") 一些中文NLP領(lǐng)域,構(gòu)建語(yǔ)料的經(jīng)驗(yàn)和技巧
一些中文NLP領(lǐng)域,構(gòu)建語(yǔ)料的經(jīng)驗(yàn)和技巧
記得寫畢業(yè)論文那會(huì)兒,經(jīng)常為語(yǔ)料發(fā)愁。由于大多數(shù) NLP 問(wèn)題都是有監(jiān)督問(wèn)題,很多時(shí)候我們往往缺的不是算法,而是標(biāo)注好的語(yǔ)料。這在中文語(yǔ)料上更是明顯。今天就和大家分享一些中文 NLP 領(lǐng)域,構(gòu)建語(yǔ)料的經(jīng)驗(yàn)和技巧,雖然未必看了此文就能徹底解決語(yǔ)料的問(wèn)題,但是或多或少會(huì)有些啟發(fā)。
首先分享幾個(gè)常見(jiàn)的語(yǔ)料獲取渠道
國(guó)內(nèi)外NLP領(lǐng)域的會(huì)議評(píng)測(cè)數(shù)據(jù)
相關(guān)研究機(jī)構(gòu)、實(shí)驗(yàn)室、論文公開(kāi)的數(shù)據(jù)集
國(guó)內(nèi)外數(shù)據(jù)科學(xué)競(jìng)賽平臺(tái),kaggle,天池,科賽,CCF等
互聯(lián)網(wǎng)企業(yè)自己舉辦的比賽,如百度,搜狐,知乎,騰訊這些企業(yè)都是土豪,通常會(huì)花費(fèi)巨額的資金標(biāo)注語(yǔ)料
Github 很多模型里面會(huì)自帶部分語(yǔ)料
雖然通過(guò)這些途徑,能夠搜集到不少的NLP語(yǔ)料,但這些“現(xiàn)成”的語(yǔ)料往往與我們需要解決的 NLP 問(wèn)題不太一致,因此我們還得想辦法去變一些語(yǔ)料出來(lái)。
通過(guò)API或開(kāi)源模型標(biāo)注語(yǔ)料
比如我們需要訓(xùn)練一個(gè)命名實(shí)體識(shí)別模型,就可以借助 bosonnlp 或者 hanlp、foolnltk 上去標(biāo)注一些語(yǔ)料。這些API和模型有的時(shí)候只提供了模型的預(yù)測(cè)結(jié)果,沒(méi)有提供訓(xùn)練的語(yǔ)料,但是我們可以拿這些別人訓(xùn)練好的模型去構(gòu)造語(yǔ)料。
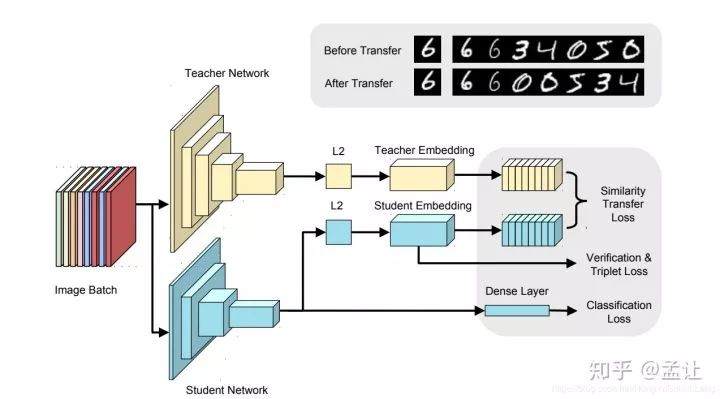
知識(shí)蒸餾
我們可以將別人訓(xùn)練的模型看做是Teacher, 然后用API標(biāo)注的語(yǔ)料自己訓(xùn)練的模型看做是Student, 雖然結(jié)果不能達(dá)到和原來(lái)模型一致的效果,但是也不至于差太多,這種方式在初期能夠幫助我們快速的推進(jìn)項(xiàng)目,看到項(xiàng)目的效果后,后期再想辦法優(yōu)化迭代
通過(guò)搜索引擎收集標(biāo)注數(shù)據(jù)
假設(shè)我們需要做一個(gè)NER模型,其中一類實(shí)體是人名,可能我們想到的是從網(wǎng)上下載一批新聞,然后標(biāo)出其中的人名,但是,這樣做有一個(gè)問(wèn)題,一篇幾千字的新聞往往只有幾個(gè)人名,而我們只需要出現(xiàn)了人名的那部分句子,并不需要其他部分。如果直接在整篇文本上標(biāo)注效率十分低。其實(shí),我們可以轉(zhuǎn)換一下思路,找一份中文人名詞庫(kù),然后放到百度中搜索,百度摘要返回的大部分結(jié)果基本是我們想要的語(yǔ)料,通過(guò)爬蟲把摘要爬下來(lái),自己再過(guò)濾下就好啦。這樣的做法相當(dāng)于,借助于一些過(guò)濾和排序算法,幫助我們快速找到待標(biāo)注的語(yǔ)料。
二次加工已有語(yǔ)料
有的時(shí)候,一些語(yǔ)料和我們的需要解決的任務(wù)相似,但又完全不一樣,這時(shí)候我們可以嘗試?yán)闷渌蝿?wù)的語(yǔ)料來(lái)構(gòu)建出想要的語(yǔ)料。就拿百度2019信息抽取比賽來(lái)說(shuō)吧,該比賽的任務(wù)是從
"text": "《逐風(fēng)行》是百度文學(xué)旗下縱橫中文網(wǎng)簽約作家清水秋風(fēng)創(chuàng)作的一部東方玄幻小說(shuō),小說(shuō)已于2014-04-28正式發(fā)布"
這樣的句子中抽出實(shí)體和關(guān)系三元組
"spo_list": [{"predicate": "連載網(wǎng)站", "object_type": "網(wǎng)站", "subject_type": "網(wǎng)絡(luò)小說(shuō)", "object": "縱橫中文網(wǎng)", "subject": "逐風(fēng)行"}, {"predicate": "作者", "object_type": "人物", "subject_type": "圖書作品", "object": "清水秋風(fēng)", "subject": "逐風(fēng)行"}]screenshot-lic2019-ccf-org-cn-kg-1574584084691
百度總共提供了大概17萬(wàn)的標(biāo)注數(shù)據(jù),而且數(shù)據(jù)標(biāo)注質(zhì)量頗高。訓(xùn)練數(shù)據(jù)被標(biāo)注為以下格式:
{"text": "《逐風(fēng)行》是百度文學(xué)旗下縱橫中文網(wǎng)簽約作家清水秋風(fēng)創(chuàng)作的一部東方玄幻小說(shuō),小說(shuō)已于2014-04-28正式發(fā)布", "spo_list": [{"predicate": "連載網(wǎng)站", "object_type": "網(wǎng)站", "subject_type": "網(wǎng)絡(luò)小說(shuō)", "object": "縱橫中文網(wǎng)", "subject": "逐風(fēng)行"}, {"predicate": "作者", "object_type": "人物", "subject_type": "圖書作品", "object": "清水秋風(fēng)", "subject": "逐風(fēng)行"}]
由該數(shù)據(jù)我們可以構(gòu)造什么數(shù)據(jù)呢?
命名實(shí)體識(shí)別語(yǔ)料
由于語(yǔ)料中的每個(gè)實(shí)體都標(biāo)注了實(shí)體類別,所以可以通過(guò)實(shí)體類別,構(gòu)造出命名實(shí)體識(shí)別任務(wù)的語(yǔ)料,這17萬(wàn)數(shù)據(jù)集,提供了國(guó)家、城市、影視作品、人物、地點(diǎn)、企業(yè)、圖書等10幾個(gè)類別的實(shí)體,這些語(yǔ)料加上人名日?qǐng)?bào)、msra、bosonnlp 公開(kāi)的NER語(yǔ)料,我們就可以擴(kuò)充一個(gè)更大的NER語(yǔ)料集;
開(kāi)放關(guān)系抽取語(yǔ)料
雖然該數(shù)據(jù)集是面向封閉域關(guān)系抽取的數(shù)據(jù)集,其實(shí)改造一下,也能用于句子級(jí)別的開(kāi)放域關(guān)系抽取任務(wù)中,比如我們可以構(gòu)建一個(gè)基于序列標(biāo)注的關(guān)系和實(shí)體聯(lián)合抽取模型,簡(jiǎn)單的說(shuō)就是給定(S,P,O)三元組和text,從中抽取一個(gè)代表關(guān)系的動(dòng)賓短語(yǔ)或名詞性短語(yǔ)來(lái)。比如從《逐風(fēng)行》是百度文學(xué)旗下縱橫中文網(wǎng)簽約作家清水秋風(fēng)創(chuàng)作的一部東方玄幻小說(shuō),小說(shuō)已于2014-04-28正式發(fā)這句話抽取(清水秋風(fēng),創(chuàng)作,《逐風(fēng)行》)這樣的關(guān)系三元組。當(dāng)然,要改造成適合開(kāi)放關(guān)系抽取的語(yǔ)料,還有一些工作需要做。比如原來(lái)語(yǔ)料中的S和O是我們要抽取的內(nèi)容,而P卻不是,因此,我們可能需要進(jìn)行二次標(biāo)注或者再構(gòu)建一個(gè)模型去預(yù)測(cè)出P。
很多公開(kāi)的語(yǔ)料都可以采用類似的做法,這里就拋磚引玉一下,不一一介紹了。
標(biāo)注工具
工欲善其事,必先利其器 ,標(biāo)注工具能夠大大提高標(biāo)注效率,標(biāo)注工具通過(guò)提供方便的快捷鍵和交互方式,讓我們?cè)谙嗤瑫r(shí)間,標(biāo)注更多的數(shù)據(jù)。同時(shí),還可以在標(biāo)注工具中嵌入一些AI輔助標(biāo)注的能力,實(shí)現(xiàn)機(jī)器自動(dòng)標(biāo)注,而我們只需要修改和刪除小部分的錯(cuò)誤標(biāo)注樣本,進(jìn)一步提高效率。

主動(dòng)學(xué)習(xí)標(biāo)注
在機(jī)器學(xué)習(xí)任務(wù)中,由于數(shù)據(jù)標(biāo)注代價(jià)高昂,如果能夠從任務(wù)出發(fā),通過(guò)對(duì)任務(wù)的理解來(lái)制定標(biāo)準(zhǔn),挑選最重要的樣本,使其最有助于模型的學(xué)習(xí)過(guò)程,將大大減少標(biāo)注的成本, 主動(dòng)學(xué)習(xí)就是解決這個(gè)問(wèn)題的。關(guān)于主動(dòng)學(xué)習(xí)背后的理論細(xì)節(jié),感興趣可以自行谷歌,這里舉一個(gè)通俗易懂的例子簡(jiǎn)要解釋一下。

可以
還記得支持向量機(jī)中的“支持向量”嗎?當(dāng)我們?cè)诜诸惖臅r(shí)候,并不是所有的點(diǎn)對(duì)于分割線的位置都是起決定性作用的。在離超平面特別遠(yuǎn)的區(qū)域,哪怕你增加10000個(gè)樣本點(diǎn),對(duì)于分割線的位置,也是沒(méi)有作用的,因?yàn)榉指罹€是由幾個(gè)關(guān)鍵點(diǎn)決定的(圖上三個(gè)),這幾個(gè)關(guān)鍵點(diǎn)支撐起了一個(gè)分割超平面,所以這些關(guān)鍵點(diǎn),就是支持向量。借鑒大數(shù)據(jù)標(biāo)注任務(wù)上,如果能夠準(zhǔn)確的標(biāo)出那些“重要”的樣本,就有可能實(shí)現(xiàn)“事半功倍”的效果。

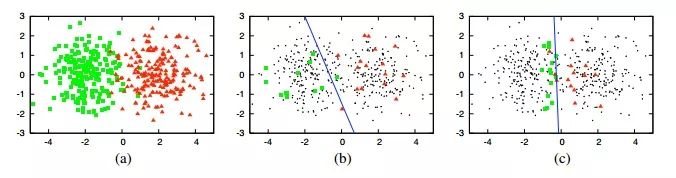
隨機(jī)標(biāo)注的結(jié)果可能是上圖中的b, 準(zhǔn)確率大約為70%。而右圖就是主動(dòng)學(xué)習(xí)方法找到的標(biāo)注點(diǎn),因?yàn)檫@些點(diǎn)幾乎構(gòu)成了完美分界線的邊界,所以使用與中圖同樣的樣本數(shù),但它能夠取得90%左右的準(zhǔn)確率!
弱監(jiān)督的數(shù)據(jù)標(biāo)注
監(jiān)督學(xué)習(xí)就是我們有一批高置信的標(biāo)注數(shù)據(jù),通過(guò)model來(lái)擬合效果。弱監(jiān)督學(xué)習(xí),就是我們很難獲取足夠量的高置信的標(biāo)注數(shù)據(jù),所以弱監(jiān)督學(xué)習(xí)就是來(lái)解決這個(gè)問(wèn)題。
這里為大家介紹一個(gè)斯坦福的研究者開(kāi)源的弱監(jiān)督學(xué)習(xí)通用框架 Snorkel ,由這種方法生成的標(biāo)簽可用于訓(xùn)練任意模型。已經(jīng)有人將Snorkel用于處理圖像數(shù)據(jù)、自然語(yǔ)言監(jiān)督、處理半結(jié)構(gòu)化數(shù)據(jù)、自動(dòng)生成訓(xùn)練集等具體用途。

Snorkel 集成了多種知識(shí)來(lái)源作為弱監(jiān)督,我們只需要在基于MapReduce模板的pipeline中編寫標(biāo)記函數(shù),每個(gè)標(biāo)記函數(shù)都接受一個(gè)數(shù)據(jù)點(diǎn)生成的概率標(biāo)簽,并選擇返回None(無(wú)標(biāo)簽)或輸出標(biāo)簽。在編寫標(biāo)記函數(shù)的時(shí)候,我們可以利用一切可以利用知識(shí)來(lái)標(biāo)記我們的數(shù)據(jù),這些知識(shí)可能包括,人工規(guī)則、知識(shí)圖譜、已有的模型、統(tǒng)計(jì)信息、網(wǎng)頁(yè)等。

如上圖所示,假設(shè)我們?cè)谧鯪ER任務(wù),需要標(biāo)注人名,可以用來(lái)構(gòu)建標(biāo)記函數(shù)的知識(shí)有:
文本是否在人名詞庫(kù)中
jieba、hanlp等NLP工具包給出的pos tag
文本是否是知識(shí)圖譜中的人物實(shí)體
基于以上知識(shí),我們就可以寫出多個(gè)標(biāo)記函數(shù)了。當(dāng)然,通過(guò) Snorkel 標(biāo)注的數(shù)據(jù)是有噪聲的,甚至很多標(biāo)記函數(shù)給出的結(jié)果互相沖突。這些我們完全不用擔(dān)心,因?yàn)镾norkel已經(jīng)提供了解決這些問(wèn)題的方法。
拿出項(xiàng)目的效果,向公司申請(qǐng)資源
最后的最后,我們可以想好算法的落地場(chǎng)景和價(jià)值,講好故事,向公司和老板的爭(zhēng)取資源!
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8441瀏覽量
133094 -
GitHub
+關(guān)注
關(guān)注
3文章
473瀏覽量
16566 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22111
原文標(biāo)題:一文詳解NLP語(yǔ)料構(gòu)建技巧
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛(ài)好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一些常見(jiàn)的動(dòng)態(tài)電路

分享一些常見(jiàn)的電路
LED驅(qū)動(dòng)器應(yīng)用的一些指南和技巧

nlp神經(jīng)語(yǔ)言和NLP自然語(yǔ)言的區(qū)別和聯(lián)系
nlp自然語(yǔ)言處理框架有哪些
nlp自然語(yǔ)言處理的主要任務(wù)及技術(shù)方法
如何為ESP8266構(gòu)建自定義盾牌?
nlp自然語(yǔ)言處理模型怎么做
nlp自然語(yǔ)言處理模型有哪些
nlp自然語(yǔ)言處理的應(yīng)用有哪些
深度學(xué)習(xí)與nlp的區(qū)別在哪
NLP技術(shù)在人工智能領(lǐng)域的重要性
什么是自然語(yǔ)言處理 (NLP)
細(xì)談SolidWorks教育版的一些基礎(chǔ)知識(shí)
關(guān)于智能門禁設(shè)備做CCC認(rèn)證申請(qǐng)的一些經(jīng)驗(yàn)分享






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論