 使用Softmax的信息來教學 —— 知識蒸餾
使用Softmax的信息來教學 —— 知識蒸餾
導讀
從各個層次給大家講解模型的知識蒸餾的相關內容,并通過實際的代碼給大家進行演示。
公眾號后臺回復“模型蒸餾”,下載已打包好的代碼。
本報告討論了非常厲害模型優化技術 —— 知識蒸餾,并給大家過了一遍相關的TensorFlow的代碼。
“模型集成是一個相當有保證的方法,可以獲得2%的準確性。“ —— Andrej Karpathy
我絕對同意!然而,部署重量級模型的集成在許多情況下并不總是可行的。有時,你的單個模型可能太大(例如GPT-3),以至于通常不可能將其部署到資源受限的環境中。這就是為什么我們一直在研究一些模型優化方法 ——量化和剪枝。在這個報告中,我們將討論一個非常厲害的模型優化技術 —— 知識蒸餾。
Softmax告訴了我們什么?
當處理一個分類問題時,使用softmax作為神經網絡的最后一個激活單元是非常典型的用法。這是為什么呢?因為softmax函數接受一組logit為輸入并輸出離散類別上的概率分布。比如,手寫數字識別中,神經網絡可能有較高的置信度認為圖像為1。不過,也有輕微的可能性認為圖像為7。如果我們只處理像[1,0]這樣的獨熱編碼標簽(其中1和0分別是圖像為1和7的概率),那么這些信息就無法獲得。
人類已經很好地利用了這種相對關系。更多的例子包括,長得很像貓的狗,棕紅色的,貓一樣的老虎等等。正如Hinton等人所認為的
一輛寶馬被誤認為是一輛垃圾車的可能性很小,但被誤認為是一個胡蘿卜的可能性仍然要高很多倍。
這些知識可以幫助我們在各種情況下進行極好的概括。這個思考過程幫助我們更深入地了解我們的模型對輸入數據的想法。它應該與我們考慮輸入數據的方式一致。
所以,現在該做什么?一個迫在眉睫的問題可能會突然出現在我們的腦海中 —— 我們在神經網絡中使用這些知識的最佳方式是什么?讓我們在下一節中找出答案。
使用Softmax的信息來教學 —— 知識蒸餾
softmax信息比獨熱編碼標簽更有用。在這個階段,我們可以得到:
訓練數據
訓練好的神經網絡在測試數據上表現良好
我們現在感興趣的是使用我們訓練過的網絡產生的輸出概率。
考慮教人去認識MNIST數據集的英文數字。你的學生可能會問 —— 那個看起來像7嗎?如果是這樣的話,這絕對是個好消息,因為你的學生,肯定知道1和7是什么樣子。作為一名教師,你能夠把你的數字知識傳授給你的學生。這種想法也有可能擴展到神經網絡。
知識蒸餾的高層機制
所以,這是一個高層次的方法:
訓練一個在數據集上表現良好神經網絡。這個網絡就是“教師”模型。
使用教師模型在相同的數據集上訓練一個學生模型。這里的問題是,學生模型的大小應該比老師的小得多。
本工作流程簡要闡述了知識蒸餾的思想。
為什么要小?這不是我們想要的嗎?將一個輕量級模型部署到生產環境中,從而達到足夠的性能。
用圖像分類的例子來學習
對于一個圖像分類的例子,我們可以擴展前面的高層思想:
訓練一個在圖像數據集上表現良好的教師模型。在這里,交叉熵損失將根據數據集中的真實標簽計算。
在相同的數據集上訓練一個較小的學生模型,但是使用來自教師模型(softmax輸出)的預測作為ground-truth標簽。這些softmax輸出稱為軟標簽。稍后會有更詳細的介紹。
我們為什么要用軟標簽來訓練學生模型?
請記住,在容量方面,我們的學生模型比教師模型要小。因此,如果你的數據集足夠復雜,那么較小的student模型可能不太適合捕捉訓練目標所需的隱藏表示。我們在軟標簽上訓練學生模型來彌補這一點,它提供了比獨熱編碼標簽更有意義的信息。在某種意義上,我們通過暴露一些訓練數據集來訓練學生模型來模仿教師模型的輸出。
希望這能讓你們對知識蒸餾有一個直觀的理解。在下一節中,我們將更詳細地了解學生模型的訓練機制。
知識蒸餾中的損失函數
為了訓練學生模型,我們仍然可以使用教師模型的軟標簽以及學生模型的預測來計算常規交叉熵損失。學生模型很有可能對許多輸入數據點都有信心,并且它會預測出像下面這樣的概率分布:
高置信度的預測
擴展Softmax
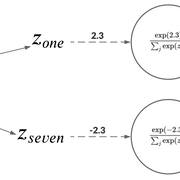
這些弱概率的問題是,它們沒有捕捉到學生模型有效學習所需的信息。例如,如果概率分布像[0.99, 0.01],幾乎不可能傳遞圖像具有數字7的特征的知識。
Hinton等人解決這個問題的方法是,在將原始logits傳遞給softmax之前,將教師模型的原始logits按一定的溫度進行縮放。這樣,就會在可用的類標簽中得到更廣泛的分布。然后用同樣的溫度用于訓練學生模型。
我們可以把學生模型的修正損失函數寫成這個方程的形式:
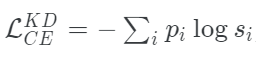
其中,pi是教師模型得到軟概率分布,si的表達式為: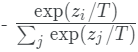
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) returnkd_loss
使用擴展Softmax來合并硬標簽
Hinton等人還探索了在真實標簽(通常是獨熱編碼)和學生模型的預測之間使用傳統交叉熵損失的想法。當訓練數據集很小,并且軟標簽沒有足夠的信號供學生模型采集時,這一點尤其有用。
當它與擴展的softmax相結合時,這種方法的工作效果明顯更好,而整體損失函數成為兩者之間的加權平均。
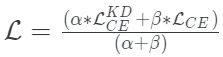
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) ce_loss=tf.keras.losses.sparse_categorical_crossentropy( true_labels,student_logits,from_logits=True) total_loss=(alpha*kd_loss)+(beta*ce_loss) returntotal_loss/(alpha+beta)
建議β的權重小于α。
在原始Logits上進行操作
Caruana等人操作原始logits,而不是softmax值。這個工作流程如下:
這部分保持相同 —— 訓練一個教師模型。這里交叉熵損失將根據數據集中的真實標簽計算。
現在,為了訓練學生模型,訓練目標變成分別最小化來自教師和學生模型的原始對數之間的平均平方誤差。

mse=tf.keras.losses.MeanSquaredError() defmse_kd_loss(teacher_logits,student_logits): returnmse(teacher_logits,student_logits)
使用這個損失函數的一個潛在缺點是它是無界的。原始logits可以捕獲噪聲,而一個小模型可能無法很好的擬合。這就是為什么為了使這個損失函數很好地適合蒸餾狀態,學生模型需要更大一點。
Tang等人探索了在兩個損失之間插值的想法:擴展softmax和MSE損失。數學上,它看起來是這樣的:
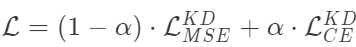
根據經驗,他們發現當α = 0時,(在NLP任務上)可以獲得最佳的性能。
如果你在這一點上感到有點不知怎么辦,不要擔心。希望通過代碼,事情會變得清楚。
一些訓練方法
在本節中,我將向你提供一些在使用知識蒸餾時可以考慮的訓練方法。
使用數據增強
他們在NLP數據集上展示了這個想法,但這也適用于其他領域。為了更好地指導學生模型訓練,使用數據增強會有幫助,特別是當你處理的數據較少的時候。因為我們通常保持學生模型比教師模型小得多,所以我們希望學生模型能夠獲得更多不同的數據,從而更好地捕捉領域知識。
使用標記的和未標記的數據訓練學生模型
在像Noisy Student Training和SimCLRV2這樣的文章中,作者在訓練學生模型時使用了額外的未標記數據。因此,你將使用你的teacher模型來生成未標記數據集上的ground-truth分布。這在很大程度上有助于提高模型的可泛化性。這種方法只有在你所處理的數據集中有未標記數據可用時才可行。有時,情況可能并非如此(例如,醫療保健)。Xie等人探索了數據平衡和數據過濾等技術,以緩解在訓練學生模型時合并未標記數據可能出現的問題。
在訓練教師模型時不要使用標簽平滑
標簽平滑是一種技術,用來放松由模型產生的高可信度預測。它有助于減少過擬合,但不建議在訓練教師模型時使用標簽平滑,因為無論如何,它的logits是按一定的溫度縮放的。因此,一般不推薦在知識蒸餾的情況下使用標簽平滑。
使用更高的溫度值
Hinton等人建議使用更高的溫度值來soften教師模型預測的分布,這樣軟標簽可以為學生模型提供更多的信息。這在處理小型數據集時特別有用。對于更大的數據集,信息可以通過訓練樣本的數量來獲得。
實驗結果
讓我們先回顧一下實驗設置。我在實驗中使用了Flowers數據集。除非另外指定,我使用以下配置:
我使用MobileNetV2作為基本模型進行微調,學習速度設置為1e-5,Adam作為優化器。
我們將τ設置為5。
α = 0.9,β = 0.1。
對于學生模型,使用下面這個簡單的結構:
Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 222, 222, 64) 1792 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 55, 55, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 53, 53, 128) 73856 _________________________________________________________________ global_average_pooling2d_3 ( (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 512) 66048 _________________________________________________________________ dense_4 (Dense) (None, 5) 2565 =================================================================
在訓練學生模型時,我使用Adam作為優化器,學習速度為1e-2。
在使用數據增強訓練student模型的過程中,我使用了與上面提到的相同的默認超參數的加權平均損失。
學生模型基線
為了使性能比較公平,我們還從頭開始訓練淺的CNN并觀察它的性能。注意,在本例中,我使用Adam作為優化器,學習速率為1e-3。
訓練循環
在看到結果之前,我想說明一下訓練循環,以及如何在經典的model.fit()調用中包裝它。這就是訓練循環的樣子:
deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"loss":t_loss,"accuracy":t_acc}
如果你已經熟悉了如何在TensorFlow 2中定制一個訓練循環,那么train_step()函數應該是一個容易閱讀的函數。注意get_kd_loss() 函數。這可以是我們之前討論過的任何損失函數。我們在這里使用的是一個訓練過的教師模型,這個模型我們在前面進行了微調。通過這個訓練循環,我們可以創建一個可以通過.fit()調用進行訓練完整模型。
首先,創建一個擴展tf.keras.Model的類。
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student
當你擴展tf.keras.Model 類的時候,可以將自定義的訓練邏輯放到train_step()函數中(由類提供)。所以,從整體上看,Student類應該是這樣的:
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"train_loss":t_loss,"train_accuracy":t_acc}
你甚至可以編寫一個test_step來自定義模型的評估行為。我們的模型現在可以用以下方式訓練:
student=Student(teacher_model,get_student_model()) optimizer=tf.keras.optimizers.Adam(learning_rate=0.01) student.compile(optimizer) student.fit(train_ds, validation_data=validation_ds, epochs=10)
這種方法的一個潛在優勢是可以很容易地合并其他功能,比如分布式訓練、自定義回調、混合精度等等。
使用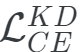 訓練學生模型
訓練學生模型
用這個損失函數訓練我們的淺層學生模型,我們得到~74%的驗證精度。我們看到,在epochs 8之后,損失開始增加。這表明,加強正則化可能會有所幫助。另外,請注意,超參數調優過程在這里有重大影響。在我的實驗中,我沒有做嚴格的超參數調優。為了更快地進行實驗,我縮短了訓練時間。
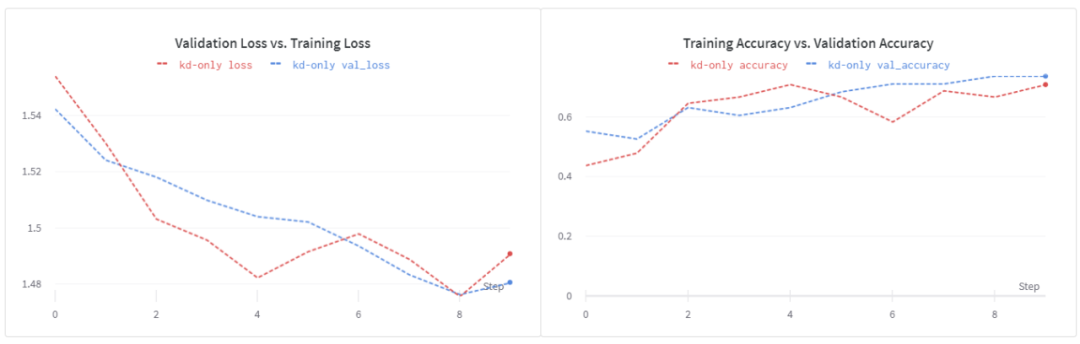
使用
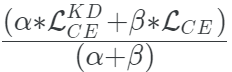
訓練學生模型
現在讓我們看看在蒸餾訓練目標中加入ground truth標簽是否有幫助。在β = 0.1和α = 0.1的情況下,我們得到了大約71%的驗證準確性。再次表明,更強的正則化和更長的訓練時間會有所幫助。
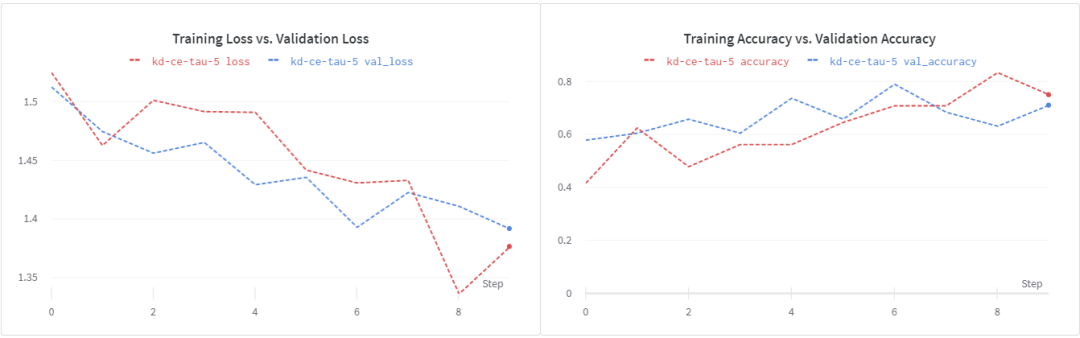
使用 訓練學生模型
訓練學生模型
使用了MSE的損失,我們可以看到驗證精度大幅下降到~56%。同樣的損失也出現了類似的情況,這表明需要進行正則化。
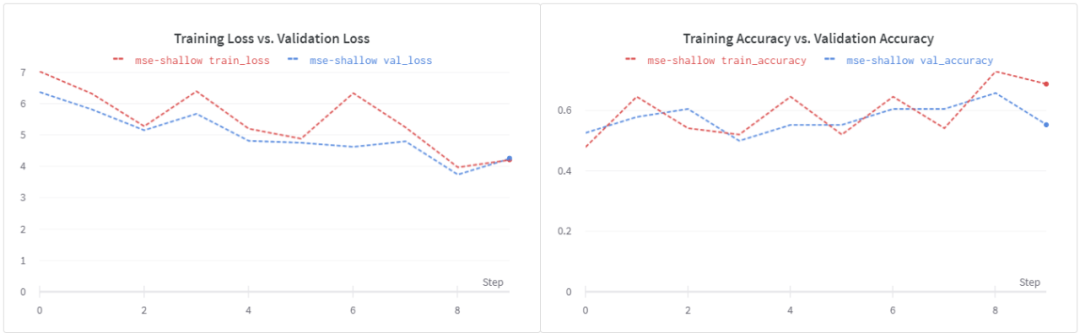
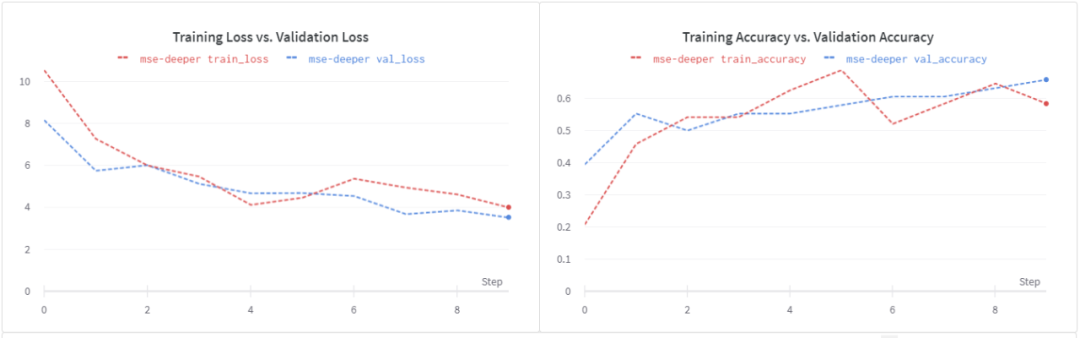
請注意,這個損失函數是無界的,我們的淺學生模型可能無法處理隨之而來的噪音。讓我們嘗試一個更深入的學生模型。
在訓練學生模型的時候使用數據增強
如前所述,學生模式比教師模式的容量更小。在處理較少的數據時,數據增強可以幫助訓練學生模型。我們驗證一下。
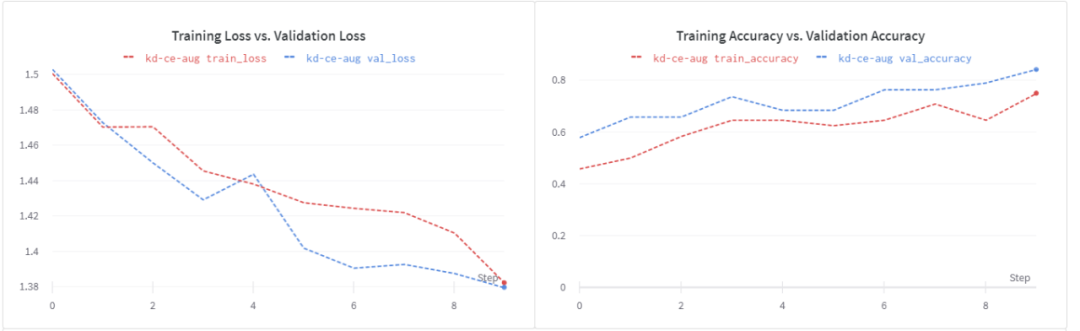
數據增加的好處是非常明顯的:
我們有一個更好的損失曲線。
驗證精度提高到84%。
溫度(τ)的影響
在這個實驗中,我們研究溫度對學生模型的影響。在這個設置中,我使用了相同的淺層CNN。
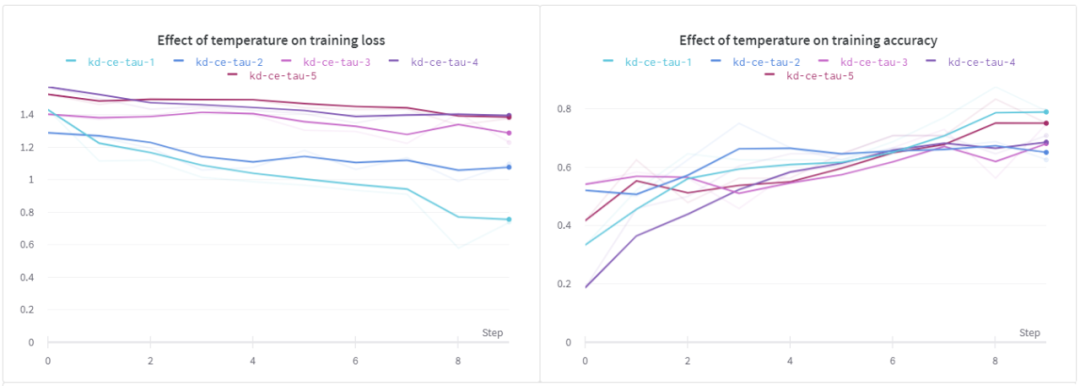
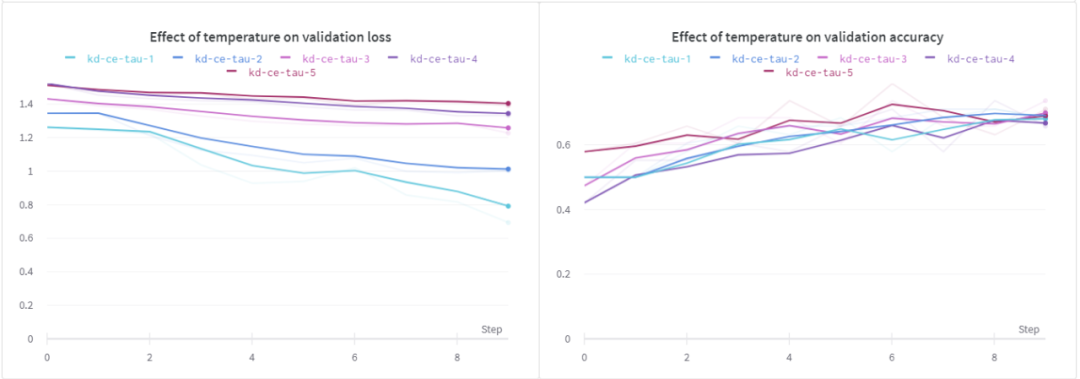
從上面的結果可以看出,當τ為1時,訓練損失和訓練精度均優于其它方法。對于驗證損失,我們可以看到類似的行為,但是在所有不同的溫度下,驗證的準確性似乎幾乎是相同的。
最后,我想研究下微調基線模是否對學生模型有顯著影響。
基線模型調優的效果
在這次實驗中,我選擇了 EfficientNet B0作為基礎模型。讓我們先來看看我用它得到的微調結果。注意,如前所述,所有其他超參數都保持其默認值。
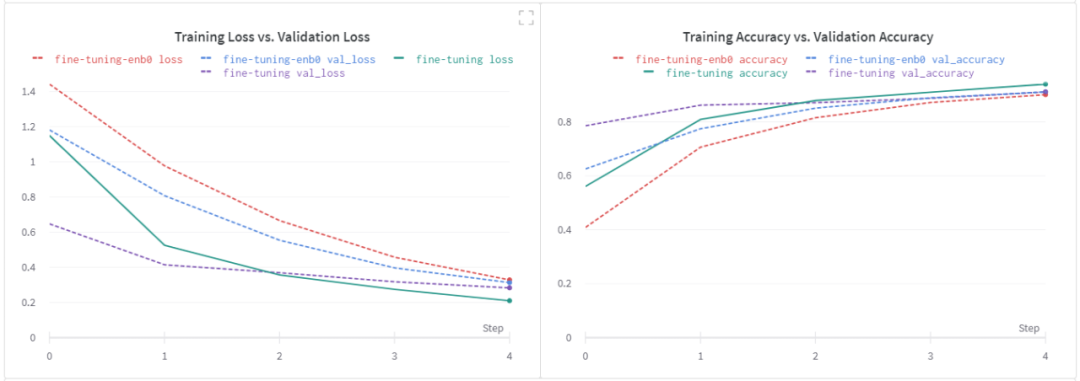
我們在微調步驟中沒有看到任何顯著的改進。我想再次強調,我沒有進行嚴格的超參數調優實驗。基于我從EfficientNet B0得到的邊際改進,我決定在以后的某個時間點進行進一步的實驗。
第一行對應的是用加權平均損失訓練的默認student model,其他行分別對應EfficientNet B0和MobileNetV2。注意,我沒有包括在訓練student模型時通過使用數據增強而得到的結果。
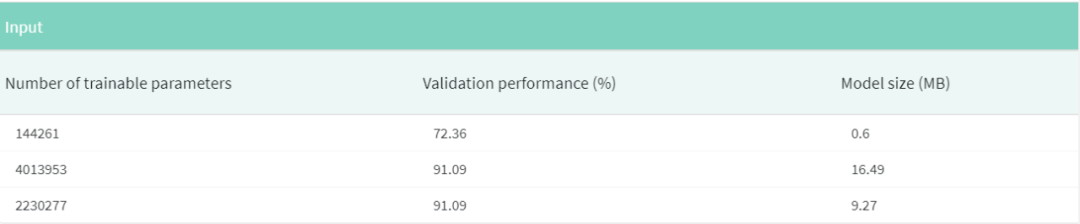
知識蒸餾的一個好處是,它與其他模型優化技術(如量化和修剪)無縫集成。所以,作為一個有趣的實驗,我鼓勵你們自己嘗試一下。
總結
知識蒸餾是一種非常有前途的技術,特別適合于用于部署的目的。它的一個優點是,它可以與量化和剪枝非常無縫地結合在一起,從而在不影響精度的前提下進一步減小生產模型的尺寸。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4781瀏覽量
101178 -
數據集
+關注
關注
4文章
1209瀏覽量
24835 -
Softmax
+關注
關注
0文章
9瀏覽量
2544
原文標題:神經網絡中的蒸餾技術,從Softmax開始說起
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
摩爾線程宣布成功部署DeepSeek蒸餾模型推理服務
大連理工提出基于Wasserstein距離(WD)的知識蒸餾方法
2024全國高校電子信息類專業課程實驗教學案例設計競賽圓滿結束
武漢傳媒學院聯合創龍教儀建設DSP教學實驗箱,基于DSP C6000平臺搭建
荊州學院聯合創龍教儀建設DSP教學實驗箱案例分享
教學驗證篇丨PPEC+HIL BUCK仿真驗證

訊維AI教學分析系統的應用提升整體教學質量
SolidWorks教育版:豐富的教學資源
逆變器電池用蒸餾水理由,金屬觸點完全浸沒

搭配100教學實驗案例,輕松解決老師備課難題!

MR混合現實情景實訓教學系統開發
普源精電支持的RIGOL杯全國高校電子信息類專業課程實驗教學案例設計競賽上榜!





 工商網監
工商網監
評論