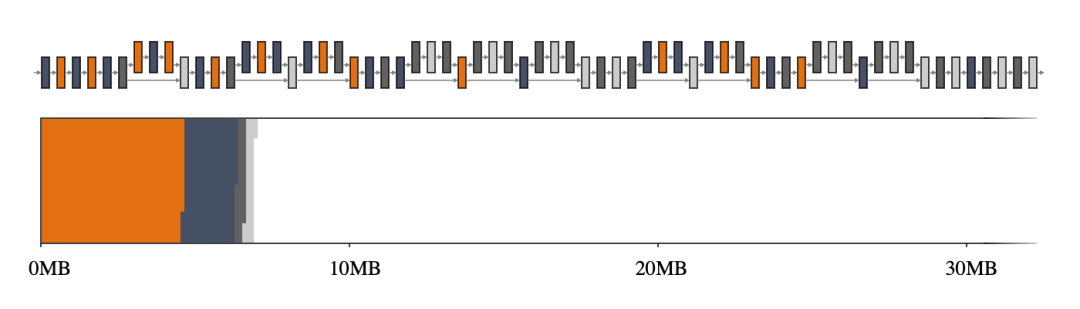
圖 2. MobileNet v2 的中間張量(上圖)及其大小到二維內(nèi)存空間的映射(下圖)。如果中間張量共享內(nèi)存緩沖區(qū)(用 4 種不同的顏色表示),它們僅占用大約 7MB 的運(yùn)行時(shí)內(nèi)存
內(nèi)存偏移量計(jì)算
對(duì)于在 CPU 上運(yùn)行的 TFLite,適用于 GL 紋理的內(nèi)存緩沖區(qū)屬性不適用。因此,更常見的做法是提前分配一個(gè)大內(nèi)存空間,并通過給定偏移量訪問內(nèi)存在所有不干擾其他讀取和寫入操作的讀取器和寫入器之間共享。這種內(nèi)存偏移量計(jì)算法的目的是最大程度地減小內(nèi)存空間的大小。
我們針對(duì)此優(yōu)化問題設(shè)計(jì)了 3 種不同的算法,同時(shí)還分析了先前的研究工作(Sekiyama 等人于 2018 年提出的 Strip Packing)。與“共享對(duì)象”法類似,根據(jù)網(wǎng)絡(luò)的不同,一些算法的性能優(yōu)于其他算法,如表 2 所示。這項(xiàng)研究的一個(gè)收獲是:“偏移量計(jì)算”法通常比“共享對(duì)象”法占用的空間更小。因此,如果適用,應(yīng)該選擇前者而不是后者。
Strip Packing
https://arxiv.org/abs/1804.10001

表 2. “偏移量計(jì)算”策略的內(nèi)存占用量(以 MB 為單位;最佳結(jié)果以綠色突出顯示)。前 3 行是我們的策略,接下來 1 行是先前的研究,后 2 行用作基準(zhǔn)(“下限”表示最佳數(shù)的近似值,該值可能無法實(shí)現(xiàn),而“樸素”表示為每個(gè)中間張量分配專屬內(nèi)存緩沖區(qū)的情況下可能的最差數(shù))
這些針對(duì) CPU 和 GPU 的內(nèi)存優(yōu)化默認(rèn)已隨過去幾個(gè)穩(wěn)定的 TFLite 版本一起提供,并已證明在支持更苛刻的最新模型(如 MobileBERT)方面很有優(yōu)勢。直接查看 GPU 實(shí)現(xiàn)和 CPU 實(shí)現(xiàn),可以找到更多關(guān)于實(shí)現(xiàn)的細(xì)節(jié)。
MobileBERT
https://tfhub.dev/tensorflow/lite-model/mobilebert/1/default/1
GPU 實(shí)現(xiàn)
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/delegates/gpu/common/memory_management
CPU 實(shí)現(xiàn)
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/simple_memory_arena.h
致謝
感謝 Matthias Grundmann、Jared Duke 和 Sarah Sirajuddin,特別感謝 Andrei Kulik 參加了最開始的頭腦風(fēng)暴,同時(shí)感謝 Terry Heo 完成 TFLite 的最終實(shí)現(xiàn)。
責(zé)任編輯:xj
原文標(biāo)題:優(yōu)化 TensorFlow Lite 推理運(yùn)行環(huán)境內(nèi)存占用
文章出處:【微信公眾號(hào):TensorFlow】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101169 -
張量
+關(guān)注
關(guān)注
0文章
7瀏覽量
2595 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60631 -
TensorFlow Lite
+關(guān)注
關(guān)注
0文章
26瀏覽量
647
原文標(biāo)題:優(yōu)化 TensorFlow Lite 推理運(yùn)行環(huán)境內(nèi)存占用
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
南亞科技與補(bǔ)丁科技攜手開發(fā)定制超高帶寬內(nèi)存
如何解決高校宿舍用電浪費(fèi)及管理方面的問題?

Google AI Edge Torch的特性詳解

快速部署Tensorflow和TFLITE模型在Jacinto7 Soc

第四章:在 PC 交叉編譯 aarch64 的 tensorflow 開發(fā)環(huán)境并測試





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論