 貝葉斯方法到貝葉斯網絡
貝葉斯方法到貝葉斯網絡
1、貝葉斯方法
長久以來,人們對一件事情發生或不發生的概率,只有固定的0和1,即要么發生,要么不發生,從來不會去考慮某件事情發生的概率有多大,不發生的概率又是多大。而且概率雖然未知,但最起碼是一個確定的值。比如如果問那時的人們一個問題:“有一個袋子,里面裝著若干個白球和黑球,請問從袋子中取得白球的概率是多少?”他們會想都不用想,會立馬告訴你,取出白球的概率就是1/2,要么取到白球,要么取不到白球,即θ只能有一個值,而且不論你取了多少次,取得白球的概率θ始終都是1/2,即不隨觀察結果X 的變化而變化。
這種頻率派的觀點長期統治著人們的觀念,直到后來一個名叫Thomas Bayes的人物出現。
1.1、貝葉斯方法的提出
托馬斯·貝葉斯Thomas Bayes(1702-1763)在世時,并不為當時的人們所熟知,很少發表論文或出版著作,與當時學術界的人溝通交流也很少,用現在的話來說,貝葉斯就是活生生一民間學術“屌絲”,可這個“屌絲”最終發表了一篇名為“An essay towards solving a problem in the doctrine of chances”,翻譯過來則是:機遇理論中一個問題的解。你可能覺得我要說:這篇論文的發表隨機產生轟動效應,從而奠定貝葉斯在學術史上的地位。
事實上,上篇論文發表后,在當時并未產生多少影響,在20世紀后,這篇論文才逐漸被人們所重視。對此,與梵高何其類似,畫的畫生前一文不值,死后價值連城。
回到上面的例子:“有一個袋子,里面裝著若干個白球和黑球,請問從袋子中取得白球的概率θ是多少?”貝葉斯認為取得白球的概率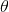 是個不確定的值,因為其中含有機遇的成分。比如,一個朋友創業,你明明知道創業的結果就兩種,即要么成功要么失敗,但你依然會忍不住去估計他創業成功的幾率有多大?你如果對他為人比較了解,而且有方法、思路清晰、有毅力、且能團結周圍的人,你會不由自主的估計他創業成功的幾率可能在80%以上。這種不同于最開始的“非黑即白、非0即1”的思考方式,便是貝葉斯式的思考方式。
是個不確定的值,因為其中含有機遇的成分。比如,一個朋友創業,你明明知道創業的結果就兩種,即要么成功要么失敗,但你依然會忍不住去估計他創業成功的幾率有多大?你如果對他為人比較了解,而且有方法、思路清晰、有毅力、且能團結周圍的人,你會不由自主的估計他創業成功的幾率可能在80%以上。這種不同于最開始的“非黑即白、非0即1”的思考方式,便是貝葉斯式的思考方式。
繼續深入講解貝葉斯方法之前,先簡單總結下頻率派與貝葉斯派各自不同的思考方式:
頻率派把需要推斷的參數θ看做是固定的未知常數,即概率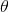 雖然是未知的,但最起碼是確定的一個值,同時,樣本X 是隨機的,所以頻率派重點研究樣本空間,大部分的概率計算都是針對樣本X 的分布;
雖然是未知的,但最起碼是確定的一個值,同時,樣本X 是隨機的,所以頻率派重點研究樣本空間,大部分的概率計算都是針對樣本X 的分布;
而貝葉斯派的觀點則截然相反,他們認為參數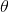 是隨機變量,而樣本X 是固定的,由于樣本是固定的,所以他們重點研究的是參數
是隨機變量,而樣本X 是固定的,由于樣本是固定的,所以他們重點研究的是參數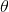 的分布。
的分布。
相對來說,頻率派的觀點容易理解,所以下文重點闡述貝葉斯派的觀點。
貝葉斯派既然把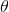 看做是一個隨機變量,所以要計算
看做是一個隨機變量,所以要計算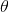 的分布,便得事先知道
的分布,便得事先知道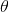 的無條件分布,即在有樣本之前(或觀察到X之前),
的無條件分布,即在有樣本之前(或觀察到X之前),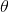 有著怎樣的分布呢?
有著怎樣的分布呢?
比如往臺球桌上扔一個球,這個球落會落在何處呢?如果是不偏不倚的把球拋出去,那么此球落在臺球桌上的任一位置都有著相同的機會,即球落在臺球桌上某一位置的概率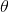 服從均勻分布。這種在實驗之前定下的屬于基本前提性質的分布稱為先驗分布,或
服從均勻分布。這種在實驗之前定下的屬于基本前提性質的分布稱為先驗分布,或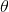 的無條件分布。
的無條件分布。
至此,貝葉斯及貝葉斯派提出了一個思考問題的固定模式:
先驗分布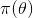 ?+ 樣本信息
?+ 樣本信息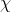
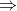 ?后驗分布
?后驗分布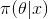
上述思考模式意味著,新觀察到的樣本信息將修正人們以前對事物的認知。換言之,在得到新的樣本信息之前,人們對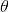 的認知是先驗分布
的認知是先驗分布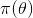 ,在得到新的樣本信息
,在得到新的樣本信息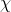 后,人們對
后,人們對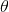 的認知為
的認知為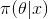 。
。
其中,先驗信息一般來源于經驗跟歷史資料。比如林丹跟某選手對決,解說一般會根據林丹歷次比賽的成績對此次比賽的勝負做個大致的判斷。再比如,某工廠每天都要對產品進行質檢,以評估產品的不合格率θ,經過一段時間后便會積累大量的歷史資料,這些歷史資料便是先驗知識,有了這些先驗知識,便在決定對一個產品是否需要每天質檢時便有了依據,如果以往的歷史資料顯示,某產品的不合格率只有0.01%,便可視為信得過產品或免檢產品,只每月抽檢一兩次,從而省去大量的人力物力。
而后驗分布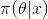 一般也認為是在給定樣本
一般也認為是在給定樣本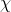 的情況下
的情況下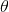 的條件分布,而使
的條件分布,而使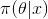 達到最大的值
達到最大的值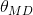 稱為最大后驗估計,類似于經典統計學中的極大似然估計。
稱為最大后驗估計,類似于經典統計學中的極大似然估計。
綜合起來看,則好比是人類剛開始時對大自然只有少得可憐的先驗知識,但隨著不斷是觀察、實驗獲得更多的樣本、結果,使得人們對自然界的規律摸得越來越透徹。所以,貝葉斯方法既符合人們日常生活的思考方式,也符合人們認識自然的規律,經過不斷的發展,最終占據統計學領域的半壁江山,與經典統計學分庭抗禮。
此外,貝葉斯除了提出上述思考模式之外,還特別提出了舉世聞名的貝葉斯定理。
1.2 、貝葉斯定理
在引出貝葉斯定理之前,先學習幾個定義:
條件概率(又稱后驗概率)就是事件A在另外一個事件B已經發生條件下的發生概率。條件概率表示為P(A|B),讀作“在B條件下A的概率”。
比如,在同一個樣本空間Ω中的事件或者子集A與B,如果隨機從Ω中選出的一個元素屬于B,那么這個隨機選擇的元素還屬于A的概率就定義為在B的前提下A的條件概率,所以:P(A|B)=|A∩B|/|B|,接著分子、分母都除以|Ω|得到
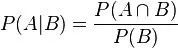
聯合概率表示兩個事件共同發生的概率。A與B的聯合概率表示為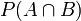 或者
或者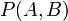 。
。
邊緣概率(又稱先驗概率)是某個事件發生的概率。邊緣概率是這樣得到的:在聯合概率中,把最終結果中那些不需要的事件通過合并成它們的全概率,而消去它們(對離散隨機變量用求和得全概率,對連續隨機變量用積分得全概率),這稱為邊緣化(marginalization),比如A的邊緣概率表示為P(A),B的邊緣概率表示為P(B)。
接著,考慮一個問題:P(A|B)是在B發生的情況下A發生的可能性。
1.首先,事件B發生之前,我們對事件A的發生有一個基本的概率判斷,稱為A的先驗概率,用P(A)表示;
2.其次,事件B發生之后,我們對事件A的發生概率重新評估,稱為A的后驗概率,用P(A|B)表示;
3.類似的,事件A發生之前,我們對事件B的發生有一個基本的概率判斷,稱為B的先驗概率,用P(B)表示;
4.同樣,事件A發生之后,我們對事件B的發生概率重新評估,稱為B的后驗概率,用P(B|A)表示。
貝葉斯定理便是基于下述貝葉斯公式:
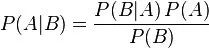
上述公式的推導其實非常簡單,就是從條件概率推出。
根據條件概率的定義,在事件B發生的條件下事件A發生的概率是
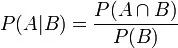
同樣地,在事件A發生的條件下事件B發生的概率
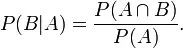
整理與合并上述兩個方程式,便可以得到:
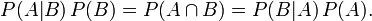
接著,上式兩邊同除以P(B),若P(B)是非零的,我們便可以得到貝葉斯定理的公式表達式:
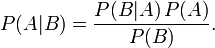
所以,貝葉斯公式可以直接根據條件概率的定義直接推出。即因為P(A,B) = P(A)P(B|A) = P(B)P(A|B),所以P(A|B) = P(A)P(B|A) / P(B)。
1.3 、應用:拼寫檢查
經常在網上搜索東西的朋友知道,當你不小心輸入一個不存在的單詞時,搜索引擎會提示你是不是要輸入某一個正確的單詞,比如當你在Google中輸入“Julw”時,系統會猜測你的意圖:是不是要搜索“July”,如下圖所示:
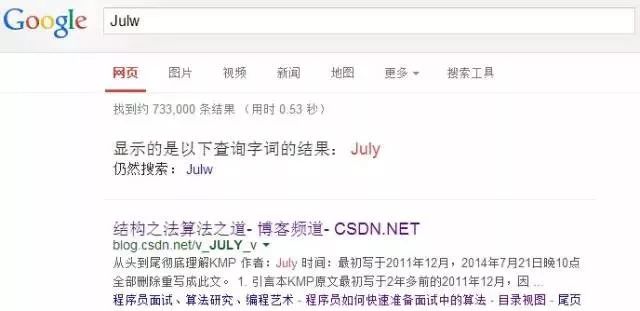
這叫做拼寫檢查。根據谷歌一員工寫的文章顯示,Google的拼寫檢查基于貝葉斯方法。下面我們就來看看,怎么利用貝葉斯方法,實現"拼寫檢查"的功能。
用戶輸入一個單詞時,可能拼寫正確,也可能拼寫錯誤。如果把拼寫正確的情況記做c(代表correct),拼寫錯誤的情況記做w(代表wrong),那么"拼寫檢查"要做的事情就是:在發生w的情況下,試圖推斷出c。換言之:已知w,然后在若干個備選方案中,找出可能性最大的那個c,也就是求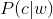 的最大值。? ? 而根據貝葉斯定理,有:
的最大值。? ? 而根據貝葉斯定理,有:
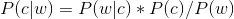
由于對于所有備選的c來說,對應的都是同一個w,所以它們的P(w)是相同的,因此我們只要最大化
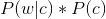
即可。其中:
P(c)表示某個正確的詞的出現"概率",它可以用"頻率"代替。如果我們有一個足夠大的文本庫,那么這個文本庫中每個單詞的出現頻率,就相當于它的發生概率。某個詞的出現頻率越高,P(c)就越大。比如在你輸入一個錯誤的詞“Julw”時,系統更傾向于去猜測你可能想輸入的詞是“July”,而不是“Jult”,因為“July”更常見。
P(w|c)表示在試圖拼寫c的情況下,出現拼寫錯誤w的概率。為了簡化問題,假定兩個單詞在字形上越接近,就有越可能拼錯,P(w|c)就越大。舉例來說,相差一個字母的拼法,就比相差兩個字母的拼法,發生概率更高。你想拼寫單詞July,那么錯誤拼成Julw(相差一個字母)的可能性,就比拼成Jullw高(相差兩個字母)。值得一提的是,一般把這種問題稱為“編輯距離”,參見博客中的這篇文章。
所以,我們比較所有拼寫相近的詞在文本庫中的出現頻率,再從中挑出出現頻率最高的一個,即是用戶最想輸入的那個詞。具體的計算過程及此方法的缺陷請參見這里。
2、 貝葉斯網絡
2.1、 貝葉斯網絡的定義
貝葉斯網絡(Bayesian network),又稱信念網絡(Belief Network),或有向無環圖模型(directed acyclic graphical model),是一種概率圖模型,于1985年由Judea Pearl首先提出。它是一種模擬人類推理過程中因果關系的不確定性處理模型,其網絡拓樸結構是一個有向無環圖(DAG)。
貝葉斯網絡的有向無環圖中的節點表示隨機變量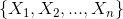 ,它們可以是可觀察到的變量,或隱變量、未知參數等。認為有因果關系(或非條件獨立)的變量或命題則用箭頭來連接。若兩個節點間以一個單箭頭連接在一起,表示其中一個節點是“因(parents)”,另一個是“果(children)”,兩節點就會產生一個條件概率值。
,它們可以是可觀察到的變量,或隱變量、未知參數等。認為有因果關系(或非條件獨立)的變量或命題則用箭頭來連接。若兩個節點間以一個單箭頭連接在一起,表示其中一個節點是“因(parents)”,另一個是“果(children)”,兩節點就會產生一個條件概率值。
總而言之,連接兩個節點的箭頭代表此兩個隨機變量是具有因果關系,或非條件獨立。
例如,假設節點E直接影響到節點H,即E→H,則用從E指向H的箭頭建立結點E到結點H的有向弧(E,H),權值(即連接強度)用條件概率P(H|E)來表示,如下圖所示:

簡言之,把某個研究系統中涉及的隨機變量,根據是否條件獨立繪制在一個有向圖中,就形成了貝葉斯網絡。其主要用來描述隨機變量之間的條件依賴,用圈表示隨機變量(random variables),用箭頭表示條件依賴(conditional dependencies)。
令G = (I,E)表示一個有向無環圖(DAG),其中I代表圖形中所有的節點的集合,而E代表有向連接線段的集合,且令X = (Xi)i ∈ I為其有向無環圖中的某一節點i所代表的隨機變量,若節點X的聯合概率可以表示成:
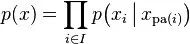
則稱X為相對于一有向無環圖G的貝葉斯網絡,其中,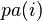 表示節點i之“因”,或稱pa(i)是i的parents(父母)。
表示節點i之“因”,或稱pa(i)是i的parents(父母)。
此外,對于任意的隨機變量,其聯合概率可由各自的局部條件概率分布相乘而得出:
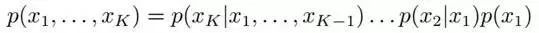
如下圖所示,便是一個簡單的貝葉斯網絡:
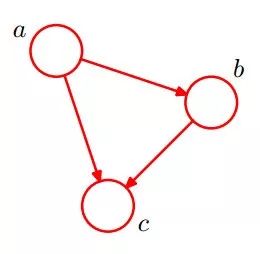
因為a導致b,a和b導致c,所以有
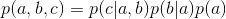
2.2、 貝葉斯網絡的3種結構形式
給定如下圖所示的一個貝葉斯網絡:
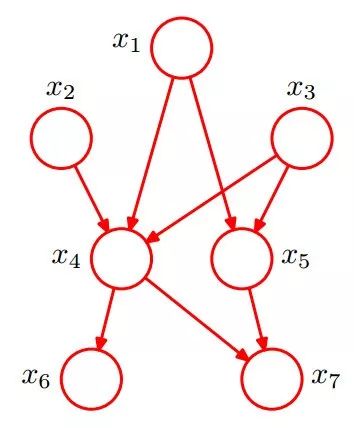
從圖上可以比較直觀的看出:
1. x1,x2,…x7的聯合分布為
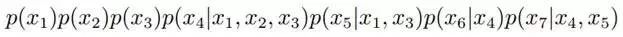
2. x1和x2獨立(對應head-to-head);
3. x6和x7在x4給定的條件下獨立(對應tail-to-tail)。
根據上圖,第1點可能很容易理解,但第2、3點中所述的條件獨立是啥意思呢?其實第2、3點是貝葉斯網絡中3種結構形式中的其中二種。為了說清楚這個問題,需要引入D-Separation(D-分離)這個概念。
D-Separation是一種用來判斷變量是否條件獨立的圖形化方法。換言之,對于一個DAG(有向無環圖)E,D-Separation方法可以快速的判斷出兩個節點之間是否是條件獨立的。
2.2.1 形式1:head-to-head
貝葉斯網絡的第一種結構形式如下圖所示:
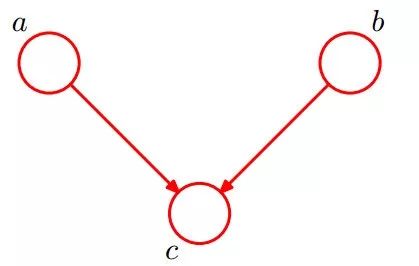
所以有:P(a,b,c) = P(a)*P(b)*P(c|a,b)成立,化簡后可得:
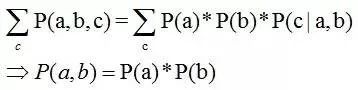
即在c未知的條件下,a、b被阻斷(blocked),是獨立的,稱之為head-to-head條件獨立,對應本節中最開始那張圖中的“x1、x2獨立”。
2.2.2 形式2:tail-to-tail
貝葉斯網絡的第二種結構形式如下圖所示
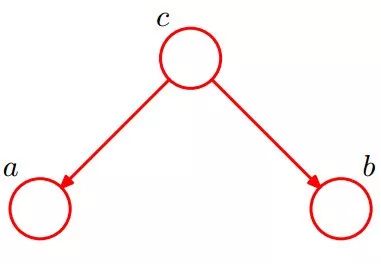
考慮c未知,跟c已知這兩種情況:
1.在c未知的時候,有:P(a,b,c)=P(c)*P(a|c)*P(b|c),此時,沒法得出P(a,b) = P(a)P(b),即c未知時,a、b不獨立。
2.在c已知的時候,有:P(a,b|c)=P(a,b,c)/P(c),然后將P(a,b,c)=P(c)*P(a|c)*P(b|c)帶入式子中,得到:P(a,b|c)=P(a,b,c)/P(c) = P(c)*P(a|c)*P(b|c) / P(c) = P(a|c)*P(b|c),即c已知時,a、b獨立。
所以,在c給定的條件下,a,b被阻斷(blocked),是獨立的,稱之為tail-to-tail條件獨立,對應本節中最開始那張圖中的“x6和x7在x4給定的條件下獨立”。
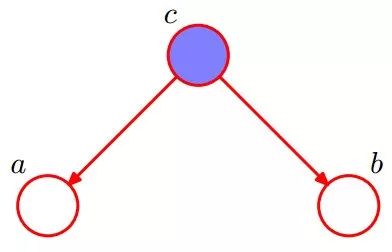
2.2.3 形式3:head-to-tail
貝葉斯網絡的第三種結構形式如下圖所示:
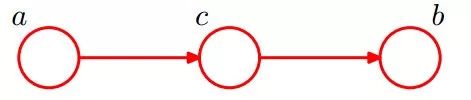
還是分c未知跟c已知這兩種情況:
1.c未知時,有:P(a,b,c)=P(a)*P(c|a)*P(b|c),但無法推出P(a,b) = P(a)P(b),即c未知時,a、b不獨立。
2.c已知時,有:P(a,b|c)=P(a,b,c)/P(c),且根據P(a,c) = P(a)*P(c|a) = P(c)*P(a|c),可化簡得到:
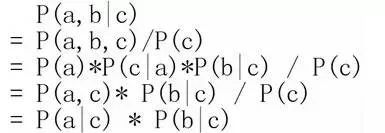
所以,在c給定的條件下,a,b被阻斷(blocked),是獨立的,稱之為head-to-tail條件獨立。
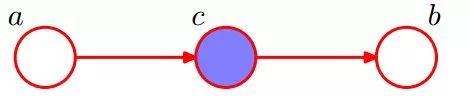
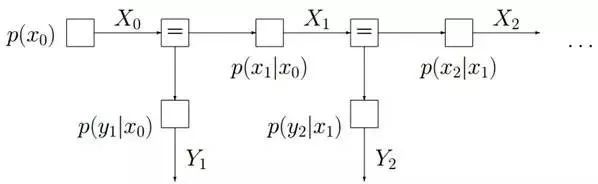
插一句:這個head-to-tail其實就是一個鏈式網絡,如下圖所示:

根據之前對head-to-tail的講解,我們已經知道,在xi給定的條件下,xi+1的分布和x1,x2…xi-1條件獨立。意味著啥呢?意味著:xi+1的分布狀態只和xi有關,和其他變量條件獨立。通俗點說,當前狀態只跟上一狀態有關,跟上上或上上之前的狀態無關。這種順次演變的隨機過程,就叫做馬爾科夫鏈(Markov chain)。且有:
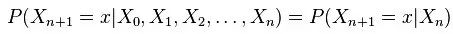
接著,將上述結點推廣到結點集,則是:對于任意的結點集A,B,C,考察所有通過A中任意結點到B中任意結點的路徑,若要求A,B條件獨立,則需要所有的路徑都被阻斷(blocked),即滿足下列兩個前提之一:
1.A和B的“head-to-tail型”和“tail-to-tail型”路徑都通過C;
2.A和B的“head-to-head型”路徑不通過C以及C的子孫;
最后,舉例說明上述D-Separation的3種情況(即貝葉斯網絡的3種結構形式),則是如下圖所示:
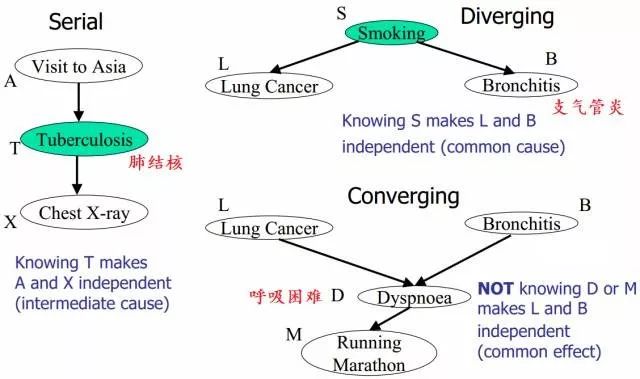
上圖中左邊部分是head-to-tail,給定 T 時,A 和 X 獨立;右邊部分的右上角是tail-to-tail,給定S時,L和B獨立;右邊部分的右下角是head-to-head,未給定D時,L和B獨立。
2.3 貝葉斯網絡的實例
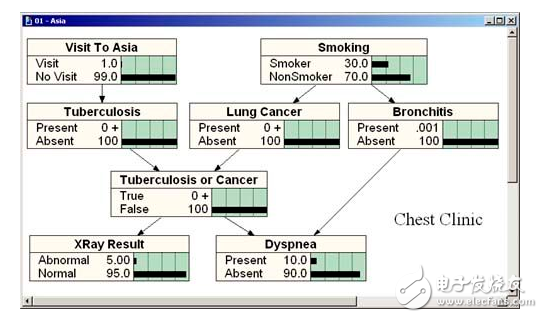
給定如下圖所示的貝葉斯網絡:
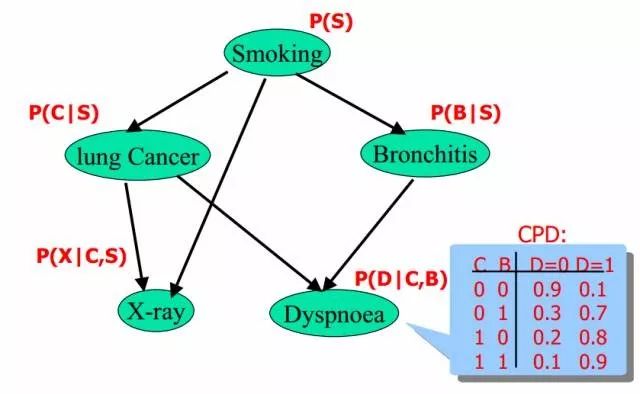
其中,各個單詞、表達式表示的含義如下:
smoking表示吸煙,其概率用P(S)表示,lung Cancer表示的肺癌,一個人在吸煙的情況下得肺癌的概率用P(C|S)表示,X-ray表示需要照醫學上的X光,肺癌可能會導致需要照X光,吸煙也有可能會導致需要照X光(所以smoking也是X-ray的一個因),所以,因吸煙且得肺癌而需要照X光的概率用P(X|C,S)表示。
Bronchitis表示支氣管炎,一個人在吸煙的情況下得支氣管炎的概率用P(B|S),dyspnoea表示呼吸困難,支氣管炎可能會導致呼吸困難,肺癌也有可能會導致呼吸困難(所以lung Cancer也是dyspnoea的一個因),因吸煙且得了支氣管炎導致呼吸困難的概率用P(D|C,B)表示。
lung Cancer簡記為C,Bronchitis簡記為B,dyspnoea簡記為D,且C = 0表示lung Cancer不發生的概率,C = 1表示lung Cancer發生的概率,B等于0(B不發生)或1(B發生)也類似于C,同樣的,D=1表示D發生的概率,D=0表示D不發生的概率,便可得到dyspnoea的一張概率表,如上圖的最右下角所示。
2.4、 因子圖
回到2.3節中那個實例上,如下圖所示:
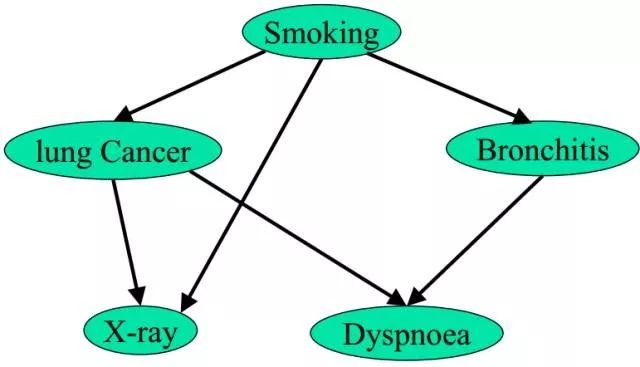
對于上圖,在一個人已經呼吸困難(dyspnoea)的情況下,其抽煙(smoking)的概率是多少呢?即:

咱們來一步步計算推導下:

解釋下上述式子推導過程:
1.第二行:對聯合概率關于b,x,c求和(在d=1的條件下),從而消去b,x,c,得到s和d=1的聯合概率。
2.第三行:最開始,所有變量都在sigma(d=1,b,x,c)的后面(sigma表示對“求和”的稱謂),但由于P(s)和“d=1,b,x,c”都沒關系,所以,可以提到式子的最前面。而且P(b|s)和x、c沒關系,所以,也可以把它提出來,放到sigma(b)的后面,從而式子的右邊剩下sigma(x)和sigma(c)。
此外,圖中Variable elimination表示的是變量消除的意思。為了更好的解決此類問題,咱們得引入因子圖的概念。
2.4.1 因子圖的定義
wikipedia上是這樣定義因子圖的:將一個具有多變量的全局函數因子分解,得到幾個局部函數的乘積,以此為基礎得到的一個雙向圖叫做因子圖(Factor Graph)。
比如,假定對于函數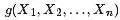 ,有下述式子成立:
,有下述式子成立:
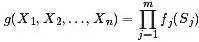
其中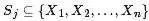 ,其對應的因子圖
,其對應的因子圖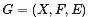 包括:
包括:
1.變量節點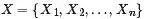
2. 因子(函數)節點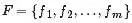
3.邊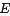 ,邊通過下列因式分解結果得到:在因子(函數)節點
,邊通過下列因式分解結果得到:在因子(函數)節點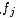 和變量節點
和變量節點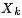 之間存在邊的充要條件是
之間存在邊的充要條件是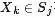 存在。
存在。
正式的定義果然晦澀!我相信你沒看懂。通俗來講,所謂因子圖就是對函數進行因子分解得到的一種概率圖。一般內含兩種節點:變量節點和函數節點。我們知道,一個全局函數通過因式分解能夠分解為多個局部函數的乘積,這些局部函數和對應的變量關系就體現在因子圖上。
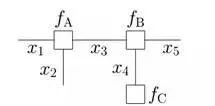
舉個例子,現在有一個全局函數,其因式分解方程為:
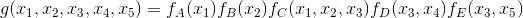
其中fA,fB,fC,fD,fE為各函數,表示變量之間的關系,可以是條件概率也可以是其他關系(如馬爾可夫隨機場Markov Random Fields中的勢函數)。
為了方便表示,可以寫成:
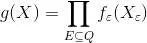
其對應的因子圖為:
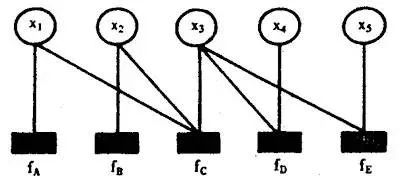
且上述因子圖等價于:
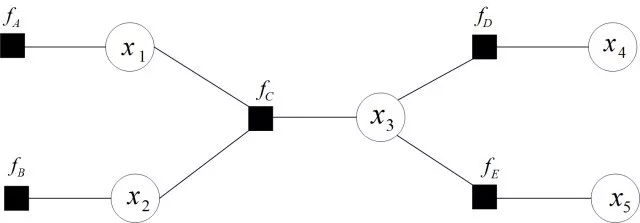
所以,在因子圖中,所有的頂點不是變量節點就是函數節點,邊線表示它們之間的函數關系。
但搞了半天,雖然知道了什么是因子圖,但因子圖到底是干嘛的呢?為何要引入因子圖,其用途和意義何在?事實上,因子圖跟貝葉斯網絡和馬爾科夫隨機場(Markov Random Fields)一樣,也是概率圖的一種。
既然提到了馬爾科夫隨機場,那順便說下有向圖、無向圖,以及條件隨機場等相關概念。
我們已經知道,有向圖模型,又稱作貝葉斯網絡(Directed Graphical Models, DGM, Bayesian Network)。
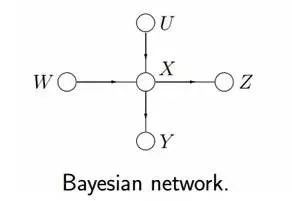
但在有些情況下,強制對某些結點之間的邊增加方向是不合適的。使用沒有方向的無向邊,形成了無向圖模型(Undirected Graphical Model,UGM), 又被稱為馬爾科夫隨機場或者馬爾科夫網絡(Markov Random Field, MRF or Markov network)。
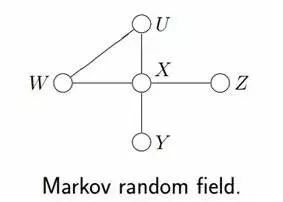
設X=(X1,X2…Xn)和Y=(Y1,Y2…Ym)都是聯合隨機變量,若隨機變量Y構成一個無向圖 G=(V,E)表示的馬爾科夫隨機場(MRF),則條件概率分布P(Y|X)稱為條件隨機場(Conditional Random Field, 簡稱CRF,后續新的博客中可能會闡述CRF)。如下圖所示,便是一個線性鏈條件隨機場的無向圖模型:
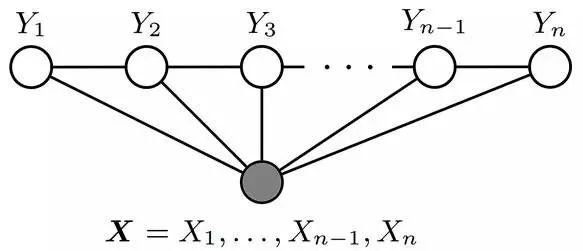
回到本文的主旨上來。在概率圖中,求某個變量的邊緣分布是常見的問題。這問題有很多求解方法,其中之一就是把貝葉斯網絡或馬爾科夫隨機場轉換成因子圖,然后用sum-product算法求解。換言之,基于因子圖可以用sum-product 算法高效的求各個變量的邊緣分布。
先通過一些例子分別說明如何把貝葉斯網絡(和馬爾科夫隨機場),以及把馬爾科夫鏈、隱馬爾科夫模型轉換成因子圖后的情形,然后在2.4.2節,咱們再來看如何利用因子圖的sum-product算法求邊緣概率分布。
給定下圖所示的貝葉斯網絡或馬爾科夫隨機場:
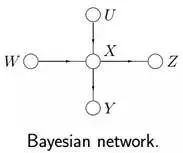
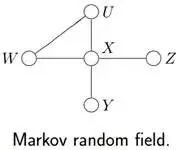
根據各個變量對應的關系,可得:
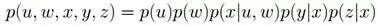
其對應的因子圖為(以下兩種因子圖的表示方式皆可):
由上述例子總結出由貝葉斯網絡構造因子圖的方法:
貝葉斯網絡中的一個因子對應因子圖中的一個結點
貝葉斯網絡中的每一個變量在因子圖上對應邊或者半邊
結點g和邊x相連當且僅當變量x出現在因子g中。
再比如,對于下圖所示的由馬爾科夫鏈轉換而成的因子圖:
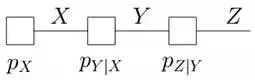
有:
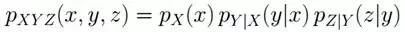
而對于如下圖所示的由隱馬爾科夫模型轉換而成的因子圖:
有:
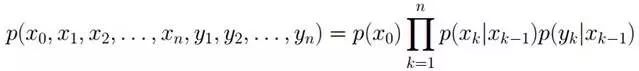
2.4.2 Sum-product算法
我們已經知道,對于下圖所示的因子圖:
有:
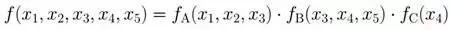
下面,咱們來考慮一個問題:即如何由聯合概率分布求邊緣概率分布。
首先回顧下聯合概率和邊緣概率的定義,如下:
聯合概率表示兩個事件共同發生的概率。A與B的聯合概率表示為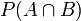 或者
或者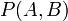 。
。
邊緣概率(又稱先驗概率)是某個事件發生的概率。邊緣概率是這樣得到的:在聯合概率中,把最終結果中不需要的那些事件合并成其事件的全概率而消失(對離散隨機變量用求和得全概率,對連續隨機變量用積分得全概率)。這稱為邊緣化(marginalization)。A的邊緣概率表示為P(A),B的邊緣概率表示為P(B)。
事實上,某個隨機變量fk的邊緣概率可由x1,x2,x3, ..., xn的聯合概率求到,具體公式為:
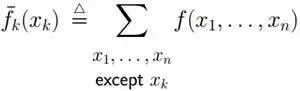
啊哈,啥原理呢?原理很簡單,還是它:對x3外的其它變量的概率求和,最終剩下x3的概率!
此外,換言之,如果有
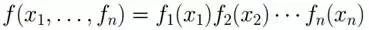
那么
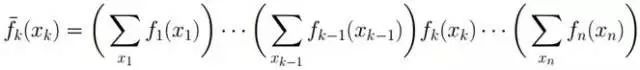
上述式子如何進一步化簡計算呢?考慮到我們小學所學到的乘法分配率,可知a*b + a*c = a*(b + c),前者2次乘法1次加法,后者1次乘法,1次加法。我們這里的計算是否能借鑒到分配率呢?別急,且聽下文慢慢道來。
假定現在我們需要計算計算如下式子的結果:
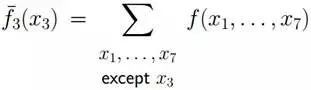
同時,f 能被分解如下:
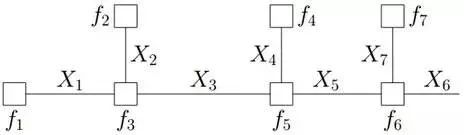
借鑒分配率,我們可以提取公因子:
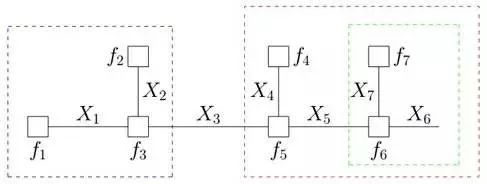
因為變量的邊緣概率等于所有與他相連的函數傳遞過來的消息的積,所以計算得到:
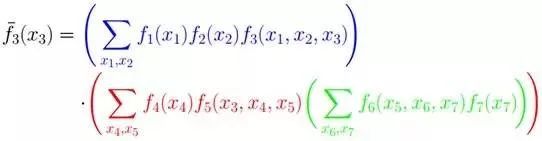
仔細觀察上述計算過程,可以發現,其中用到了類似“消息傳遞”的觀點,且總共兩個步驟。
第一步、對于f 的分解圖,根據藍色虛線框、紅色虛線框圍住的兩個box外面的消息傳遞:
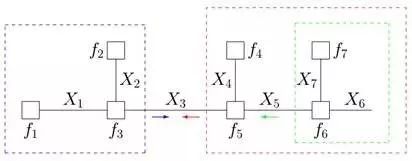
計算可得:

第二步、根據藍色虛線框、紅色虛線框圍住的兩個box內部的消息傳遞:
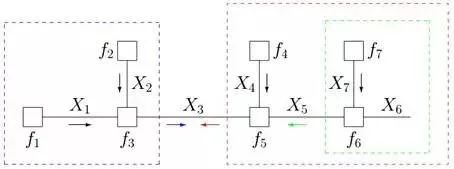
根據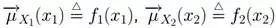 ,我們有:
,我們有:
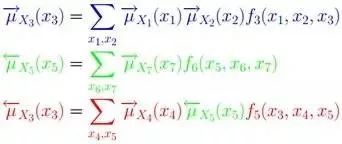
就這樣,上述計算過程將一個概率分布寫成兩個因子的乘積,而這兩個因子可以繼續分解或者通過已知得到。這種利用消息傳遞的觀念計算概率的方法便是sum-product算法。前面說過,基于因子圖可以用sum-product算法可以高效的求各個變量的邊緣分布。
到底什么是sum-product算法呢?sum-product算法,也叫belief propagation,有兩種消息:
一種是變量(Variable)到函數(Function)的消息: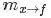 ,如下圖所示
,如下圖所示

此時,變量到函數的消息為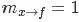 。
。
另外一種是函數(Function)到變量(Variable)的消息: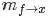 。如下圖所示:
。如下圖所示:

此時,函數到變量的消息為: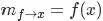 。
。
以下是sum-product算法的總體框架:
1、給定如下圖所示的因子圖:
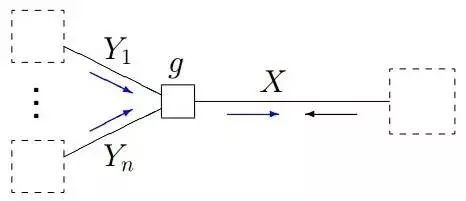
2、sum-product 算法的消息計算規則為:
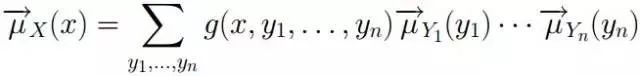
3、根據sum-product定理,如果因子圖中的函數f 沒有周期,則有:
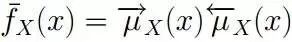
值得一提的是:如果因子圖是無環的,則一定可以準確的求出任意一個變量的邊緣分布,如果是有環的,則無法用sum-product算法準確求出來邊緣分布。
比如,下圖所示的貝葉斯網絡:
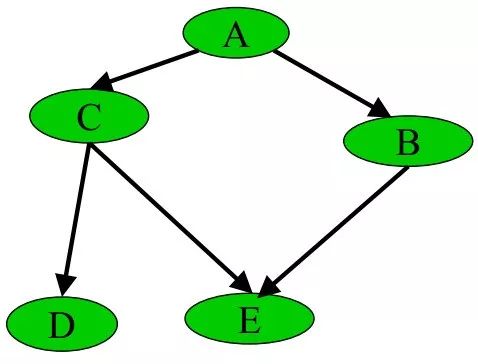
其轉換成因子圖后,為:
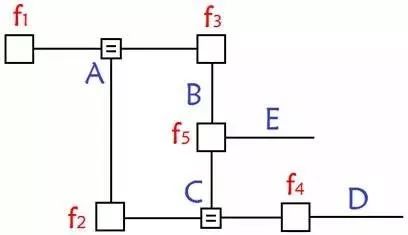
可以發現,若貝葉斯網絡中存在“環”(無向),則因此構造的因子圖會得到環。而使用消息傳遞的思想,這個消息將無限傳輸下去,不利于概率計算。 解決方法有3個:
1、刪除貝葉斯網絡中的若干條邊,使得它不含有無向環
比如給定下圖中左邊部分所示的原貝葉斯網絡,可以通過去掉C和E之間的邊,使得它重新變成有向無環圖,從而成為圖中右邊部分的近似樹結構:
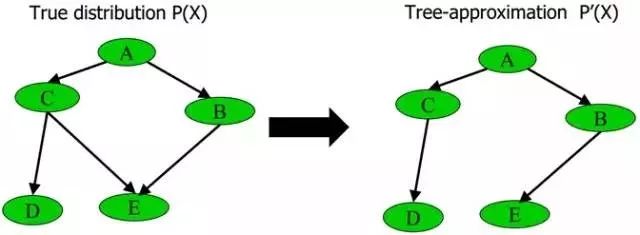
具體變換的過程為最大權生成樹算法MSWT(詳細建立過程請參閱此PPT 第60頁),通過此算法,這課樹的近似聯合概率P'(x)和原貝葉斯網絡的聯合概率P(x)的相對熵(如果忘了什么叫相對熵,請參閱:最大熵模型中的數學推導)最小。
2、重新構造沒有環的貝葉斯網絡
3、選擇loopy belief propagation算法(你可以簡單理解為sum-product 算法的遞歸版本),此算法一般選擇環中的某個消息,隨機賦個初值,然后用sum-product算法,迭代下去,因為有環,一定會到達剛才賦初值的那個消息,然后更新那個消息,繼續迭代,直到沒有消息再改變為止。唯一的缺點是不確保收斂,當然,此算法在絕大多數情況下是收斂的。
此外,除了這個sum-product算法,還有一個max-product 算法。但只要弄懂了sum-product,也就弄懂了max-product 算法。因為max-product 算法就在上面sum-product 算法的基礎上把求和符號換成求最大值max的符號即可!
-
網絡
+關注
關注
14文章
7599瀏覽量
89249 -
定理
+關注
關注
0文章
7瀏覽量
7724
原文標題:從貝葉斯方法談到貝葉斯網絡
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于貝葉斯網絡的軟件項目風險評估模型
基于概率的常見的分類方法--樸素貝葉斯






 工商網監
工商網監
評論