 構建算法的推薦步驟
構建算法的推薦步驟
當我們遇到一個問題,比如預測房價,我們想要用機器學習算法來更好的解決這個問題,推薦的步驟如下:
1.1 實現一個簡單的算法
建議先花點時間實現一個簡單能用的算法,比如線性回歸預測房價,不需要一開始就花很多時間設計復雜的算法(在軟件開發中叫避免過早優化)
你可以先實現能用的算法,然后利用上篇文章從 0 開始機器學習 - 機器學習算法診斷中的學習曲線等診斷法來分析算法的優化方向,這樣一個簡單的算法就成為了優化問題的好工具!
1.2 分析學習曲線
有個簡單的算法后,我們就可以畫出學習曲線了,然后就可以決定下一步到底要往哪個方向做優化:
獲得更多的訓練樣本
嘗試減少特征的數量
嘗試獲得更多的特征
嘗試增加多項式特征
嘗試減少正則化程度
嘗試增加正則化程度
...
1.3 誤差分析
假如我們有多個方向可以作為優化的方向,比如以下的方向都可以解決模型的高方差問題:
獲得更多的訓練樣本 - 適用于高方差的模型
嘗試減少特征的數量 - 適用于高方差的模型
嘗試增加正則化程度 - 適用于高方差的模型
那我們又如何來評估每種方法的性能到底提升多少呢?或者說有沒有一種直接的指標來告訴我,使用了這樣一種優化措施后我的算法性能到底提高了多少百分比?
今天就來看看如何分析機器學習算法的誤差。
二、機器學習算法誤差分析
2.1 偏斜類問題
在介紹誤差分析指標前,先來了解一個偏斜類問題:
訓練集中有非常多同一類的樣本,只有很少或者沒有其他類的樣本,這樣的訓練樣本稱為偏斜類。
比如預測癌癥是否惡性的 100 個樣本中:95 個是良性的腫瘤,5 個惡性的腫瘤,假設我們在這個樣本上對比以下 2 種分類算法的百分比準確度,即分類錯誤的百分比:
普通非機器學習算法:人為把所有的樣本都預測為良性,則分錯了 5 個惡性的樣本,錯誤率為 5 / 100 = 0.05 = 5%
神經網絡算法:訓練后預測 100 個樣本,把 10 個良性的樣本誤分類為惡性的樣本,錯誤率為 10 / 100 = 10%
如果僅僅從錯誤率大小來判斷算法的優劣是不合適的,因為第一種人為設置樣本都為良性的算法不會在實際項目中使用,但是通過指標卻發現效果比神經網絡還要好,這肯定是有問題的。
正是因為存在這么一種偏斜類的訓練樣本,所以我們需要用一個更加一般性的算法準確度評價指標,以此適用與任何類型的樣本,解決上面那種荒唐的結論。
2.2 查準率與查全率
為了解決這個問題,使用查準率(Precision)和查全率(Recall)這 2 個誤差指標,為了計算這 2 者,我們需要把算法預測的結果分為以下 4 種:
正確肯定(True Positive,TP):預測為真,實際為真
正確否定(True Negative,TN):預測為假,實際為假
錯誤肯定(False Positive,FP):預測為真,實際為假
錯誤否定(False Negative,FN):預測為假,實際為真
把這 4 個寫到表格里面:
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| 實際值 預測值 |
|---|
然后我們就可以定義這 2 個指標啦:
查準率 = TP / (TP + FP):預測為真(惡性腫瘤)的情況中,實際為真(惡性腫瘤)的比例,越高越好
查全率 = TP / (TP + FN):實際為真(惡性腫瘤)的情況中,預測為真(惡性腫瘤)的比例,越高越好
有了這 2 個指標我們再來分析下上面的算法性能,第一個人為的算法認為所有的腫瘤都是良性的,也就等價于原樣本中 5 個惡性的腫瘤樣本一個都沒有預測成功,也即所有惡性腫瘤樣本,該算法成功預測惡性腫瘤的比例為 0,所以查全率為 0,這說明該算法的效果并不好。
2.3 查準率與查全率的整合
在實際的使用中,查準率和查全率往往不能很好的權衡,要想保持兩者都很高不太容易,通過使用以下的公式來整合這 2 個評價指標可以幫助我們直接看出一個算法的性能優劣:
以后評價一個算法的性能直接比較 F1 Score 即可,這就大大方便了我們對比算法的性能。
三、機器學習的樣本規模
除了評價指標,還有一個要關心的問題就是樣本的規模,在機器學習領域有一句話:「取得成功的人不是擁有最好算法的人,而是擁有最多數據的人」
這句話的意思就是說當我們擁有非常多的數據時,選擇什么樣的算法不是最最重要的,一些在小樣本上表現不好的算法,經過大樣本的訓練往往也能表現良好。
比如下面這 4 種算法在很大樣本上訓練后的效果相差不是很大,但是在小樣本時有挺大差距:
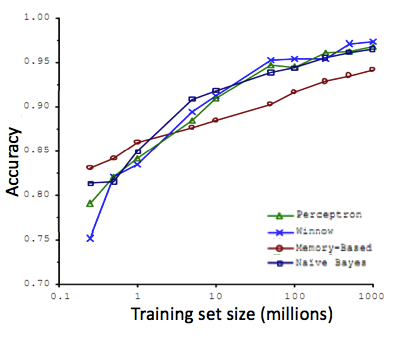
但在實際的機器學習算法中,為了能夠使得訓練數據發揮最大效用,我們往往會選一個比較好的模型(不太容易欠擬合,比如神經網絡),再加上很多的樣本數據(防止過擬合)
通過這 2 者就可以讓一個算法變的很強大,所以以后當你設計機器學習算法的時候一定要考慮自己的樣本規模,選擇合適的模型適應你的數據,如果你有很多很多的數據,那么可以選擇復雜一點的模型,不能白白浪費你的數據!
-
算法
+關注
關注
23文章
4630瀏覽量
93355 -
模型
+關注
關注
1文章
3305瀏覽量
49220 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084
原文標題:從 0 開始機器學習 - 機器學習系統的設計與誤差分析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MAKEFILE條件預構建步驟
怎么將#define值傳遞給后期構建步驟?
PID算法調試步驟
有什么方法可以添加閃存前和閃存后構建步驟嗎?
有什么方法可以添加閃存前和閃存后構建步驟嗎?
基于設備性能的藍牙散列網構建算法
WSN中能量有效的連通支配集構建算法
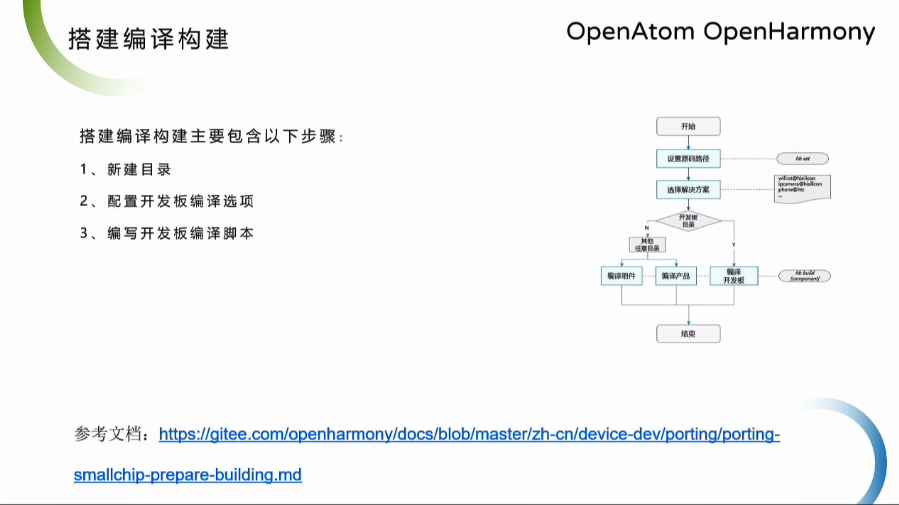
OpenHarmony Dev-Board-SIG專場:搭建編譯構建主要步驟
TensorRT構建具有動態形狀的引擎的步驟
介紹從一組可重用的驗證組件中構建測試平臺所需的步驟
可重用的驗證組件中構建測試平臺的步驟






 工商網監
工商網監
評論