大數據查詢性能比較
大小:0.9 MB 人氣: 2017-09-30 需要積分:1
我們看看小P在實時數據計算方面又有哪些卓越表現呢?
由于 Presto 卓越的性能表現,使得 Presto 可以彌補 Hive 無法滿足的實時計算空白,因此可以將 Presto 與 Hive 配合使用:對于海量數據的批處理和計算由 Hive 來完成;對于大量數據(單次計算掃描數據量級在 GB 到 TB)的計算由 Presto 完成。 Presto 能夠完成的實時計算實際上分為以下兩種情況。
1. 快照數據實時計算
在這種情況下,可以基于某個時間點的快照數據進行計算,但是要求計算過程快速完成( 200ms~20min)。
2. 完全實時計算
要完成完全實時計算,需要滿足以下兩個條件。
( 1)使用的基準數據要實時更新,時刻保持與線上實際數據庫中的數據完全一致。
( 2)計算過程要能夠快速完成。
在某公司的實際使用場景中, Presto 被用于下述兩種業務場景中。
基于 T+1 數據的實時計算
在這種業務場景中,用戶并不要求基準數據的實時更新,但是要求每次查詢數據都能夠快速響應。需要 Presto 和 Hive 配合使用來滿足實際的業務需求。每天凌晨通過azkaban 調度 Hive 腳本,根據前一天的數據計算生成中間結果表,生成完畢之后使用 Presto 查詢中間結果表,得出用戶最終所需要的數據。滿足該業務場景的解決方案如圖

基于 RDBMS 的實時計算
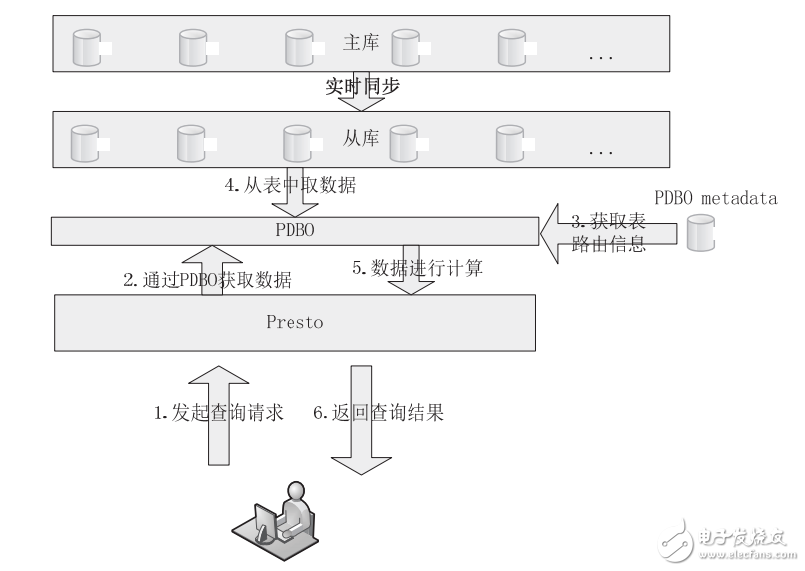
在這種業務場景中,用戶要求查詢的數據完全實時,即只要業務庫中的數據發生改變,通過 Presto 查詢的時候,就可以查詢到剛剛改變之后的數據。要達到這個效果,我們需要使用合理的機制保證數據實時同步,因此我們使用數據庫復制技術,為線上的業務數據庫建立實時同步的從庫,然后用 Presto 查詢數據庫中的數據,進而進行計算(請注意:使用官方的 Presto 直接讀取數據庫的性能還太低,因此建議使用JD-Presto 中的 PDBO 從數據庫中讀取數據并進行計算)。滿足該業務場景的解決方案如圖
二、Ad-Hoc 查詢
Ad-hoc 查詢就是即席查詢,即席查詢允許用戶根據自己的需求隨時調整和選擇查詢條件,計算平臺或者系統能夠根據用戶的查詢條件返回查詢結果或者生成相應的報表。由此可見,即席查詢和普通應用查詢的最大不同是:普通的應用查詢是定制開發的,其查詢語句是固定或者限制在一定的變動范圍之內的;而即席查詢允許用戶隨意指定或者改變查詢語句或者查詢條件。由于普通的應用查詢都是定制開發的,其查詢語句幾乎是固定的,因此,在系統實施時就可以通過建立索引或者分區等技術來優化這些查詢,從而提高查詢效率。但是即席查詢是用戶在使用時臨時產生的、系統無法預知的,因此也無法對這些查詢進行有針對性的優化和改進。
某公司使用 Presto 完成 Ad-Hoc 查詢,實際的 Ad-Hoc 使用場景包括以下兩種。
( 1)使用 BI 工具進行報表展現
BI 工具通過 ODBC 驅動連接至 Presto 集群, BI 工程師使用 BI 工具進行不同維度的報表設計和展現。由于目前 Facebook 提供的 ODBC 驅動是使用 D 語言開發的,而且功能尚不完善,因此采用 Treasure Data 提供的基于 Presto-gres 中的 ODBC 驅動改造之后的 ODBC 驅動連接到 Presto 集群。
( 2)使用 Cli 客戶端進行數據分析
Presto 使用 Hive 作為數據源,對 Hive 中的數據進行查詢和分析。眾所周知, Hive使用 Map-Reduce 框架進行計算,由于 Map-Reduce 的優勢在于進行大數據量的批運算和提供強大的集群計算吞吐量,但是對稍小數據量的計算和分析會花費相當長的時間,因此在進行 GB~TB 級別數據量的計算和分析時, Hive 并不能滿足實時性要求。
Presto 是專門針對基于 Ad-Hoc 的實時查詢和計算進行設計的, 其平均性能Hive的 10 倍,因此 Presto 更適合于稍小數據量的計算和差異性分析等 Ad-Hoc 查詢。
三、實時數據流分析
實時數據流分析主要是指通過 presto-kafka 使用 SQL 語句對 Kafka 中的數據流進行清洗、分析和計算。其在實際使用過程中有以下兩種使用場景。
( 1)保留歷史數據
在這種使用場景下, 由于 Presto 每次對 Kafka 中的數據進行分析時都需要從 Kafka 集群中將所有的數據都讀取出來, 然后在 Presto 集群的內存中進行過濾、分析等操作, 若在 Kafka中保留了大量的歷史數據, 那么通過 presto-kafka 使用 SQL 語句對 Kafka 中的數據進行分析就會在數據傳輸上花費大量的時間,從而導致查詢效率的降低。因此我們應該避免在 Kafka中存儲大量的數據,從而提高查詢性能。
非常好我支持^.^
(180) 97.3%
不好我反對
(5) 2.7%
下載地址
大數據查詢性能比較下載
相關電子資料下載
- R課堂 | 600V耐壓Super Junction MOSFET PrestoMOS?產品陣容又增新品 214
- 虹科方案 | 虹科HiveMQ與MQTT:構建互聯汽車的新架構 190
- 虹科案例 | 虹科HiveMQ支持平板電腦實現高效遠程管理 160
- 虹科案例 | 虹科HiveMQ助力采埃孚推進零愿景戰略 180
- 虹科案例 | 虹科HiveMQ助力實現百萬輛汽車智能互聯 182
- 虹科案例 | 虹科HiveMQ解決方案在奔馳汽車制造中的應用 244
- 虹科案例 | IAV 應用 HiveMQ 與汽車數據搭建城市山洪預警系統 248
- 虹科案例 | HiveMQ助力AGV小車與控制系統之間實現通信 180
- HiveMQ助力AGV小車與控制系統之間實現通信 316
- 虹科案例 | 寶馬汽車共享應用程序依賴強大的HiveMQ實現可靠連接 119